 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data is an Elegant GIFT for Continual Vision-Language Models
Mar 06, 2025Pre-trained Vision-Language Models (VLMs) require Continual Learning (CL) to efficiently update their knowledge and adapt to various downstream tasks without retraining from scratch. However, for VLMs, in addition to the loss of knowledge previously learned from downstream tasks, pre-training knowledge is also corrupted during continual fine-tuning. This issue is exacerbated by the unavailability of original pre-training data, leaving VLM's generalization ability degrading. In this paper, we propose GIFT, a novel continual fine-tuning approach that utilizes synthetic data to overcome catastrophic forgetting in VLMs. Taking advantage of recent advances in text-to-image synthesis, we employ a pre-trained diffusion model to recreate both pre-training and learned downstream task data. In this way, the VLM can revisit previous knowledge through distillation on matching diffusion-generated images and corresponding text prompts. Leveraging the broad distribution and high alignment between synthetic image-text pairs in VLM's feature space, we propose a contrastive distillation loss along with an image-text alignment constraint. To further combat in-distribution overfitting and enhance distillation performance with limited amount of generated data, we incorporate adaptive weight consolidation, utilizing Fisher information from these synthetic image-text pairs and achieving a better stability-plasticity balance. Extensive experiments demonstrate that our method consistently outperforms previous state-of-the-art approaches across various settings.
Symmetric Uncertainty-Aware Feature Transmission for Depth Super-Resolution
Jun 01, 2023


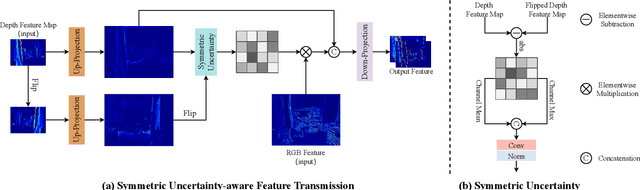
Color-guided depth super-resolution (DSR) is an encouraging paradigm that enhances a low-resolution (LR) depth map guided by an extra high-resolution (HR) RGB image from the same scene. Existing methods usually use interpolation to upscale the depth maps before feeding them into the network and transfer the high-frequency information extracted from HR RGB images to guide the reconstruction of depth maps. However, the extracted high-frequency information usually contains textures that are not present in depth maps in the existence of the cross-modality gap, and the noises would be further aggravated by interpolation due to the resolution gap between the RGB and depth images. To tackle these challenges, we propose a novel Symmetric Uncertainty-aware Feature Transmission (SUFT) for color-guided DSR. (1) For the resolution gap, SUFT builds an iterative up-and-down sampling pipeline, which makes depth features and RGB features spatially consistent while suppressing noise amplification and blurring by replacing common interpolated pre-upsampling. (2) For the cross-modality gap, we propose a novel Symmetric Uncertainty scheme to remove parts of RGB information harmful to the recovery of HR depth maps. Extensive experiments on benchmark datasets and challenging real-world settings suggest that our method achieves superior performance compared to state-of-the-art methods. Our code and models are available at https://github.com/ShiWuxuan/SUFT.