 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MATLAB Toolbox SciXMiner: User's Manual and Programmer's Guide
Apr 11, 2017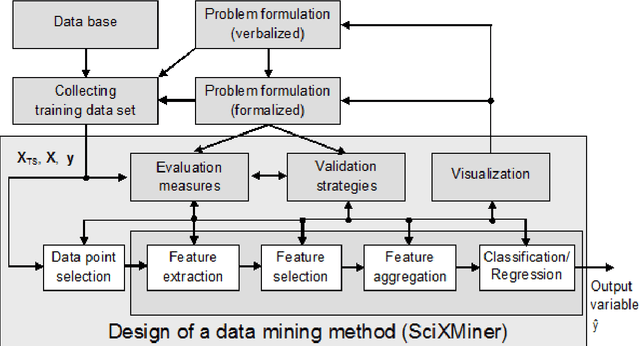
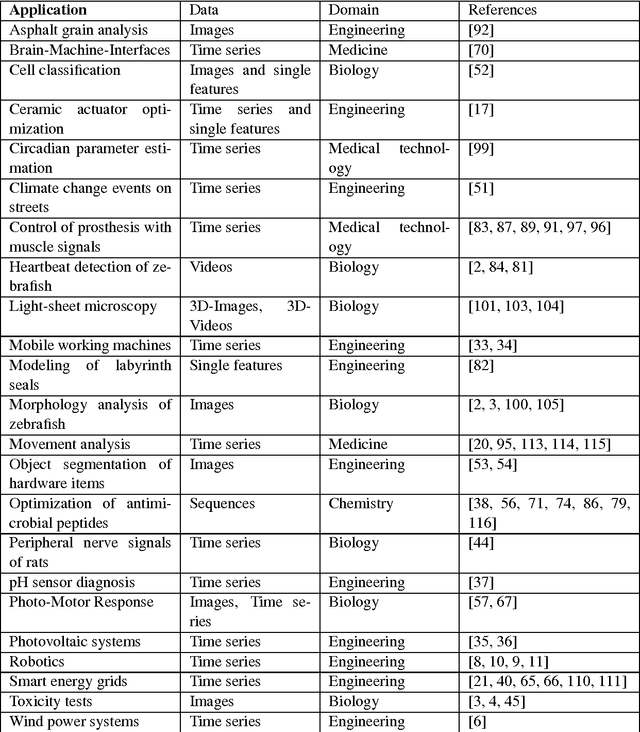
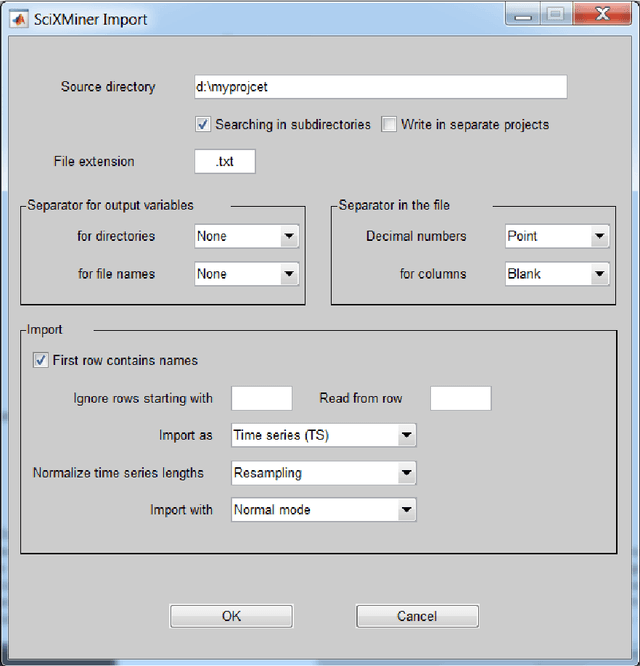
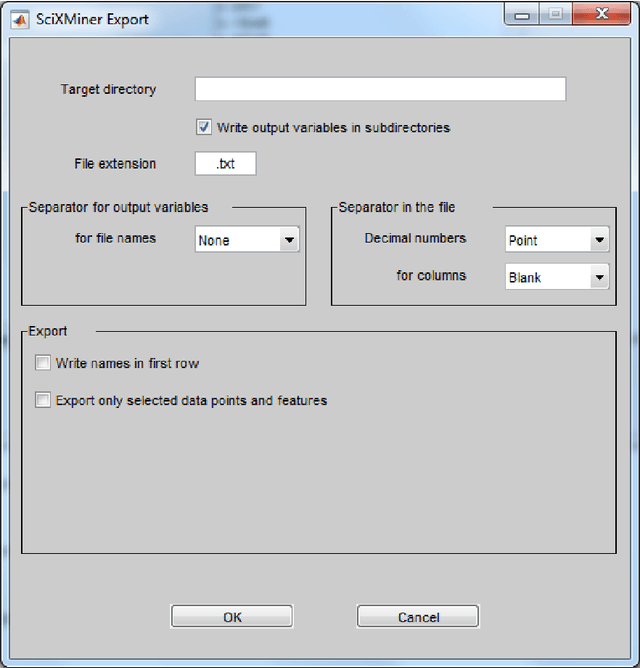
The Matlab toolbox SciXMiner is designed for the visualization and analysis of time series and features with a special focus to classification problems. It was developed at the Institute of Applied Computer Science of the Karlsruhe Institute of Technology (KIT), a member of the Helmholtz Association of German Research Centres in Germany. The aim was to provide an open platform for the development and improvement of data mining methods and its applications to various medical and technical problems. SciXMiner bases on Matlab (tested for the version 2017a). Many functions do not require additional standard toolboxes but some parts of Signal, Statistics and Wavelet toolboxes are used for special cases. The decision to a Matlab-based solution was made to use the wide mathematical functionality of this package provided by The Mathworks Inc. SciXMiner is controlled by a graphical user interface (GUI) with menu items and control elements like popup lists, checkboxes and edit elements. This makes it easier to work with SciXMiner for inexperienced users. Furthermore, an automatization and batch standardization of analyzes is possible using macros. The standard Matlab style using the command line is also available. SciXMiner is an open source software. The download page is http://sourceforge.net/projects/SciXMiner. It is licensed under the conditions of the GNU General Public License (GNU-GPL) of The Free Software Foundation.
Datenqualität in Regressionsproblemen
Jan 16, 2017Regression models are increasingly built using datasets which do not follow a design of experiment. Instead, the data is e.g. gathered by an automated monitoring of a technical system. As a consequence, already the input data represents phenomena of the system and violates statistical assumptions of distributions. The input data can show correlations, clusters or other patterns. Further, the distribution of input data influences the reliability of regression models. We propose criteria to quantify typical phenomena of input data for regression and show their suitability with simulated benchmark datasets. ----- Regressionen werden zunehmend auf Datens\"atzen angewendet, deren Eingangsvektoren nicht durch eine statistische Versuchsplanung festgelegt wurden. Stattdessen werden die Daten beispielsweise durch die passive Beobachtung technischer Systeme gesammelt. Damit bilden bereits die Eingangsdaten Ph\"anomene des Systems ab und widersprechen statistischen Verteilungsannahmen. Die Verteilung der Eingangsdaten hat Einfluss auf die Zuverl\"assigkeit eines Regressionsmodells. Wir stellen deshalb Bewertungskriterien f\"ur einige typische Ph\"anomene in Eingangsdaten von Regressionen vor und zeigen ihre Funktionalit\"at anhand simulierter Benchmarkdatens\"atze.