 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship Between Algorithm Performance, Vocabulary, and Run-Time in Text Classification
Apr 08, 2021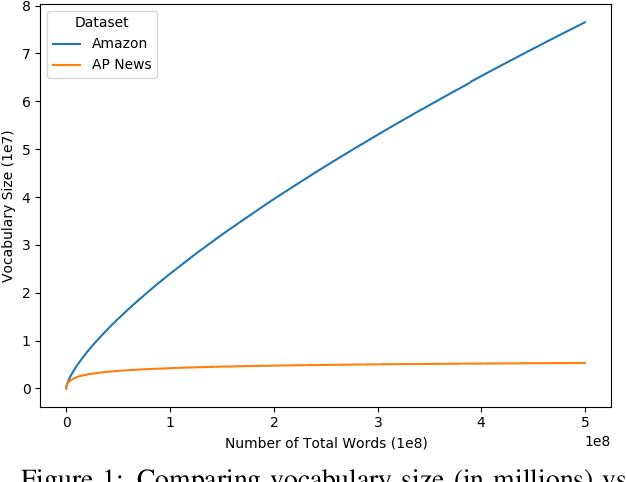
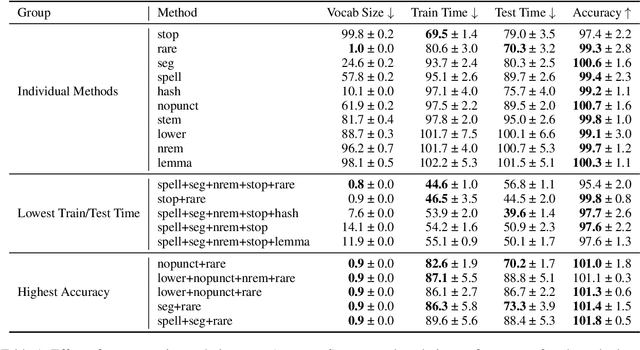
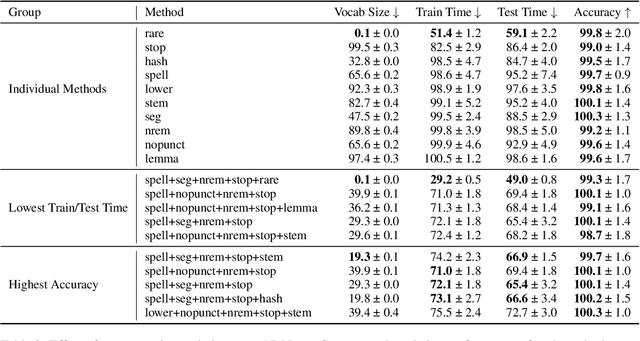
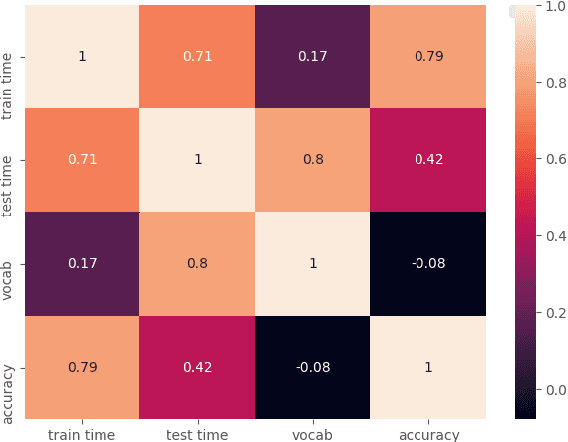
Text classification is a significant branch of natural language processing, and has many applications including document classification and sentiment analysis. Unsurprisingly, those who do text classification are concerned with the run-time of their algorithms, many of which depend on the size of the corpus' vocabulary due to their bag-of-words representation. Although many studies have examined the effect of preprocessing techniques on vocabulary size and accuracy, none have examined how these methods affect a model's run-time. To fill this gap, we provide a comprehensive study that examines how preprocessing techniques affect the vocabulary size, model performance, and model run-time, evaluating ten techniques over four models and two datasets. We show that some individual methods can reduce run-time with no loss of accuracy, while some combinations of methods can trade 2-5% of the accuracy for up to a 65% reduction of run-time. Furthermore, some combinations of preprocessing techniques can even provide a 15% reduction in run-time while simultaneously improving model accuracy.
Automatic Evaluation of Local Topic Quality
May 18, 2019

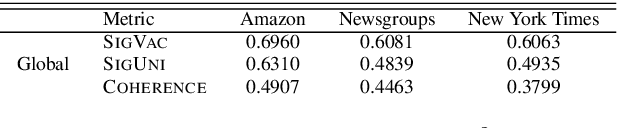
Topic models are typically evaluated with respect to the global topic distributions that they generate, using metrics such as coherence, but without regard to local (token-level) topic assignments. Token-level assignments are important for downstream tasks such as classification. Even recent models, which aim to improve the quality of these token-level topic assignments, have been evaluated only with respect to global metrics. We propose a task designed to elicit human judgments of token-level topic assignments. We use a variety of topic model types and parameters and discover that global metrics agree poorly with human assignments. Since human evaluation is expensive we propose a variety of automated metrics to evaluate topic models at a local level. Finally, we correlate our proposed metrics with human judgments from the task on several datasets. We show that an evaluation based on the percent of topic switches correlates most strongly with human judgment of local topic quality. We suggest that this new metric, which we call consistency, be adopted alongside global metrics such as topic coherence when evaluating new topic models.
Cross-referencing using Fine-grained Topic Modeling
May 18, 2019

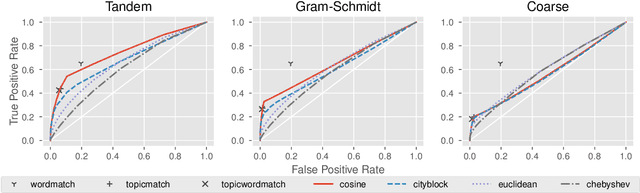
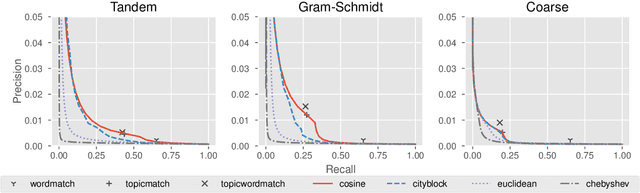
Cross-referencing, which links passages of text to other related passages, can be a valuable study aid for facilitating comprehension of a text. However, cross-referencing requires first, a comprehensive thematic knowledge of the entire corpus, and second, a focused search through the corpus specifically to find such useful connections. Due to this, cross-reference resources are prohibitively expensive and exist only for the most well-studied texts (e.g. religious texts). We develop a topic-based system for automatically producing candidate cross-references which can be easily verified by human annotators. Our system utilizes fine-grained topic modeling with thousands of highly nuanced and specific topics to identify verse pairs which are topically related. We demonstrate that our system can be cost effective compared to having annotators acquire the expertise necessary to produce cross-reference resources unaided.