 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship Between Algorithm Performance, Vocabulary, and Run-Time in Text Classification
Paper and Code
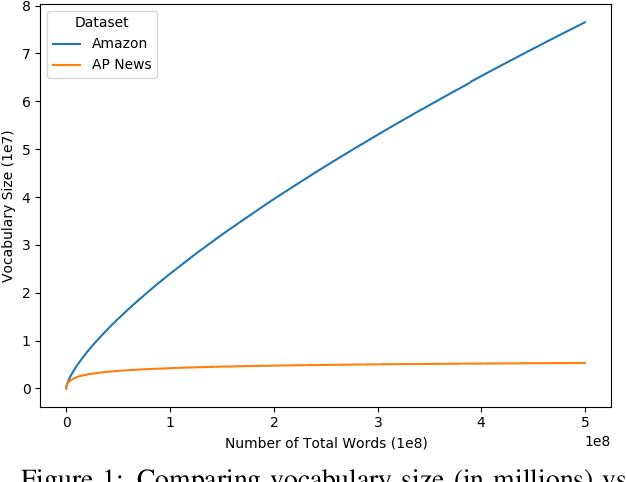
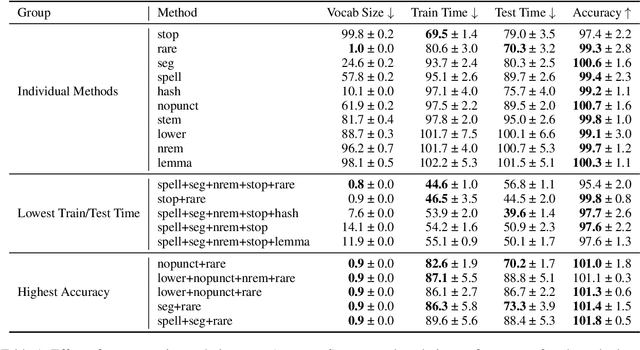
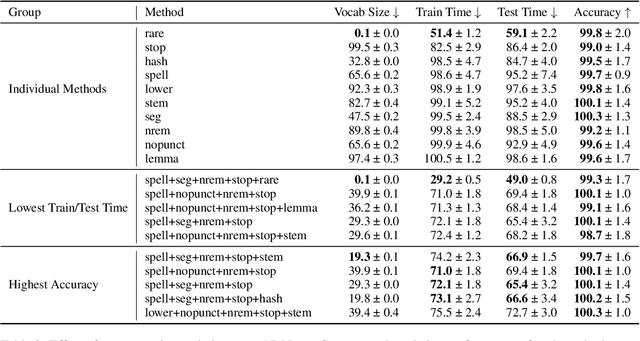
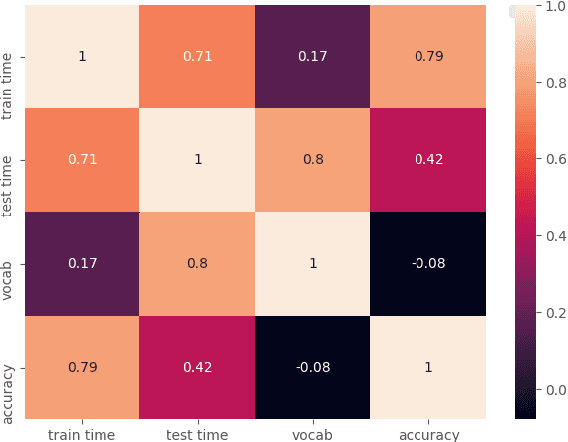
Text classification is a significant branch of natural language processing, and has many applications including document classification and sentiment analysis. Unsurprisingly, those who do text classification are concerned with the run-time of their algorithms, many of which depend on the size of the corpus' vocabulary due to their bag-of-words representation. Although many studies have examined the effect of preprocessing techniques on vocabulary size and accuracy, none have examined how these methods affect a model's run-time. To fill this gap, we provide a comprehensive study that examines how preprocessing techniques affect the vocabulary size, model performance, and model run-time, evaluating ten techniques over four models and two datasets. We show that some individual methods can reduce run-time with no loss of accuracy, while some combinations of methods can trade 2-5% of the accuracy for up to a 65% reduction of run-time. Furthermore, some combinations of preprocessing techniques can even provide a 15% reduction in run-time while simultaneously improving model accuracy.