 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelief-Based Feature Selection: Introduction and Review
Apr 02, 2018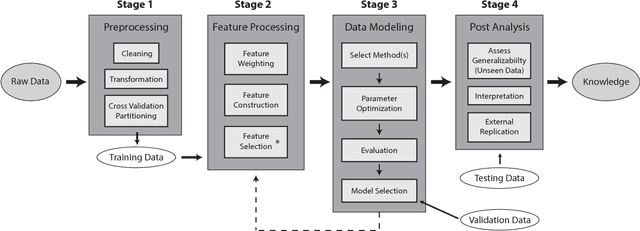
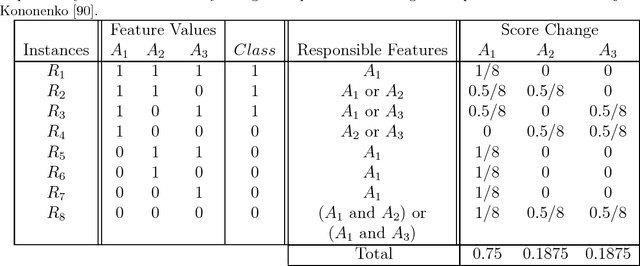
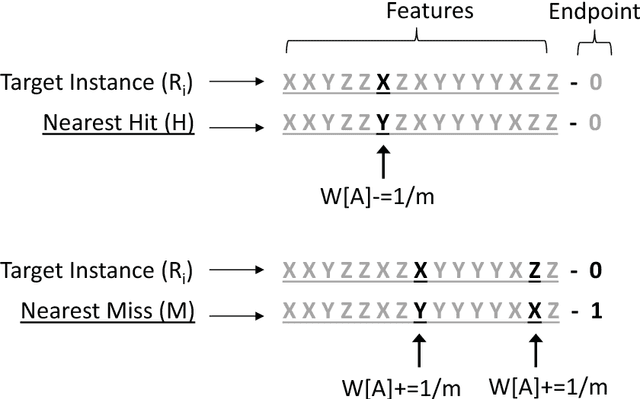

Feature selection plays a critical role in biomedical data mining, driven by increasing feature dimensionality in target problems and growing interest in advanced but computationally expensive methodologies able to model complex associations. Specifically, there is a need for feature selection methods that are computationally efficient, yet sensitive to complex patterns of association, e.g. interactions, so that informative features are not mistakenly eliminated prior to downstream modeling. This paper focuses on Relief-based algorithms (RBAs), a unique family of filter-style feature selection algorithms that have gained appeal by striking an effective balance between these objectives while flexibly adapting to various data characteristics, e.g. classification vs. regression. First, this work broadly examines types of feature selection and defines RBAs within that context. Next, we introduce the original Relief algorithm and associated concepts, emphasizing the intuition behind how it works, how feature weights generated by the algorithm can be interpreted, and why it is sensitive to feature interactions without evaluating combinations of features. Lastly, we include an expansive review of RBA methodological research beyond Relief and its popular descendant, ReliefF. In particular, we characterize branches of RBA research, and provide comparative summaries of RBA algorithms including contributions, strategies, functionality, time complexity, adaptation to key data characteristics, and software availability.