 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Binary Memory: Pseudo-Replay Class-Incremental Learning on Binarized Embeddings
Mar 13, 2025In dynamic environments where new concepts continuously emerge, Deep Neural Networks (DNNs) must adapt by learning new classes while retaining previously acquired ones. This challenge is addressed by Class-Incremental Learning (CIL). This paper introduces Generative Binary Memory (GBM), a novel CIL pseudo-replay approach which generates synthetic binary pseudo-exemplars. Relying on Bernoulli Mixture Models (BMMs), GBM effectively models the multi-modal characteristics of class distributions, in a latent, binary space. With a specifically-designed feature binarizer, our approach applies to any conventional DNN. GBM also natively supports Binary Neural Networks (BNNs) for highly-constrained model sizes in embedded systems. The experimental results demonstrate that GBM achieves higher than state-of-the-art average accuracy on CIFAR100 (+2.9%) and TinyImageNet (+1.5%) for a ResNet-18 equipped with our binarizer. GBM also outperforms emerging CIL methods for BNNs, with +3.1% in final accuracy and x4.7 memory reduction, on CORE50.
Towards Experience Replay for Class-Incremental Learning in Fully-Binary Networks
Mar 10, 2025Binary Neural Networks (BNNs) are a promising approach to enable Artificial Neural Network (ANN) implementation on ultra-low power edge devices. Such devices may compute data in highly dynamic environments, in which the classes targeted for inference can evolve or even novel classes may arise, requiring continual learning. Class Incremental Learning (CIL) is a common type of continual learning for classification problems, that has been scarcely addressed in the context of BNNs. Furthermore, most of existing BNNs models are not fully binary, as they require several real-valued network layers, at the input, the output, and for batch normalization. This paper goes a step further, enabling class incremental learning in Fully-Binarized NNs (FBNNs) through four main contributions. We firstly revisit the FBNN design and its training procedure that is suitable to CIL. Secondly, we explore loss balancing, a method to trade-off the performance of past and current classes. Thirdly, we propose a semi-supervised method to pre-train the feature extractor of the FBNN for transferable representations. Fourthly, two conventional CIL methods, \ie, Latent and Native replay, are thoroughly compared. These contributions are exemplified first on the CIFAR100 dataset, before being scaled up to address the CORE50 continual learning benchmark. The final results based on our 3Mb FBNN on CORE50 exhibit at par and better performance than conventional real-valued larger NN models.
BILLNET: A Binarized Conv3D-LSTM Network with Logic-gated residual architecture for hardware-efficient video inference
Jan 24, 2025Long Short-Term Memory (LSTM) and 3D convolution (Conv3D) show impressive results for many video-based applications but require large memory and intensive computing. Motivated by recent works on hardware-algorithmic co-design towards efficient inference, we propose a compact binarized Conv3D-LSTM model architecture called BILLNET, compatible with a highly resource-constrained hardware. Firstly, BILLNET proposes to factorize the costly standard Conv3D by two pointwise convolutions with a grouped convolution in-between. Secondly, BILLNET enables binarized weights and activations via a MUX-OR-gated residual architecture. Finally, to efficiently train BILLNET, we propose a multi-stage training strategy enabling to fully quantize LSTM layers. Results on Jester dataset show that our method can obtain high accuracy with extremely low memory and computational budgets compared to existing Conv3D resource-efficient models.
* Published at IEEE SiPS 2022
MOGNET: A Mux-residual quantized Network leveraging Online-Generated weights
Jan 16, 2025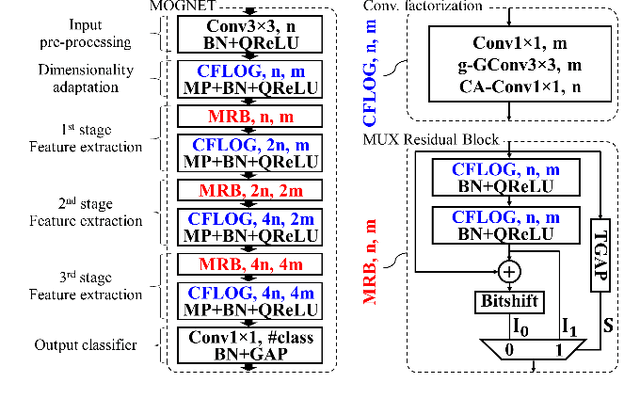
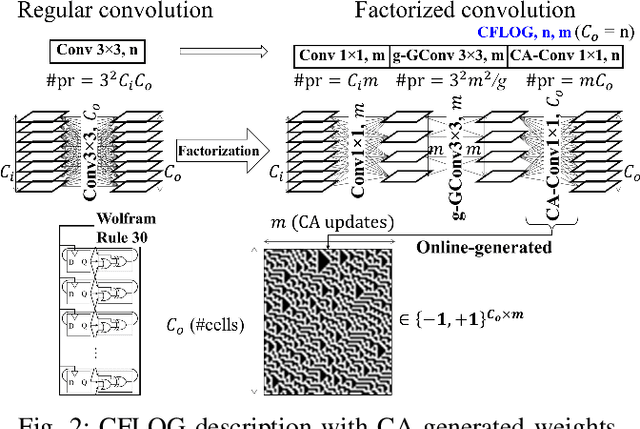
This paper presents a compact model architecture called MOGNET, compatible with a resource-limited hardware. MOGNET uses a streamlined Convolutional factorization block based on a combination of 2 point-wise (1x1) convolutions with a group-wise convolution in-between. To further limit the overall model size and reduce the on-chip required memory, the second point-wise convolution's parameters are on-line generated by a Cellular Automaton structure. In addition, MOGNET enables the use of low-precision weights and activations, by taking advantage of a Multiplexer mechanism with a proper Bitshift rescaling for integrating residual paths without increasing the hardware-related complexity. To efficiently train this model we also introduce a novel weight ternarization method favoring the balance between quantized levels. Experimental results show that given tiny memory budget (sub-2Mb), MOGNET can achieve higher accuracy with a clear gap up to 1% at a similar or even lower model size compared to recent state-of-the-art methods.
* Published at IEEE AICAS 2022
A 1Mb mixed-precision quantized encoder for image classification and patch-based compression
Jan 09, 2025



Even if Application-Specific Integrated Circuits (ASIC) have proven to be a relevant choice for integrating inference at the edge, they are often limited in terms of applicability. In this paper, we demonstrate that an ASIC neural network accelerator dedicated to image processing can be applied to multiple tasks of different levels: image classification and compression, while requiring a very limited hardware. The key component is a reconfigurable, mixed-precision (3b/2b/1b) encoder that takes advantage of proper weight and activation quantizations combined with convolutional layer structural pruning to lower hardware-related constraints (memory and computing). We introduce an automatic adaptation of linear symmetric quantizer scaling factors to perform quantized levels equalization, aiming at stabilizing quinary and ternary weights training. In addition, a proposed layer-shared Bit-Shift Normalization significantly simplifies the implementation of the hardware-expensive Batch Normalization. For a specific configuration in which the encoder design only requires 1Mb, the classification accuracy reaches 87.5% on CIFAR-10. Besides, we also show that this quantized encoder can be used to compress image patch-by-patch while the reconstruction can performed remotely, by a dedicated full-frame decoder. This solution typically enables an end-to-end compression almost without any block artifacts, outperforming patch-based state-of-the-art techniques employing a patch-constant bitrate.
* Published at IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
Histogram-Equalized Quantization for logic-gated Residual Neural Networks
Jan 08, 2025Adjusting the quantization according to the data or to the model loss seems mandatory to enable a high accuracy in the context of quantized neural networks. This work presents Histogram-Equalized Quantization (HEQ), an adaptive framework for linear symmetric quantization. HEQ automatically adapts the quantization thresholds using a unique step size optimization. We empirically show that HEQ achieves state-of-the-art performances on CIFAR-10. Experiments on the STL-10 dataset even show that HEQ enables a proper training of our proposed logic-gated (OR, MUX) residual networks with a higher accuracy at a lower hardware complexity than previous work.
* Published at IEEE ISCAS 2022