 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Binary Memory: Pseudo-Replay Class-Incremental Learning on Binarized Embeddings
Mar 13, 2025In dynamic environments where new concepts continuously emerge, Deep Neural Networks (DNNs) must adapt by learning new classes while retaining previously acquired ones. This challenge is addressed by Class-Incremental Learning (CIL). This paper introduces Generative Binary Memory (GBM), a novel CIL pseudo-replay approach which generates synthetic binary pseudo-exemplars. Relying on Bernoulli Mixture Models (BMMs), GBM effectively models the multi-modal characteristics of class distributions, in a latent, binary space. With a specifically-designed feature binarizer, our approach applies to any conventional DNN. GBM also natively supports Binary Neural Networks (BNNs) for highly-constrained model sizes in embedded systems. The experimental results demonstrate that GBM achieves higher than state-of-the-art average accuracy on CIFAR100 (+2.9%) and TinyImageNet (+1.5%) for a ResNet-18 equipped with our binarizer. GBM also outperforms emerging CIL methods for BNNs, with +3.1% in final accuracy and x4.7 memory reduction, on CORE50.
Towards Experience Replay for Class-Incremental Learning in Fully-Binary Networks
Mar 10, 2025Binary Neural Networks (BNNs) are a promising approach to enable Artificial Neural Network (ANN) implementation on ultra-low power edge devices. Such devices may compute data in highly dynamic environments, in which the classes targeted for inference can evolve or even novel classes may arise, requiring continual learning. Class Incremental Learning (CIL) is a common type of continual learning for classification problems, that has been scarcely addressed in the context of BNNs. Furthermore, most of existing BNNs models are not fully binary, as they require several real-valued network layers, at the input, the output, and for batch normalization. This paper goes a step further, enabling class incremental learning in Fully-Binarized NNs (FBNNs) through four main contributions. We firstly revisit the FBNN design and its training procedure that is suitable to CIL. Secondly, we explore loss balancing, a method to trade-off the performance of past and current classes. Thirdly, we propose a semi-supervised method to pre-train the feature extractor of the FBNN for transferable representations. Fourthly, two conventional CIL methods, \ie, Latent and Native replay, are thoroughly compared. These contributions are exemplified first on the CIFAR100 dataset, before being scaled up to address the CORE50 continual learning benchmark. The final results based on our 3Mb FBNN on CORE50 exhibit at par and better performance than conventional real-valued larger NN models.
SpikeGrad: An ANN-equivalent Computation Model for Implementing Backpropagation with Spikes
Jun 03, 2019



Event-based neuromorphic systems promise to reduce the energy consumption of deep learning tasks by replacing expensive floating point operations on dense matrices by low power sparse and asynchronous operations on spike events. While these systems can be trained increasingly well using approximations of the back-propagation algorithm, these implementations usually require high precision errors for training and are therefore incompatible with the typical communication infrastructure of neuromorphic circuits. In this work, we analyze how the gradient can be discretized into spike events when training a spiking neural network. To accelerate our simulation, we show that using a special implementation of the integrate-and-fire neuron allows us to describe the accumulated activations and errors of the spiking neural network in terms of an equivalent artificial neural network, allowing us to largely speed up training compared to an explicit simulation of all spike events. This way we are able to demonstrate that even for deep networks, the gradients can be discretized sufficiently well with spikes if the gradient is properly rescaled. This form of spike-based backpropagation enables us to achieve equivalent or better accuracies on the MNIST and CIFAR10 dataset than comparable state-of-the-art spiking neural networks trained with full precision gradients. The algorithm, which we call SpikeGrad, is based on accumulation and comparison operations and can naturally exploit sparsity in the gradient computation, which makes it an interesting choice for a spiking neuromorphic systems with on-chip learning capacities.
A Spiking Network for Inference of Relations Trained with Neuromorphic Backpropagation
Mar 11, 2019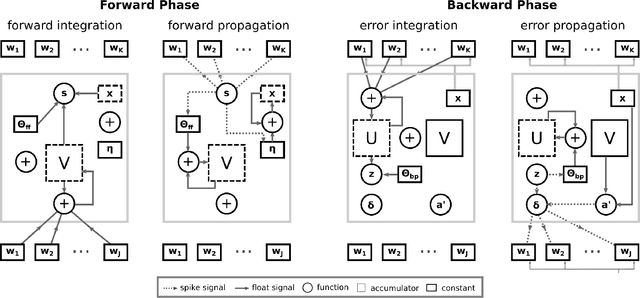
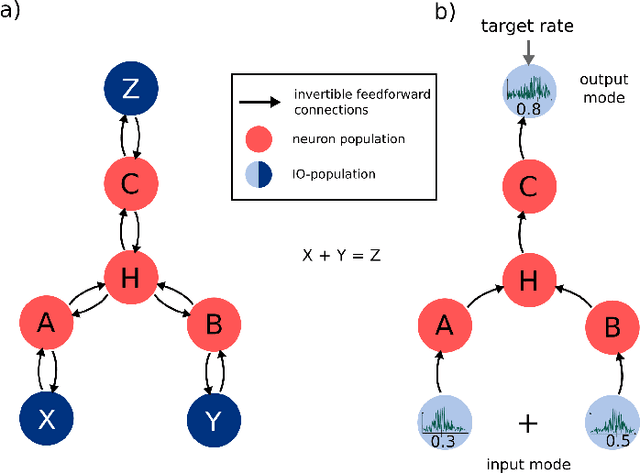
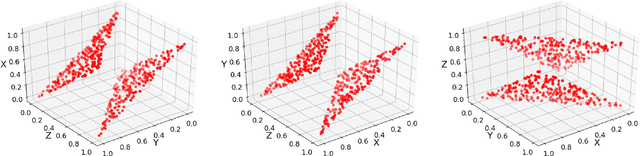

The increasing need for intelligent sensors in a wide range of everyday objects requires the existence of low power information processing systems which can operate autonomously in their environment. In particular, merging and processing the outputs of different sensors efficiently is a necessary requirement for mobile agents with cognitive abilities. In this work, we present a multi-layer spiking neural network for inference of relations between stimuli patterns in dedicated neuromorphic systems. The system is trained with a new version of the backpropagation algorithm adapted to on-chip learning in neuromorphic hardware: Error gradients are encoded as spike signals which are propagated through symmetric synapses, using the same integrate-and-fire hardware infrastructure as used during forward propagation. We demonstrate the strength of the approach on an arithmetic relation inference task and on visual XOR on the MNIST dataset. Compared to previous, biologically-inspired implementations of networks for learning and inference of relations, our approach is able to achieve better performance with less neurons. Our architecture is the first spiking neural network architecture with on-chip learning capabilities, which is able to perform relational inference on complex visual stimuli. These features make our system interesting for sensor fusion applications and embedded learning in autonomous neuromorphic agents.