 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJ3DAI: A tiny DNN-Based Edge AI Accelerator for 3D-Stacked CMOS Image Sensor
Jun 18, 2025This paper presents J3DAI, a tiny deep neural network-based hardware accelerator for a 3-layer 3D-stacked CMOS image sensor featuring an artificial intelligence (AI) chip integrating a Deep Neural Network (DNN)-based accelerator. The DNN accelerator is designed to efficiently perform neural network tasks such as image classification and segmentation. This paper focuses on the digital system of J3DAI, highlighting its Performance-Power-Area (PPA) characteristics and showcasing advanced edge AI capabilities on a CMOS image sensor. To support hardware, we utilized the Aidge comprehensive software framework, which enables the programming of both the host processor and the DNN accelerator. Aidge supports post-training quantization, significantly reducing memory footprint and computational complexity, making it crucial for deploying models on resource-constrained hardware like J3DAI. Our experimental results demonstrate the versatility and efficiency of this innovative design in the field of edge AI, showcasing its potential to handle both simple and computationally intensive tasks. Future work will focus on further optimizing the architecture and exploring new applications to fully leverage the capabilities of J3DAI. As edge AI continues to grow in importance, innovations like J3DAI will play a crucial role in enabling real-time, low-latency, and energy-efficient AI processing at the edge.
Generative Binary Memory: Pseudo-Replay Class-Incremental Learning on Binarized Embeddings
Mar 13, 2025In dynamic environments where new concepts continuously emerge, Deep Neural Networks (DNNs) must adapt by learning new classes while retaining previously acquired ones. This challenge is addressed by Class-Incremental Learning (CIL). This paper introduces Generative Binary Memory (GBM), a novel CIL pseudo-replay approach which generates synthetic binary pseudo-exemplars. Relying on Bernoulli Mixture Models (BMMs), GBM effectively models the multi-modal characteristics of class distributions, in a latent, binary space. With a specifically-designed feature binarizer, our approach applies to any conventional DNN. GBM also natively supports Binary Neural Networks (BNNs) for highly-constrained model sizes in embedded systems. The experimental results demonstrate that GBM achieves higher than state-of-the-art average accuracy on CIFAR100 (+2.9%) and TinyImageNet (+1.5%) for a ResNet-18 equipped with our binarizer. GBM also outperforms emerging CIL methods for BNNs, with +3.1% in final accuracy and x4.7 memory reduction, on CORE50.
Towards Experience Replay for Class-Incremental Learning in Fully-Binary Networks
Mar 10, 2025Binary Neural Networks (BNNs) are a promising approach to enable Artificial Neural Network (ANN) implementation on ultra-low power edge devices. Such devices may compute data in highly dynamic environments, in which the classes targeted for inference can evolve or even novel classes may arise, requiring continual learning. Class Incremental Learning (CIL) is a common type of continual learning for classification problems, that has been scarcely addressed in the context of BNNs. Furthermore, most of existing BNNs models are not fully binary, as they require several real-valued network layers, at the input, the output, and for batch normalization. This paper goes a step further, enabling class incremental learning in Fully-Binarized NNs (FBNNs) through four main contributions. We firstly revisit the FBNN design and its training procedure that is suitable to CIL. Secondly, we explore loss balancing, a method to trade-off the performance of past and current classes. Thirdly, we propose a semi-supervised method to pre-train the feature extractor of the FBNN for transferable representations. Fourthly, two conventional CIL methods, \ie, Latent and Native replay, are thoroughly compared. These contributions are exemplified first on the CIFAR100 dataset, before being scaled up to address the CORE50 continual learning benchmark. The final results based on our 3Mb FBNN on CORE50 exhibit at par and better performance than conventional real-valued larger NN models.
SamurAI: A Versatile IoT Node With Event-Driven Wake-Up and Embedded ML Acceleration
Apr 11, 2023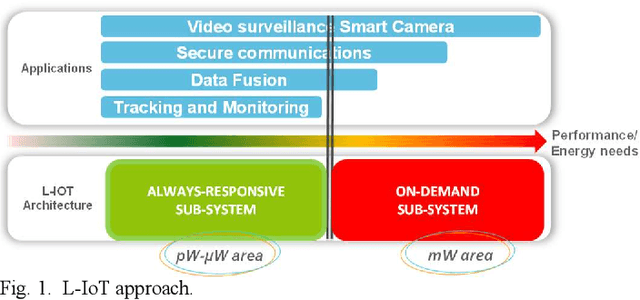
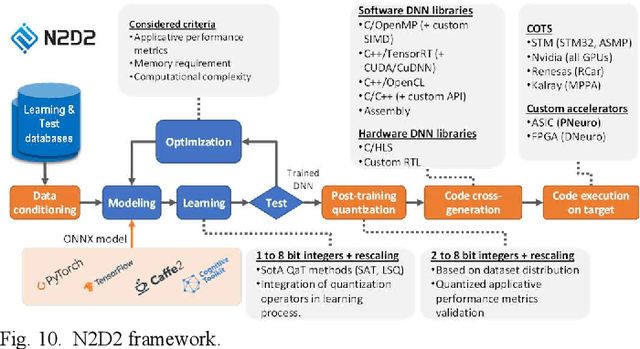
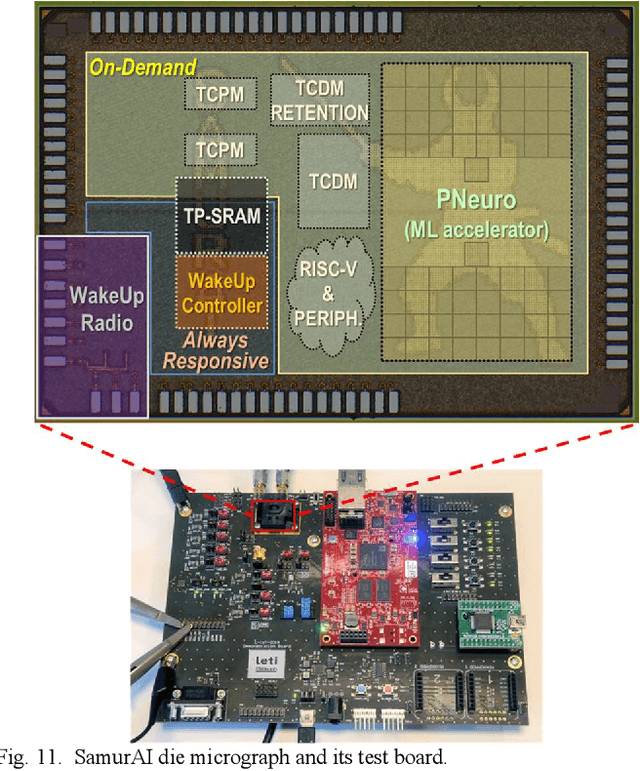
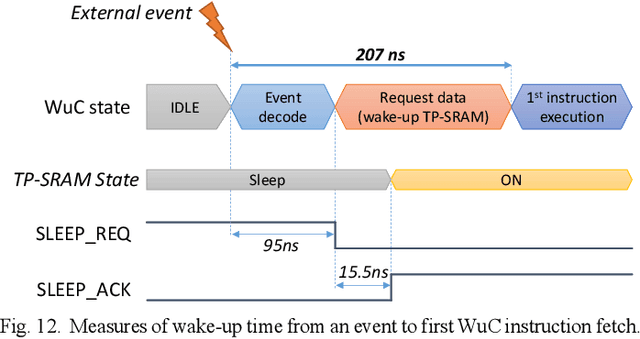
Increased capabilities such as recognition and self-adaptability are now required from IoT applications. While IoT node power consumption is a major concern for these applications, cloud-based processing is becoming unsustainable due to continuous sensor or image data transmission over the wireless network. Thus optimized ML capabilities and data transfers should be integrated in the IoT node. Moreover, IoT applications are torn between sporadic data-logging and energy-hungry data processing (e.g. image classification). Thus, the versatility of the node is key in addressing this wide diversity of energy and processing needs. This paper presents SamurAI, a versatile IoT node bridging this gap in processing and in energy by leveraging two on-chip sub-systems: a low power, clock-less, event-driven Always-Responsive (AR) part and an energy-efficient On-Demand (OD) part. AR contains a 1.7MOPS event-driven, asynchronous Wake-up Controller (WuC) with a 207ns wake-up time optimized for sporadic computing, while OD combines a deep-sleep RISC-V CPU and 1.3TOPS/W Machine Learning (ML) for more complex tasks up to 36GOPS. This architecture partitioning achieves best in class versatility metrics such as peak performance to idle power ratio. On an applicative classification scenario, it demonstrates system power gains, up to 3.5x compared to cloud-based processing, and thus extended battery lifetime.