 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Architecture for Database Augmentation Using Shared Features
Feb 02, 2023

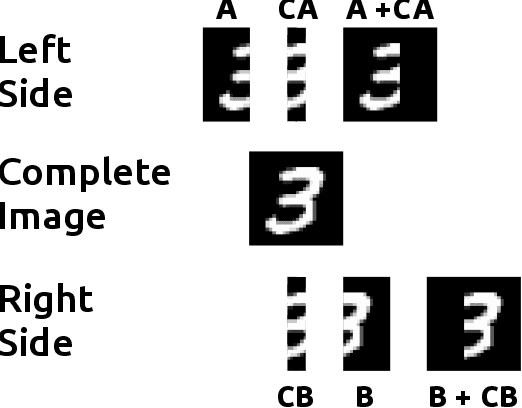

The popularity of learning from data with machine learning and neural networks has lead to the creation of many new datasets for almost every problem domain. However, even within a single domain, these datasets are often collected with disparate features, sampled from different sub-populations, and recorded at different time points. Even with the plethora of individual datasets, large data science projects can be difficult as it is often not trivial to merge these smaller datasets. Inherent challenges in some domains such as medicine also makes it very difficult to create large single source datasets or multi-source datasets with identical features. Instead of trying to merge these non-matching datasets directly, we propose a neural network architecture that can provide data augmentation using features common between these datasets. Our results show that this style of data augmentation can work for both image and tabular data.
Multimodal Classification: Current Landscape, Taxonomy and Future Directions
Sep 18, 2021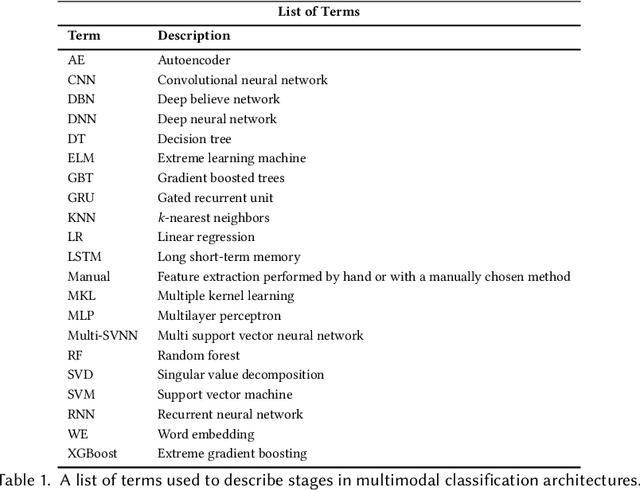
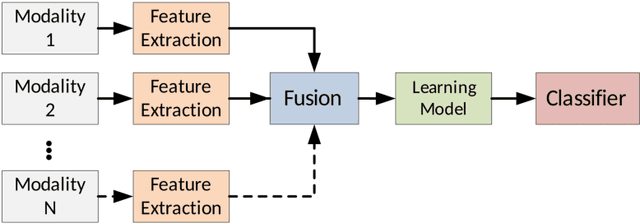
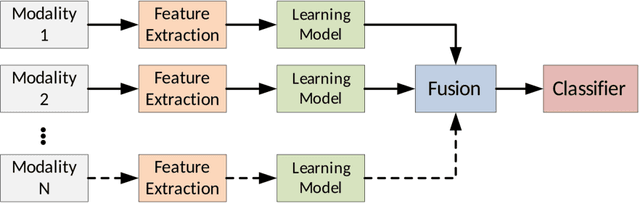
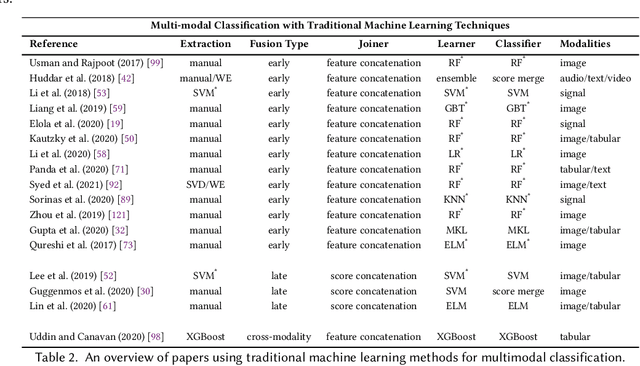
Multimodal classification research has been gaining popularity in many domains that collect more data from multiple sources including satellite imagery, biometrics, and medicine. However, the lack of consistent terminology and architectural descriptions makes it difficult to compare different existing solutions. We address these challenges by proposing a new taxonomy for describing such systems based on trends found in recent publications on multimodal classification. Many of the most difficult aspects of unimodal classification have not yet been fully addressed for multimodal datasets including big data, class imbalance, and instance level difficulty. We also provide a discussion of these challenges and future directions.
Imbalanced Big Data Oversampling: Taxonomy, Algorithms, Software, Guidelines and Future Directions
Jul 24, 2021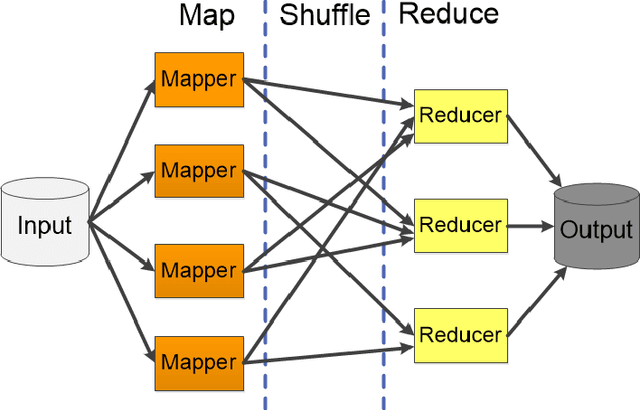
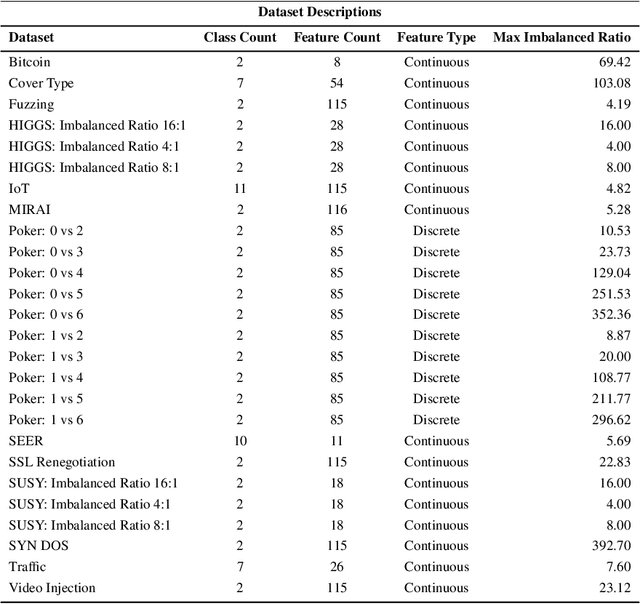
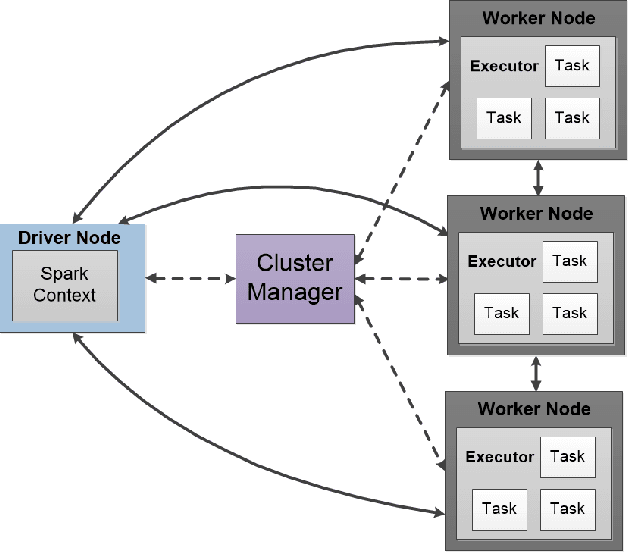

Learning from imbalanced data is among the most challenging areas in contemporary machine learning. This becomes even more difficult when considered the context of big data that calls for dedicated architectures capable of high-performance processing. Apache Spark is a highly efficient and popular architecture, but it poses specific challenges for algorithms to be implemented for it. While oversampling algorithms are an effective way for handling class imbalance, they have not been designed for distributed environments. In this paper, we propose a holistic look on oversampling algorithms for imbalanced big data. We discuss the taxonomy of oversampling algorithms and their mechanisms used to handle skewed class distributions. We introduce a Spark library with 14 state-of-the-art oversampling algorithms implemented and evaluate their efficacy via extensive experimental study. Using binary and multi-class massive data sets, we analyze the effectiveness of oversampling algorithms and their relationships with different types of classifiers. We evaluate the trade-off between accuracy and time complexity of oversampling algorithms, as well as their scalability when increasing the size of data. This allows us to gain insight into the usefulness of specific components of oversampling algorithms for big data, as well as formulate guidelines and recommendations for designing future resampling approaches for massive imbalanced data. Our library can be downloaded from https://github.com/fsleeman/spark-class-balancing.git.