 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Architecture for Database Augmentation Using Shared Features
Feb 02, 2023

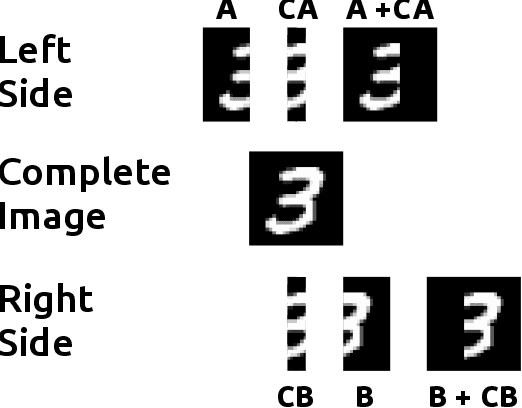

The popularity of learning from data with machine learning and neural networks has lead to the creation of many new datasets for almost every problem domain. However, even within a single domain, these datasets are often collected with disparate features, sampled from different sub-populations, and recorded at different time points. Even with the plethora of individual datasets, large data science projects can be difficult as it is often not trivial to merge these smaller datasets. Inherent challenges in some domains such as medicine also makes it very difficult to create large single source datasets or multi-source datasets with identical features. Instead of trying to merge these non-matching datasets directly, we propose a neural network architecture that can provide data augmentation using features common between these datasets. Our results show that this style of data augmentation can work for both image and tabular data.
Multimodal Classification: Current Landscape, Taxonomy and Future Directions
Sep 18, 2021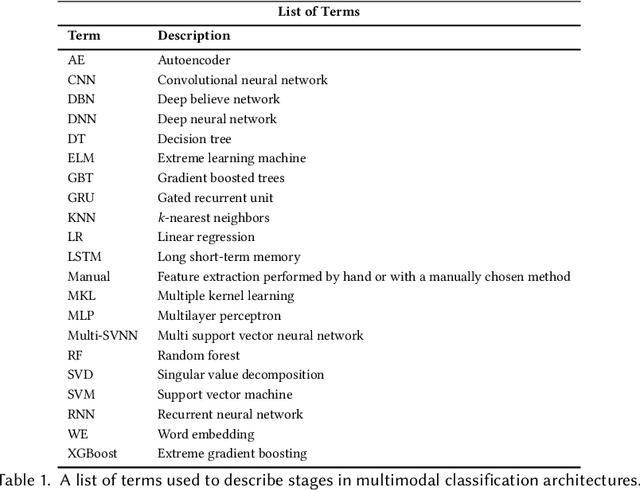
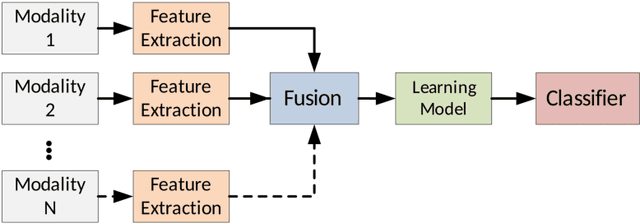
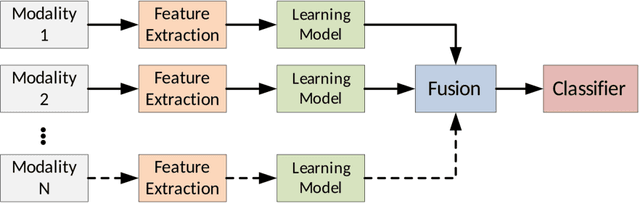
Multimodal classification research has been gaining popularity in many domains that collect more data from multiple sources including satellite imagery, biometrics, and medicine. However, the lack of consistent terminology and architectural descriptions makes it difficult to compare different existing solutions. We address these challenges by proposing a new taxonomy for describing such systems based on trends found in recent publications on multimodal classification. Many of the most difficult aspects of unimodal classification have not yet been fully addressed for multimodal datasets including big data, class imbalance, and instance level difficulty. We also provide a discussion of these challenges and future directions.
Sketch2Code: Transformation of Sketches to UI in Real-time Using Deep Neural Network
Oct 20, 2019
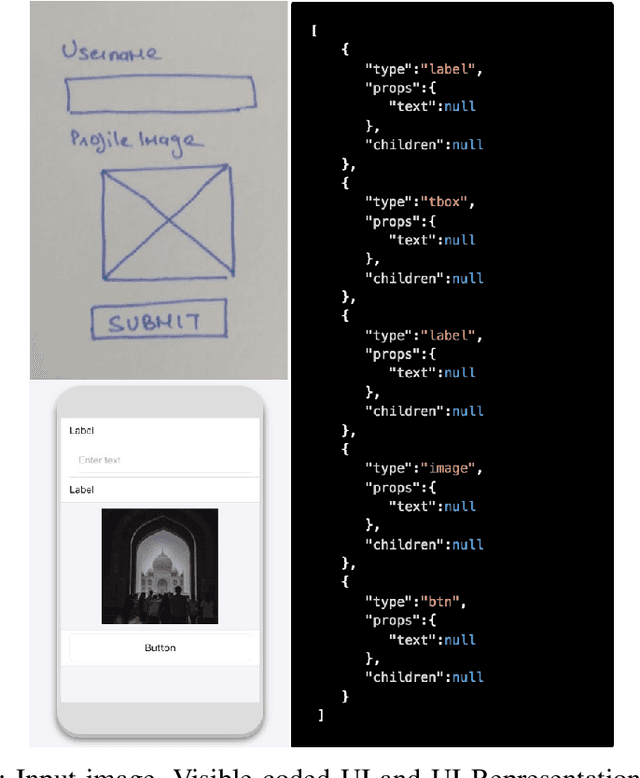
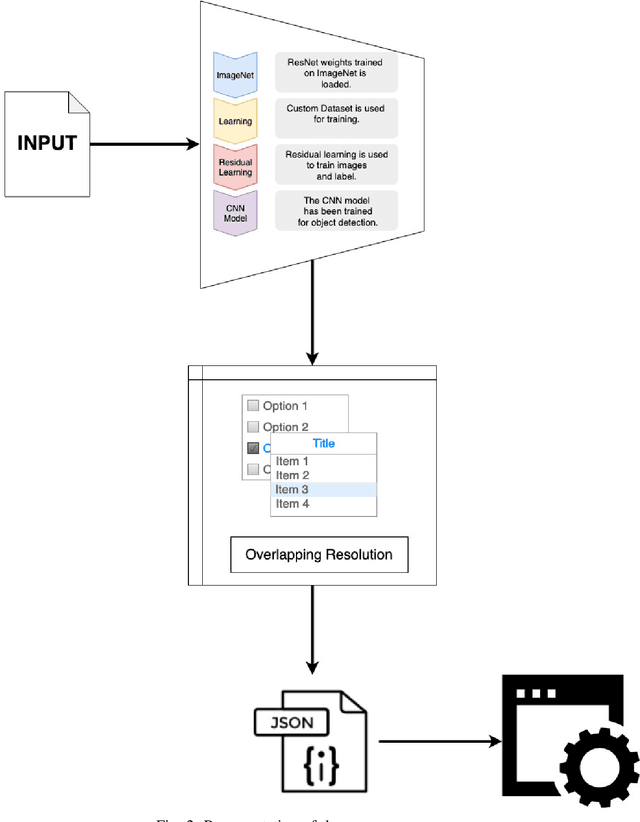
User Interface (UI) prototyping is a necessary step in the early stages of application development. Transforming sketches of a Graphical User Interface (UI) into a coded UI application is an uninspired but time-consuming task performed by a UI designer. An automated system that can replace human efforts for straightforward implementation of UI designs will greatly speed up this procedure. The works that propose such a system primarily focus on using UI wireframes as input rather than hand-drawn sketches. In this paper, we put forward a novel approach wherein we employ a Deep Neural Network that is trained on our custom database of such sketches to detect UI elements in the input sketch. Detection of objects in sketches is a peculiar visual recognition task that requires a specific solution that our deep neural network model attempts to provide. The output from the network is a platform-independent UI representation object. The UI representation object is a dictionary of key-value pairs to represent the UI elements recognized along with their properties. This is further consumed by our UI parser which creates code for different platforms. The intrinsic platform-independence allows the model to create a UI prototype for multiple platforms with single training. This two-step approach without the need for two trained models improves over other methods giving time-efficient results (average time: 129 ms) with good accuracy.