 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Corpus-Scale Discovery of Selection Biases in News Coverage: Comparing What Sources Say About Entities as a Start
Apr 06, 2023News sources undergo the process of selecting newsworthy information when covering a certain topic. The process inevitably exhibits selection biases, i.e. news sources' typical patterns of choosing what information to include in news coverage, due to their agenda differences. To understand the magnitude and implications of selection biases, one must first discover (1) on what topics do sources typically have diverging definitions of "newsworthy" information, and (2) do the content selection patterns correlate with certain attributes of the news sources, e.g. ideological leaning, etc. The goal of the paper is to investigate and discuss the challenges of building scalable NLP systems for discovering patterns of media selection biases directly from news content in massive-scale news corpora, without relying on labeled data. To facilitate research in this domain, we propose and study a conceptual framework, where we compare how sources typically mention certain controversial entities, and use such as indicators for the sources' content selection preferences. We empirically show the capabilities of the framework through a case study on NELA-2020, a corpus of 1.8M news articles in English from 519 news sources worldwide. We demonstrate an unsupervised representation learning method to capture the selection preferences for how sources typically mention controversial entities. Our experiments show that that distributional divergence of such representations, when studied collectively across entities and news sources, serve as good indicators for an individual source's ideological leaning. We hope our findings will provide insights for future research on media selection biases.
LawngNLI: A Long-Premise Benchmark for In-Domain Generalization from Short to Long Contexts and for Implication-Based Retrieval
Dec 06, 2022
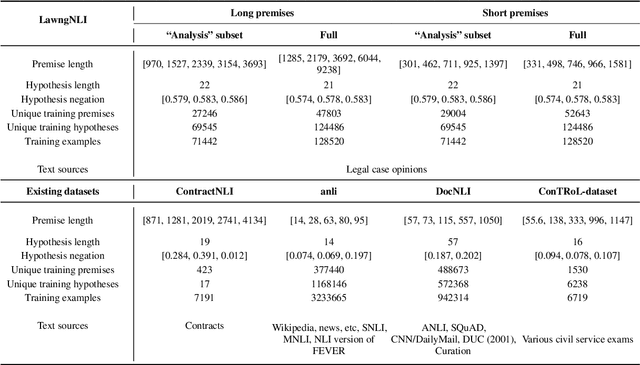
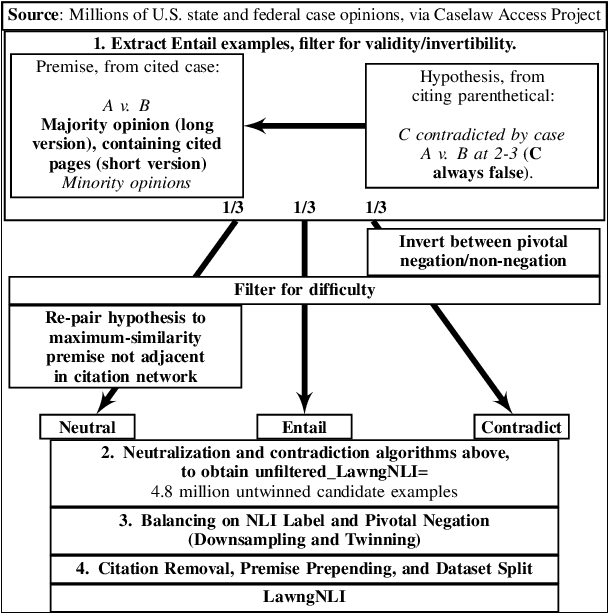
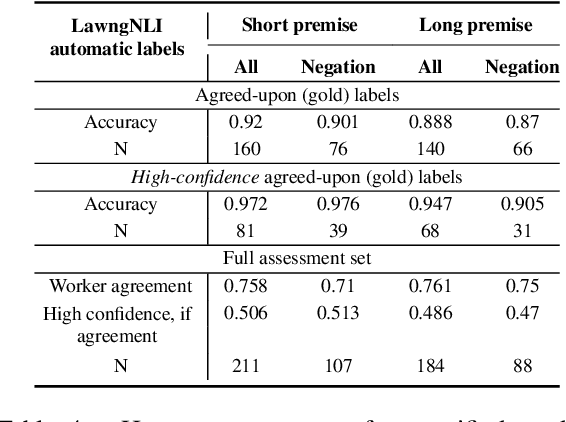
Natural language inference has trended toward studying contexts beyond the sentence level. An important application area is law: past cases often do not foretell how they apply to new situations and implications must be inferred. This paper introduces LawngNLI, constructed from U.S. legal opinions with automatic labels with high human-validated accuracy. Premises are long and multigranular. Experiments show two use cases. First, LawngNLI can benchmark for in-domain generalization from short to long contexts. It has remained unclear if large-scale long-premise NLI datasets actually need to be constructed: near-top performance on long premises could be achievable by fine-tuning using short premises. Without multigranularity, benchmarks cannot distinguish lack of fine-tuning on long premises versus domain shift between short and long datasets. In contrast, our long and short premises share the same examples and domain. Models fine-tuned using several past NLI datasets and/or our short premises fall short of top performance on our long premises. So for at least certain domains (such as ours), large-scale long-premise datasets are needed. Second, LawngNLI can benchmark for implication-based retrieval. Queries are entailed or contradicted by target documents, allowing users to move between arguments and evidence. Leading retrieval models perform reasonably zero shot on a LawngNLI-derived retrieval task. We compare different systems for re-ranking, including lexical overlap and cross-encoders fine-tuned using a modified LawngNLI or past NLI datasets. LawngNLI can train and test systems for implication-based case retrieval and argumentation.
Design Challenges for a Multi-Perspective Search Engine
Dec 15, 2021
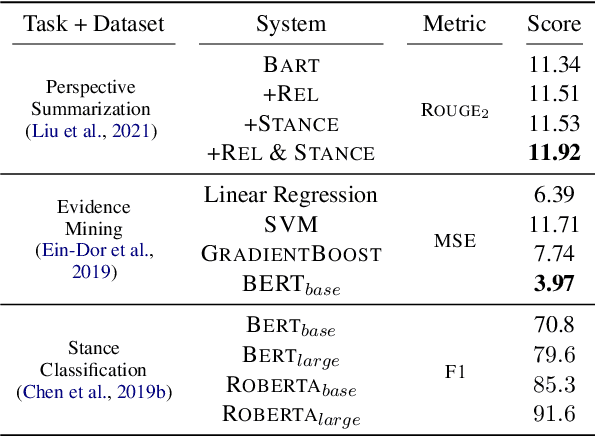
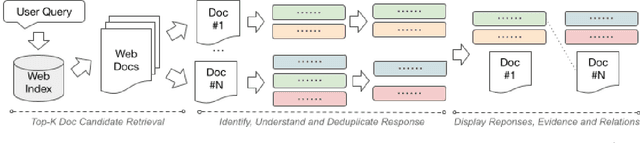

Many users turn to document retrieval systems (e.g. search engines) to seek answers to controversial questions. Answering such user queries usually require identifying responses within web documents, and aggregating the responses based on their different perspectives. Classical document retrieval systems fall short at delivering a set of direct and diverse responses to the users. Naturally, identifying such responses within a document is a natural language understanding task. In this paper, we examine the challenges of synthesizing such language understanding objectives with document retrieval, and study a new perspective-oriented document retrieval paradigm. We discuss and assess the inherent natural language understanding challenges in order to achieve the goal. Following the design challenges and principles, we demonstrate and evaluate a practical prototype pipeline system. We use the prototype system to conduct a user survey in order to assess the utility of our paradigm, as well as understanding the user information needs for controversial queries.