 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Submodular Functions
Jan 31, 2017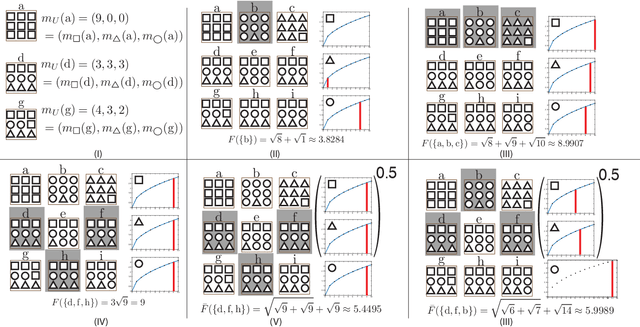
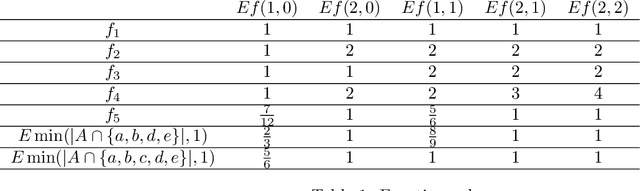
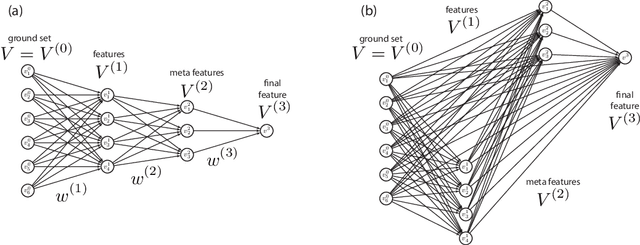
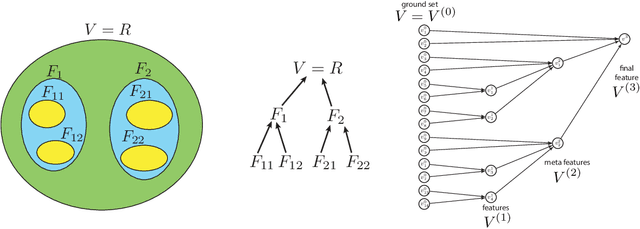
We start with an overview of a class of submodular functions called SCMMs (sums of concave composed with non-negative modular functions plus a final arbitrary modular). We then define a new class of submodular functions we call {\em deep submodular functions} or DSFs. We show that DSFs are a flexible parametric family of submodular functions that share many of the properties and advantages of deep neural networks (DNNs). DSFs can be motivated by considering a hierarchy of descriptive concepts over ground elements and where one wishes to allow submodular interaction throughout this hierarchy. Results in this paper show that DSFs constitute a strictly larger class of submodular functions than SCMMs. We show that, for any integer $k>0$, there are $k$-layer DSFs that cannot be represented by a $k'$-layer DSF for any $k'<k$. This implies that, like DNNs, there is a utility to depth, but unlike DNNs, the family of DSFs strictly increase with depth. Despite this, we show (using a "backpropagation" like method) that DSFs, even with arbitrarily large $k$, do not comprise all submodular functions. In offering the above results, we also define the notion of an antitone superdifferential of a concave function and show how this relates to submodular functions (in general), DSFs (in particular), negative second-order partial derivatives, continuous submodularity, and concave extensions. To further motivate our analysis, we provide various special case results from matroid theory, comparing DSFs with forms of matroid rank, in particular the laminar matroid. Lastly, we discuss strategies to learn DSFs, and define the classes of deep supermodular functions, deep difference of submodular functions, and deep multivariate submodular functions, and discuss where these can be useful in applications.
Mixed Robust/Average Submodular Partitioning: Fast Algorithms, Guarantees, and Applications to Parallel Machine Learning and Multi-Label Image Segmentation
Aug 16, 2016

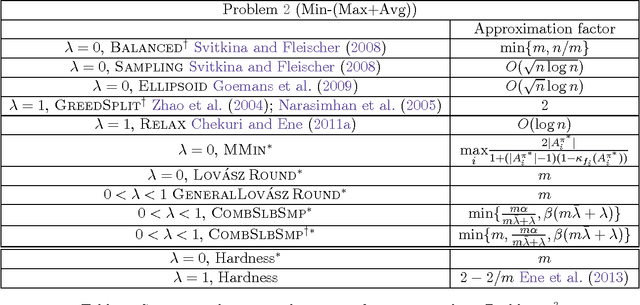
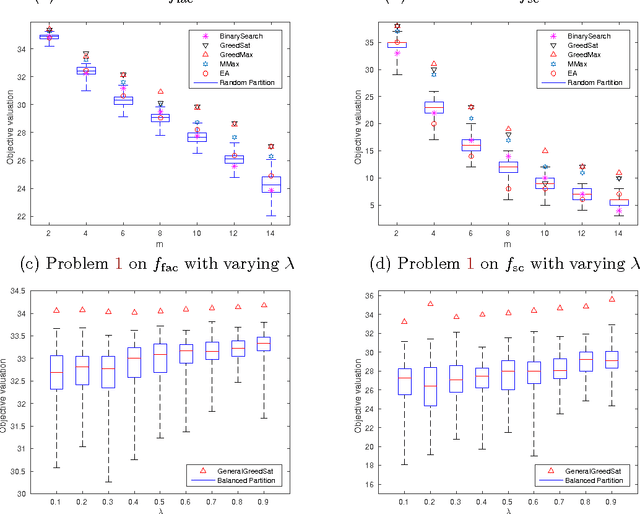
We study two mixed robust/average-case submodular partitioning problems that we collectively call Submodular Partitioning. These problems generalize both purely robust instances of the problem (namely max-min submodular fair allocation (SFA) and min-max submodular load balancing (SLB) and also generalize average-case instances (that is the submodular welfare problem (SWP) and submodular multiway partition (SMP). While the robust versions have been studied in the theory community, existing work has focused on tight approximation guarantees, and the resultant algorithms are not, in general, scalable to very large real-world applications. This is in contrast to the average case, where most of the algorithms are scalable. In the present paper, we bridge this gap, by proposing several new algorithms (including those based on greedy, majorization-minimization, minorization-maximization, and relaxation algorithms) that not only scale to large sizes but that also achieve theoretical approximation guarantees close to the state-of-the-art, and in some cases achieve new tight bounds. We also provide new scalable algorithms that apply to additive combinations of the robust and average-case extreme objectives. We show that these problems have many applications in machine learning (ML). This includes: 1) data partitioning and load balancing for distributed machine algorithms on parallel machines; 2) data clustering; and 3) multi-label image segmentation with (only) Boolean submodular functions via pixel partitioning. We empirically demonstrate the efficacy of our algorithms on real-world problems involving data partitioning for distributed optimization of standard machine learning objectives (including both convex and deep neural network objectives), and also on purely unsupervised (i.e., no supervised or semi-supervised learning, and no interactive segmentation) image segmentation.