 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeblur e-NeRF: NeRF from Motion-Blurred Events under High-speed or Low-light Conditions
Sep 26, 2024The stark contrast in the design philosophy of an event camera makes it particularly ideal for operating under high-speed, high dynamic range and low-light conditions, where standard cameras underperform. Nonetheless, event cameras still suffer from some amount of motion blur, especially under these challenging conditions, in contrary to what most think. This is attributed to the limited bandwidth of the event sensor pixel, which is mostly proportional to the light intensity. Thus, to ensure that event cameras can truly excel in such conditions where it has an edge over standard cameras, it is crucial to account for event motion blur in downstream applications, especially reconstruction. However, none of the recent works on reconstructing Neural Radiance Fields (NeRFs) from events, nor event simulators, have considered the full effects of event motion blur. To this end, we propose, Deblur e-NeRF, a novel method to directly and effectively reconstruct blur-minimal NeRFs from motion-blurred events generated under high-speed motion or low-light conditions. The core component of this work is a physically-accurate pixel bandwidth model proposed to account for event motion blur under arbitrary speed and lighting conditions. We also introduce a novel threshold-normalized total variation loss to improve the regularization of large textureless patches. Experiments on real and novel realistically simulated sequences verify our effectiveness. Our code, event simulator and synthetic event dataset will be open-sourced.
Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering
Nov 28, 2023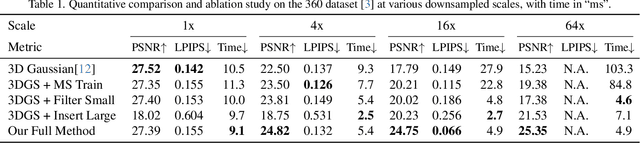
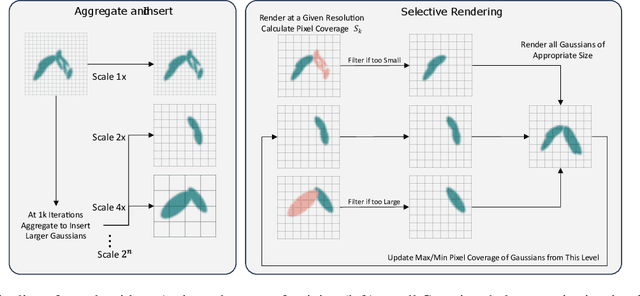
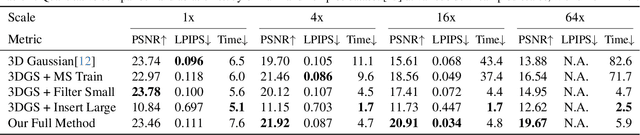

3D Gaussians have recently emerged as a highly efficient representation for 3D reconstruction and rendering. Despite its high rendering quality and speed at high resolutions, they both deteriorate drastically when rendered at lower resolutions or from far away camera position. During low resolution or far away rendering, the pixel size of the image can fall below the Nyquist frequency compared to the screen size of each splatted 3D Gaussian and leads to aliasing effect. The rendering is also drastically slowed down by the sequential alpha blending of more splatted Gaussians per pixel. To address these issues, we propose a multi-scale 3D Gaussian splatting algorithm, which maintains Gaussians at different scales to represent the same scene. Higher-resolution images are rendered with more small Gaussians, and lower-resolution images are rendered with fewer larger Gaussians. With similar training time, our algorithm can achieve 13\%-66\% PSNR and 160\%-2400\% rendering speed improvement at 4$\times$-128$\times$ scale rendering on Mip-NeRF360 dataset compared to the single scale 3D Gaussian splatting.
Robust e-NeRF: NeRF from Sparse & Noisy Events under Non-Uniform Motion
Sep 15, 2023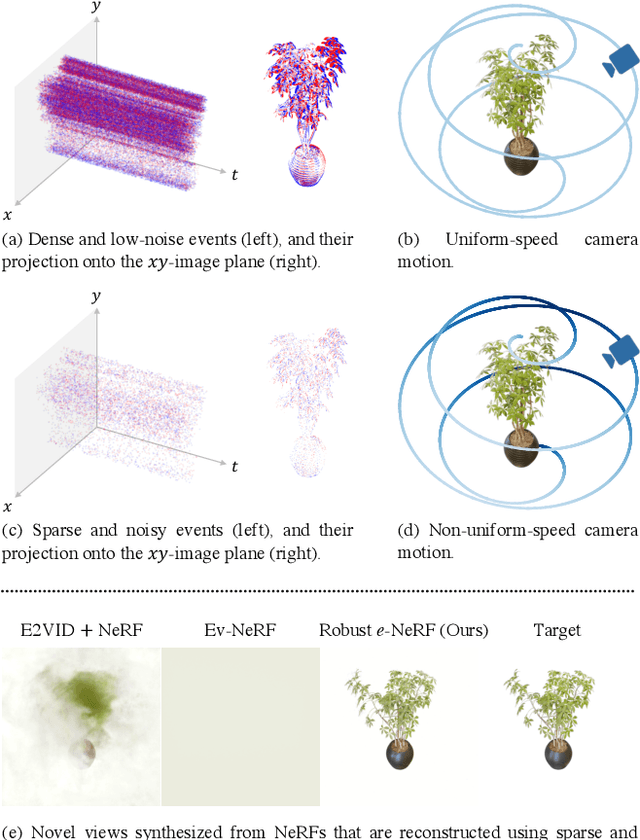

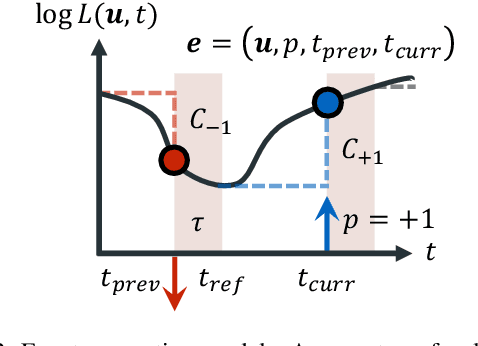

Event cameras offer many advantages over standard cameras due to their distinctive principle of operation: low power, low latency, high temporal resolution and high dynamic range. Nonetheless, the success of many downstream visual applications also hinges on an efficient and effective scene representation, where Neural Radiance Field (NeRF) is seen as the leading candidate. Such promise and potential of event cameras and NeRF inspired recent works to investigate on the reconstruction of NeRF from moving event cameras. However, these works are mainly limited in terms of the dependence on dense and low-noise event streams, as well as generalization to arbitrary contrast threshold values and camera speed profiles. In this work, we propose Robust e-NeRF, a novel method to directly and robustly reconstruct NeRFs from moving event cameras under various real-world conditions, especially from sparse and noisy events generated under non-uniform motion. It consists of two key components: a realistic event generation model that accounts for various intrinsic parameters (e.g. time-independent, asymmetric threshold and refractory period) and non-idealities (e.g. pixel-to-pixel threshold variation), as well as a complementary pair of normalized reconstruction losses that can effectively generalize to arbitrary speed profiles and intrinsic parameter values without such prior knowledge. Experiments on real and novel realistically simulated sequences verify our effectiveness. Our code, synthetic dataset and improved event simulator are public.
Minimal Neural Atlas: Parameterizing Complex Surfaces with Minimal Charts and Distortion
Jul 29, 2022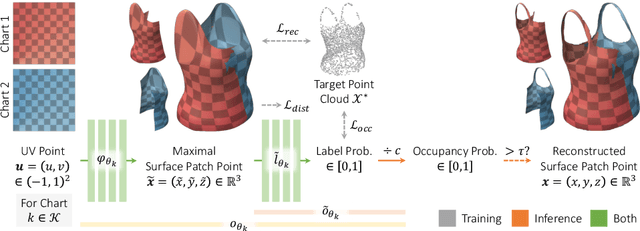
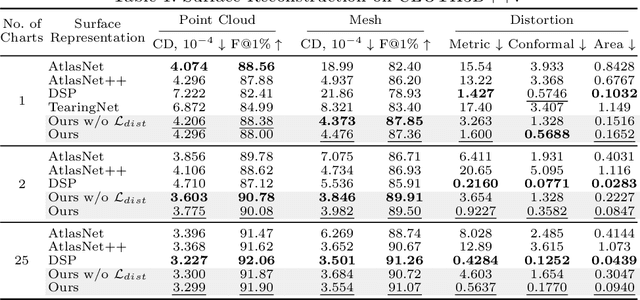
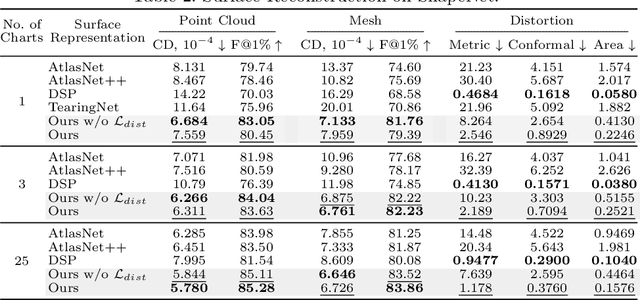
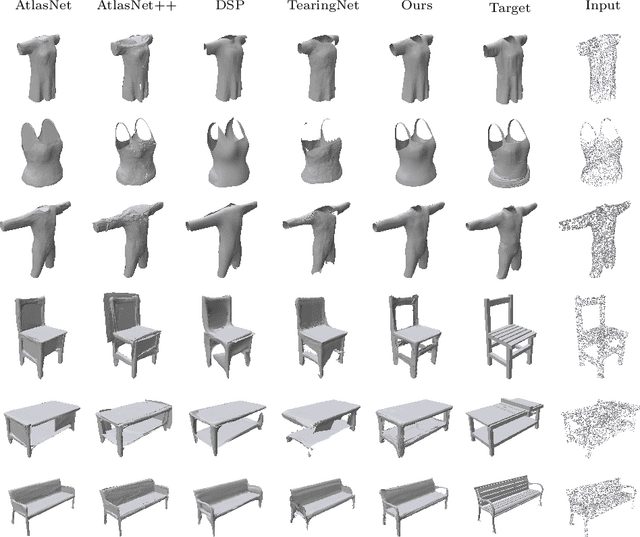
Explicit neural surface representations allow for exact and efficient extraction of the encoded surface at arbitrary precision, as well as analytic derivation of differential geometric properties such as surface normal and curvature. Such desirable properties, which are absent in its implicit counterpart, makes it ideal for various applications in computer vision, graphics and robotics. However, SOTA works are limited in terms of the topology it can effectively describe, distortion it introduces to reconstruct complex surfaces and model efficiency. In this work, we present Minimal Neural Atlas, a novel atlas-based explicit neural surface representation. At its core is a fully learnable parametric domain, given by an implicit probabilistic occupancy field defined on an open square of the parametric space. In contrast, prior works generally predefine the parametric domain. The added flexibility enables charts to admit arbitrary topology and boundary. Thus, our representation can learn a minimal atlas of 3 charts with distortion-minimal parameterization for surfaces of arbitrary topology, including closed and open surfaces with arbitrary connected components. Our experiments support the hypotheses and show that our reconstructions are more accurate in terms of the overall geometry, due to the separation of concerns on topology and geometry.
Superevents: Towards Native Semantic Segmentation for Event-based Cameras
May 13, 2021
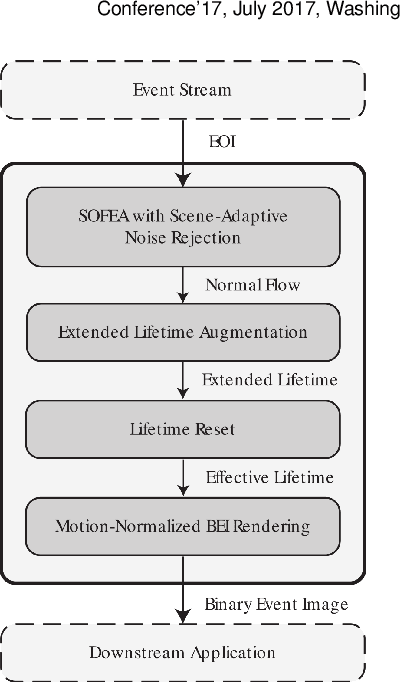


Most successful computer vision models transform low-level features, such as Gabor filter responses, into richer representations of intermediate or mid-level complexity for downstream visual tasks. These mid-level representations have not been explored for event cameras, although it is especially relevant to the visually sparse and often disjoint spatial information in the event stream. By making use of locally consistent intermediate representations, termed as superevents, numerous visual tasks ranging from semantic segmentation, visual tracking, depth estimation shall benefit. In essence, superevents are perceptually consistent local units that delineate parts of an object in a scene. Inspired by recent deep learning architectures, we present a novel method that employs lifetime augmentation for obtaining an event stream representation that is fed to a fully convolutional network to extract superevents. Our qualitative and quantitative experimental results on several sequences of a benchmark dataset highlights the significant potential for event-based downstream applications.