 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Density Ratio Super Learner
Aug 09, 2024The estimation of the ratio of two density probability functions is of great interest in many statistics fields, including causal inference. In this study, we develop an ensemble estimator of density ratios with a novel loss function based on super learning. We show that this novel loss function is qualified for building super learners. Two simulations corresponding to mediation analysis and longitudinal modified treatment policy in causal inference, where density ratios are nuisance parameters, are conducted to show our density ratio super learner's performance empirically.
Neural Process for Black-Box Model Optimization Under Bayesian Framework
Apr 03, 2021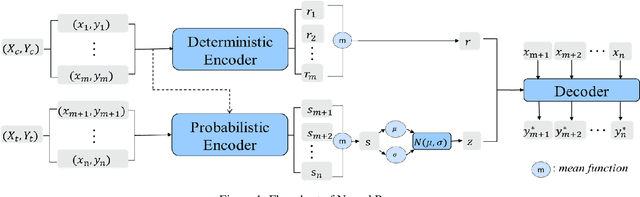
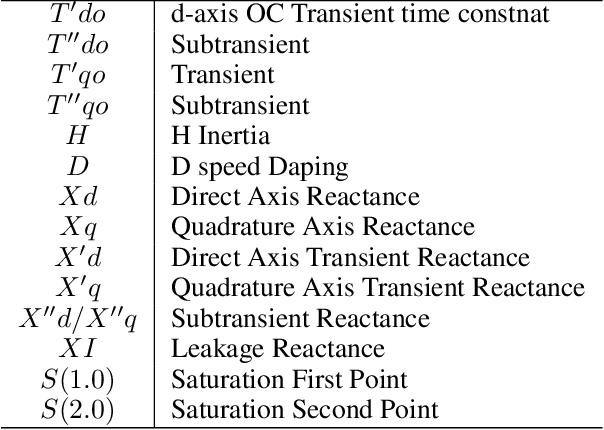
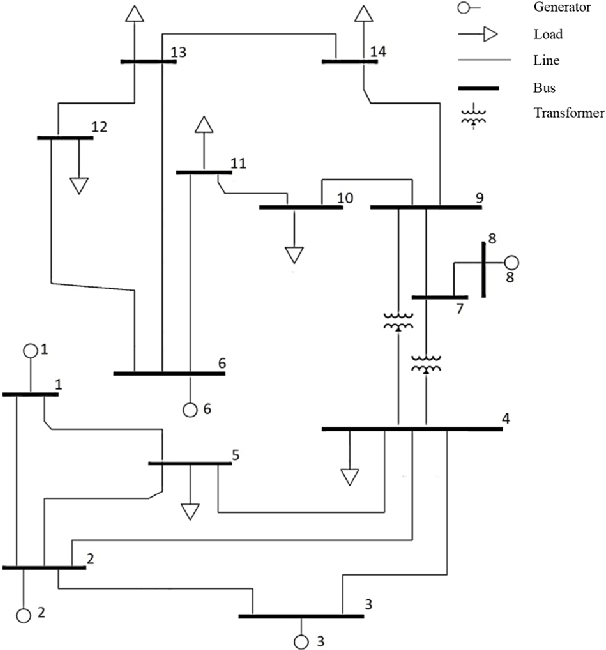
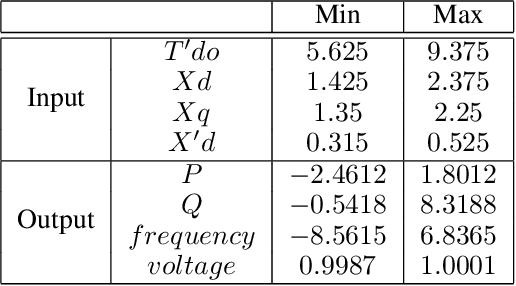
There are a large number of optimization problems in physical models where the relationships between model parameters and outputs are unknown or hard to track. These models are named as black-box models in general because they can only be viewed in terms of inputs and outputs, without knowledge of the internal workings. Optimizing the black-box model parameters has become increasingly expensive and time consuming as they have become more complex. Hence, developing effective and efficient black-box model optimization algorithms has become an important task. One powerful algorithm to solve such problem is Bayesian optimization, which can effectively estimates the model parameters that lead to the best performance, and Gaussian Process (GP) has been one of the most widely used surrogate model in Bayesian optimization. However, the time complexity of GP scales cubically with respect to the number of observed model outputs, and GP does not scale well with large parameter dimension either. Consequently, it has been challenging for GP to optimize black-box models that need to query many observations and/or have many parameters. To overcome the drawbacks of GP, in this study, we propose a general Bayesian optimization algorithm that employs a Neural Process (NP) as the surrogate model to perform black-box model optimization, namely, Neural Process for Bayesian Optimization (NPBO). In order to validate the benefits of NPBO, we compare NPBO with four benchmark approaches on a power system parameter optimization problem and a series of seven benchmark Bayesian optimization problems. The results show that the proposed NPBO performs better than the other four benchmark approaches on the power system parameter optimization problem and competitively on the seven benchmark problems.
MCFlow: Monte Carlo Flow Models for Data Imputation
Mar 27, 2020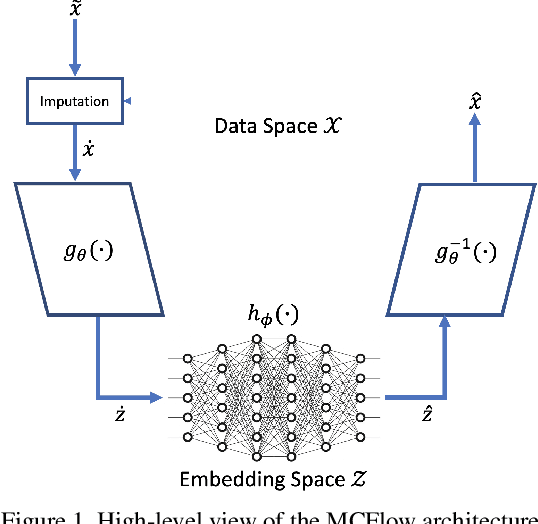
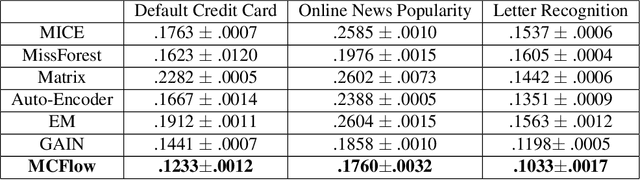
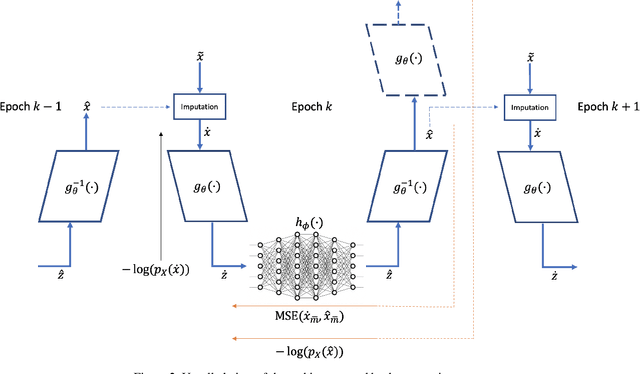
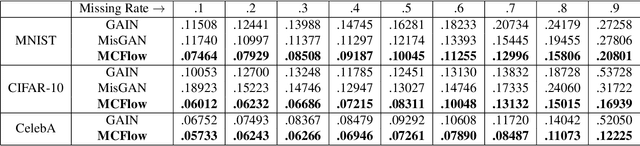
We consider the topic of data imputation, a foundational task in machine learning that addresses issues with missing data. To that end, we propose MCFlow, a deep framework for imputation that leverages normalizing flow generative models and Monte Carlo sampling. We address the causality dilemma that arises when training models with incomplete data by introducing an iterative learning scheme which alternately updates the density estimate and the values of the missing entries in the training data. We provide extensive empirical validation of the effectiveness of the proposed method on standard multivariate and image datasets, and benchmark its performance against state-of-the-art alternatives. We demonstrate that MCFlow is superior to competing methods in terms of the quality of the imputed data, as well as with regards to its ability to preserve the semantic structure of the data.
Medical Time Series Classification with Hierarchical Attention-based Temporal Convolutional Networks: A Case Study of Myotonic Dystrophy Diagnosis
Mar 28, 2019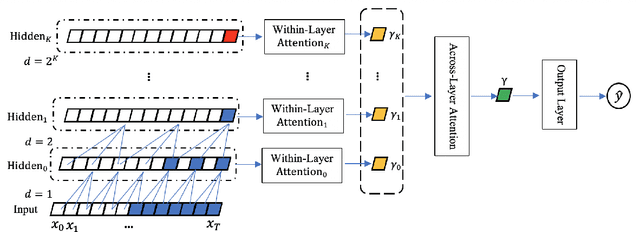
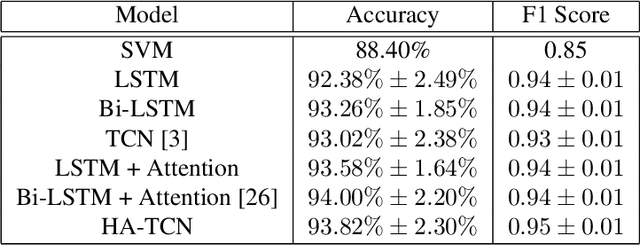
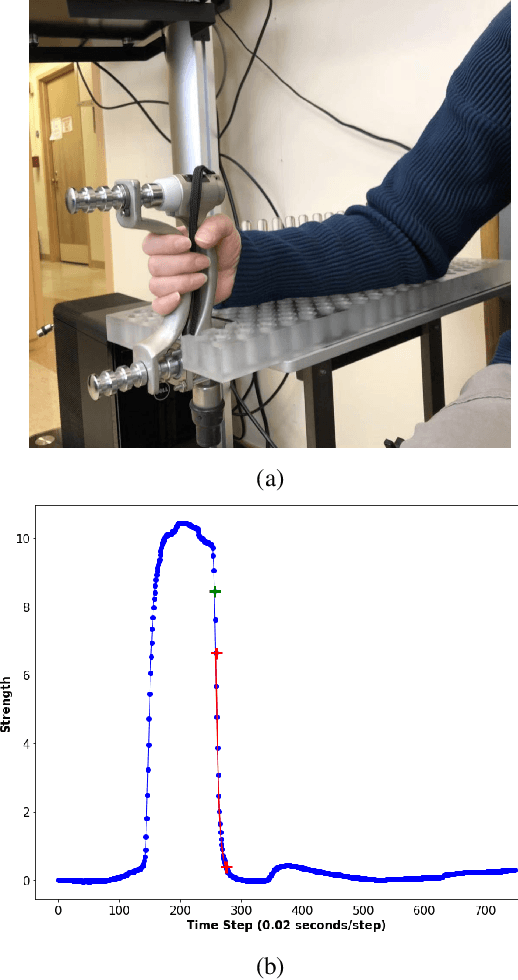
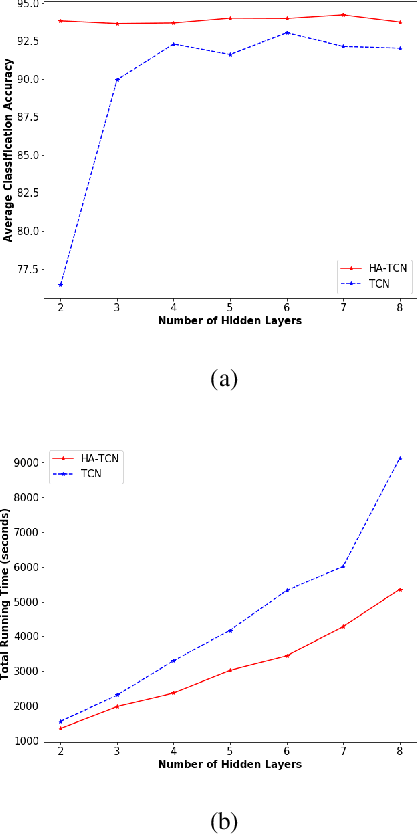
Myotonia, which refers to delayed muscle relaxation after contraction, is the main symptom of myotonic dystrophy patients. We propose a hierarchical attention-based temporal convolutional network (HA-TCN) for myotonic dystrohpy diagnosis from handgrip time series data, and introduce mechanisms that enable model explainability. We compare the performance of the HA-TCN model against that of benchmark TCN models, LSTM models with and without attention mechanisms, and SVM approaches with handcrafted features. In terms of classification accuracy and F1 score, we found all deep learning models have similar levels of performance, and they all outperform SVM. Further, the HA-TCN model outperforms its TCN counterpart with regards to computational efficiency regardless of network depth, and in terms of performance particularly when the number of hidden layers is small. Lastly, HA-TCN models can consistently identify relevant time series segments in the relaxation phase of the handgrip time series, and exhibit increased robustness to noise when compared to attention-based LSTM models.