 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Text-guided 3D Visual Grounding: Elements, Recent Advances, and Future Directions
Jun 09, 2024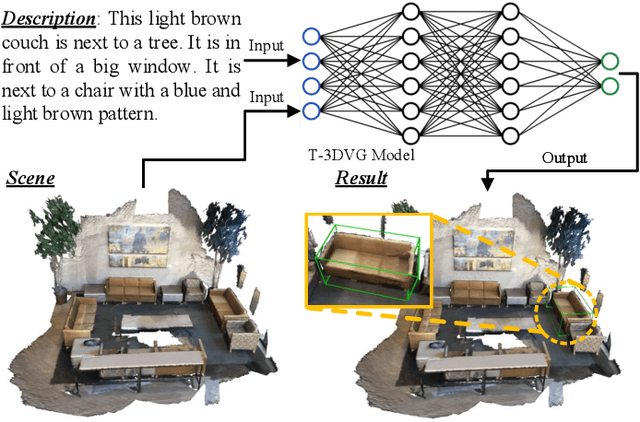



Text-guided 3D visual grounding (T-3DVG), which aims to locate a specific object that semantically corresponds to a language query from a complicated 3D scene, has drawn increasing attention in the 3D research community over the past few years. Compared to 2D visual grounding, this task presents great potential and challenges due to its closer proximity to the real world and the complexity of data collection and 3D point cloud source processing. In this survey, we attempt to provide a comprehensive overview of the T-3DVG progress, including its fundamental elements, recent research advances, and future research directions. To the best of our knowledge, this is the first systematic survey on the T-3DVG task. Specifically, we first provide a general structure of the T-3DVG pipeline with detailed components in a tutorial style, presenting a complete background overview. Then, we summarize the existing T-3DVG approaches into different categories and analyze their strengths and weaknesses. We also present the benchmark datasets and evaluation metrics to assess their performances. Finally, we discuss the potential limitations of existing T-3DVG and share some insights on several promising research directions. The latest papers are continually collected at https://github.com/liudaizong/Awesome-3D-Visual-Grounding.
Dense Object Grounding in 3D Scenes
Sep 05, 2023

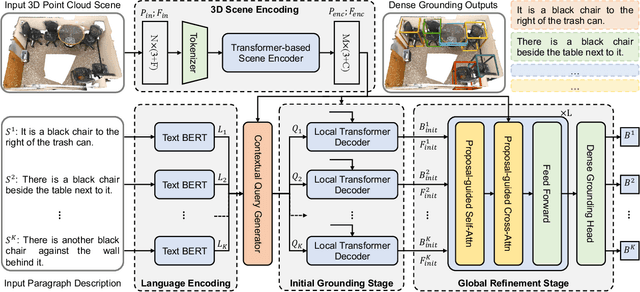

Localizing objects in 3D scenes according to the semantics of a given natural language is a fundamental yet important task in the field of multimedia understanding, which benefits various real-world applications such as robotics and autonomous driving. However, the majority of existing 3D object grounding methods are restricted to a single-sentence input describing an individual object, which cannot comprehend and reason more contextualized descriptions of multiple objects in more practical 3D cases. To this end, we introduce a new challenging task, called 3D Dense Object Grounding (3D DOG), to jointly localize multiple objects described in a more complicated paragraph rather than a single sentence. Instead of naively localizing each sentence-guided object independently, we found that dense objects described in the same paragraph are often semantically related and spatially located in a focused region of the 3D scene. To explore such semantic and spatial relationships of densely referred objects for more accurate localization, we propose a novel Stacked Transformer based framework for 3D DOG, named 3DOGSFormer. Specifically, we first devise a contextual query-driven local transformer decoder to generate initial grounding proposals for each target object. Then, we employ a proposal-guided global transformer decoder that exploits the local object features to learn their correlation for further refining initial grounding proposals. Extensive experiments on three challenging benchmarks (Nr3D, Sr3D, and ScanRefer) show that our proposed 3DOGSFormer outperforms state-of-the-art 3D single-object grounding methods and their dense-object variants by significant margins.