 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Text-guided 3D Visual Grounding: Elements, Recent Advances, and Future Directions
Paper and Code
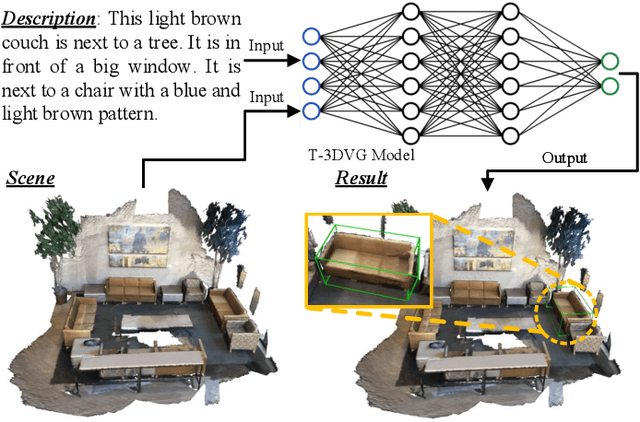



Text-guided 3D visual grounding (T-3DVG), which aims to locate a specific object that semantically corresponds to a language query from a complicated 3D scene, has drawn increasing attention in the 3D research community over the past few years. Compared to 2D visual grounding, this task presents great potential and challenges due to its closer proximity to the real world and the complexity of data collection and 3D point cloud source processing. In this survey, we attempt to provide a comprehensive overview of the T-3DVG progress, including its fundamental elements, recent research advances, and future research directions. To the best of our knowledge, this is the first systematic survey on the T-3DVG task. Specifically, we first provide a general structure of the T-3DVG pipeline with detailed components in a tutorial style, presenting a complete background overview. Then, we summarize the existing T-3DVG approaches into different categories and analyze their strengths and weaknesses. We also present the benchmark datasets and evaluation metrics to assess their performances. Finally, we discuss the potential limitations of existing T-3DVG and share some insights on several promising research directions. The latest papers are continually collected at https://github.com/liudaizong/Awesome-3D-Visual-Grounding.