 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategy Executability in Mathematical Reasoning: Leveraging Human-Model Differences for Effective Guidance
Feb 26, 2026Example-based guidance is widely used to improve mathematical reasoning at inference time, yet its effectiveness is highly unstable across problems and models-even when the guidance is correct and problem-relevant. We show that this instability arises from a previously underexplored gap between strategy usage-whether a reasoning strategy appears in successful solutions-and strategy executability-whether the strategy remains effective when instantiated as guidance for a target model. Through a controlled analysis of paired human-written and model-generated solutions, we identify a systematic dissociation between usage and executability: human- and model-derived strategies differ in structured, domain-dependent ways, leading to complementary strengths and consistent source-dependent reversals under guidance. Building on this diagnosis, we propose Selective Strategy Retrieval (SSR), a test-time framework that explicitly models executability by selectively retrieving and combining strategies using empirical, multi-route, source-aware signals. Across multiple mathematical reasoning benchmarks, SSR yields reliable and consistent improvements over direct solving, in-context learning, and single-source guidance, improving accuracy by up to $+13$ points on AIME25 and $+5$ points on Apex for compact reasoning models. Code and benchmark are publicly available at: https://github.com/lwd17/strategy-execute-pipeline.
Enhanced exemplar autoencoder with cycle consistency loss in any-to-one voice conversion
Apr 12, 2022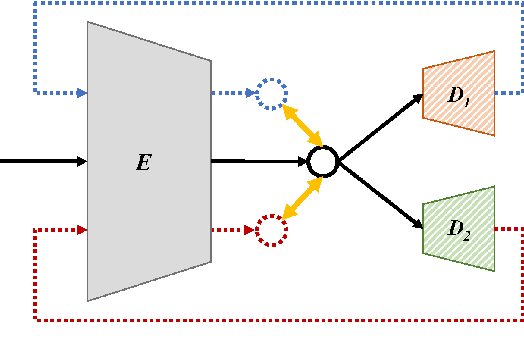

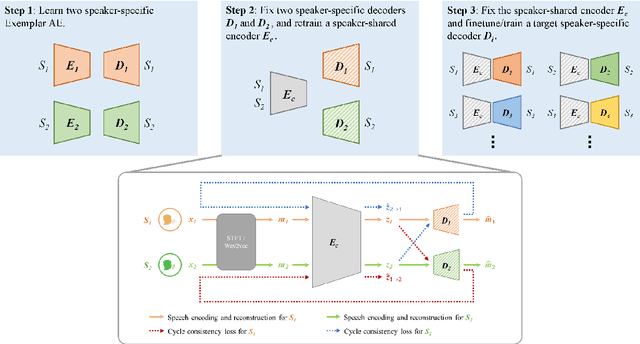
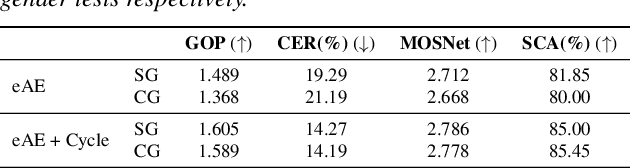
Recent research showed that an autoencoder trained with speech of a single speaker, called exemplar autoencoder (eAE), can be used for any-to-one voice conversion (VC). Compared to large-scale many-to-many models such as AutoVC, the eAE model is easy and fast in training, and may recover more details of the target speaker. To ensure VC quality, the latent code should represent and only represent content information. However, this is not easy to attain for eAE as it is unaware of any speaker variation in model training. To tackle the problem, we propose a simple yet effective approach based on a cycle consistency loss. Specifically, we train eAEs of multiple speakers with a shared encoder, and meanwhile encourage the speech reconstructed from any speaker-specific decoder to get a consistent latent code as the original speech when cycled back and encoded again. Experiments conducted on the AISHELL-3 corpus showed that this new approach improved the baseline eAE consistently. The source code and examples are available at the project page: http://project.cslt.org/.