 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Parametric Cost Function Approximation: A new approach for multistage stochastic programming
Jan 01, 2022

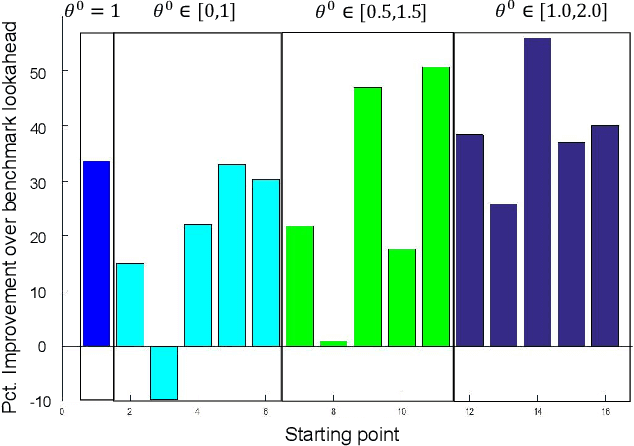
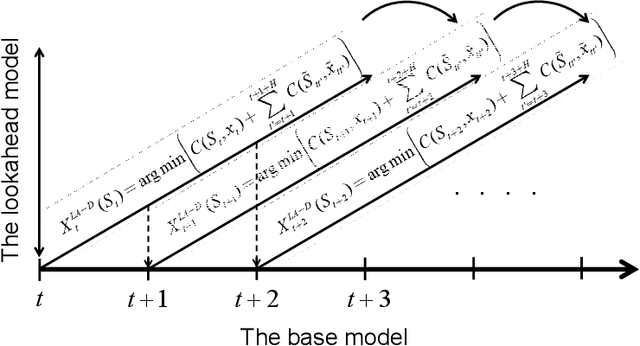
The most common approaches for solving multistage stochastic programming problems in the research literature have been to either use value functions ("dynamic programming") or scenario trees ("stochastic programming") to approximate the impact of a decision now on the future. By contrast, common industry practice is to use a deterministic approximation of the future which is easier to understand and solve, but which is criticized for ignoring uncertainty. We show that a parameterized version of a deterministic optimization model can be an effective way of handling uncertainty without the complexity of either stochastic programming or dynamic programming. We present the idea of a parameterized deterministic optimization model, and in particular a deterministic lookahead model, as a powerful strategy for many complex stochastic decision problems. This approach can handle complex, high-dimensional state variables, and avoids the usual approximations associated with scenario trees or value function approximations. Instead, it introduces the offline challenge of designing and tuning the parameterization. We illustrate the idea by using a series of application settings, and demonstrate its use in a nonstationary energy storage problem with rolling forecasts.
Optimal Learning for Sequential Decisions in Laboratory Experimentation
Apr 14, 2020
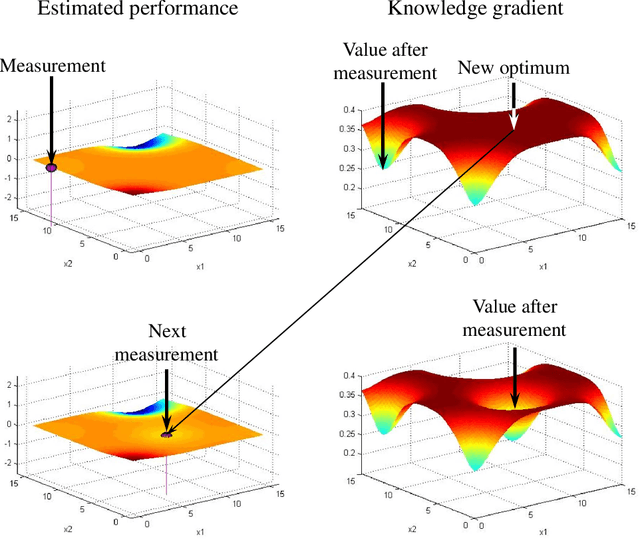
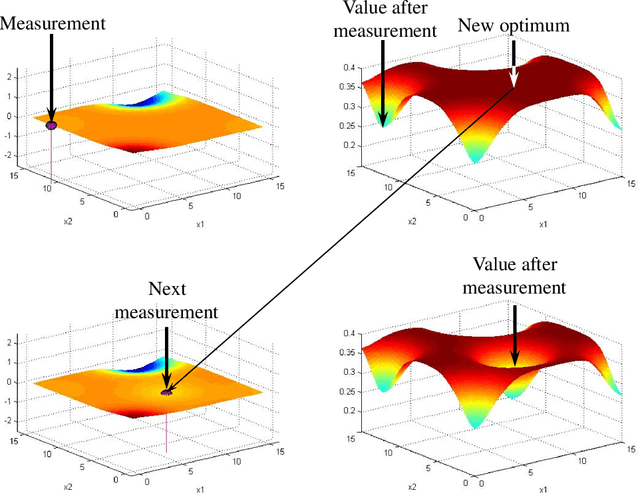
The process of discovery in the physical, biological and medical sciences can be painstakingly slow. Most experiments fail, and the time from initiation of research until a new advance reaches commercial production can span 20 years. This tutorial is aimed to provide experimental scientists with a foundation in the science of making decisions. Using numerical examples drawn from the experiences of the authors, the article describes the fundamental elements of any experimental learning problem. It emphasizes the important role of belief models, which include not only the best estimate of relationships provided by prior research, previous experiments and scientific expertise, but also the uncertainty in these relationships. We introduce the concept of a learning policy, and review the major categories of policies. We then introduce a policy, known as the knowledge gradient, that maximizes the value of information from each experiment. We bring out the importance of reducing uncertainty, and illustrate this process for different belief models.
On State Variables, Bandit Problems and POMDPs
Feb 14, 2020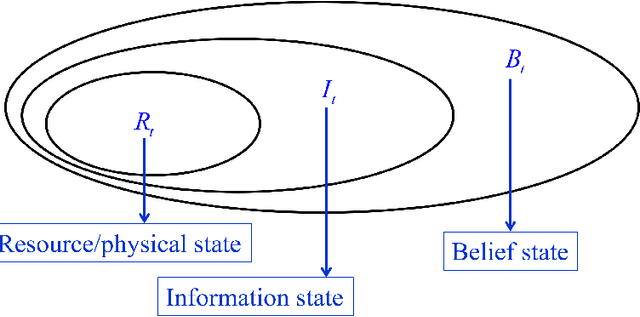


State variables are easily the most subtle dimension of sequential decision problems. This is especially true in the context of active learning problems (bandit problems") where decisions affect what we observe and learn. We describe our canonical framework that models {\it any} sequential decision problem, and present our definition of state variables that allows us to claim: Any properly modeled sequential decision problem is Markovian. We then present a novel two-agent perspective of partially observable Markov decision problems (POMDPs) that allows us to then claim: Any model of a real decision problem is (possibly) non-Markovian. We illustrate these perspectives using the context of observing and treating flu in a population, and provide examples of all four classes of policies in this setting. We close with an indication of how to extend this thinking to multiagent problems.
From Reinforcement Learning to Optimal Control: A unified framework for sequential decisions
Dec 18, 2019

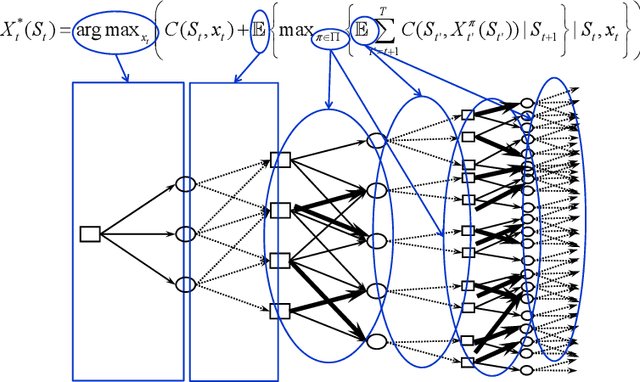
There are over 15 distinct communities that work in the general area of sequential decisions and information, often referred to as decisions under uncertainty or stochastic optimization. We focus on two of the most important fields: stochastic optimal control, with its roots in deterministic optimal control, and reinforcement learning, with its roots in Markov decision processes. Building on prior work, we describe a unified framework that covers all 15 different communities, and note the strong parallels with the modeling framework of stochastic optimal control. By contrast, we make the case that the modeling framework of reinforcement learning, inherited from discrete Markov decision processes, is quite limited. Our framework (and that of stochastic control) is based on the core problem of optimizing over policies. We describe four classes of policies that we claim are universal, and show that each of these two fields have, in their own way, evolved to include examples of each of these four classes.