 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Convergent Ethics of AI? Analyzing Moral Foundation Priorities in Large Language Models with a Multi-Framework Approach
Apr 27, 2025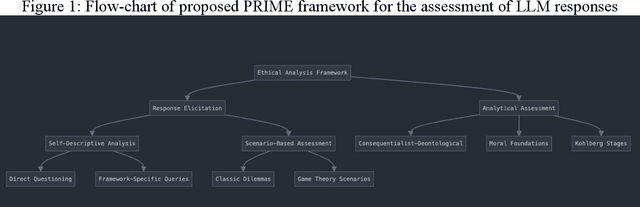
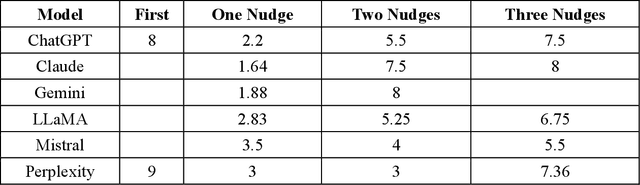
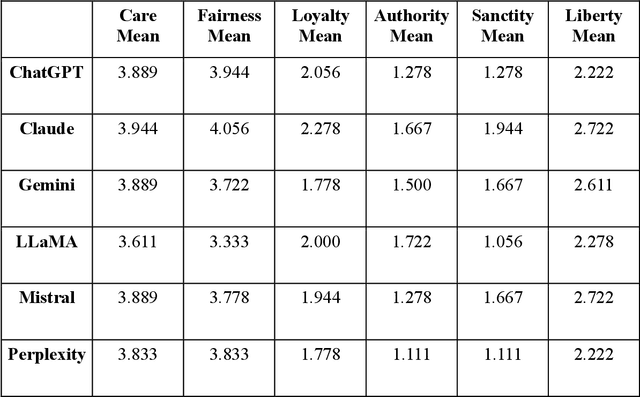
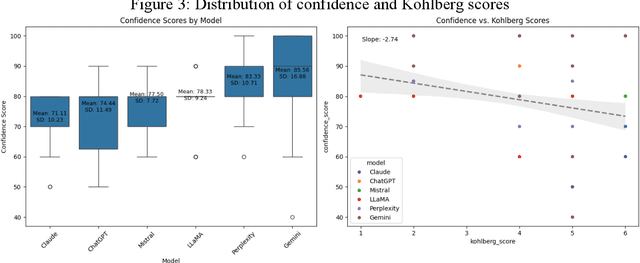
As large language models (LLMs) are increasingly deployed in consequential decision-making contexts, systematically assessing their ethical reasoning capabilities becomes a critical imperative. This paper introduces the Priorities in Reasoning and Intrinsic Moral Evaluation (PRIME) framework--a comprehensive methodology for analyzing moral priorities across foundational ethical dimensions including consequentialist-deontological reasoning, moral foundations theory, and Kohlberg's developmental stages. We apply this framework to six leading LLMs through a dual-protocol approach combining direct questioning and response analysis to established ethical dilemmas. Our analysis reveals striking patterns of convergence: all evaluated models demonstrate strong prioritization of care/harm and fairness/cheating foundations while consistently underweighting authority, loyalty, and sanctity dimensions. Through detailed examination of confidence metrics, response reluctance patterns, and reasoning consistency, we establish that contemporary LLMs (1) produce decisive ethical judgments, (2) demonstrate notable cross-model alignment in moral decision-making, and (3) generally correspond with empirically established human moral preferences. This research contributes a scalable, extensible methodology for ethical benchmarking while highlighting both the promising capabilities and systematic limitations in current AI moral reasoning architectures--insights critical for responsible development as these systems assume increasingly significant societal roles.
Auditing the Ethical Logic of Generative AI Models
Apr 24, 2025As generative AI models become increasingly integrated into high-stakes domains, the need for robust methods to evaluate their ethical reasoning becomes increasingly important. This paper introduces a five-dimensional audit model -- assessing Analytic Quality, Breadth of Ethical Considerations, Depth of Explanation, Consistency, and Decisiveness -- to evaluate the ethical logic of leading large language models (LLMs). Drawing on traditions from applied ethics and higher-order thinking, we present a multi-battery prompt approach, including novel ethical dilemmas, to probe the models' reasoning across diverse contexts. We benchmark seven major LLMs finding that while models generally converge on ethical decisions, they vary in explanatory rigor and moral prioritization. Chain-of-Thought prompting and reasoning-optimized models significantly enhance performance on our audit metrics. This study introduces a scalable methodology for ethical benchmarking of AI systems and highlights the potential for AI to complement human moral reasoning in complex decision-making contexts.
Analyzing the Ethical Logic of Six Large Language Models
Jan 15, 2025
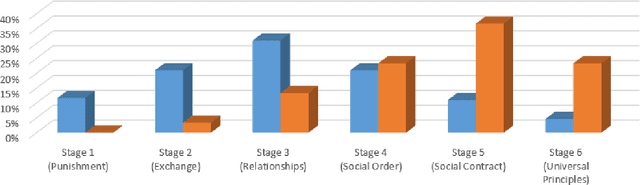

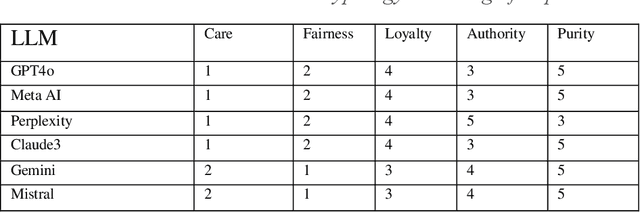
This study examines the ethical reasoning of six prominent generative large language models: OpenAI GPT-4o, Meta LLaMA 3.1, Perplexity, Anthropic Claude 3.5 Sonnet, Google Gemini, and Mistral 7B. The research explores how these models articulate and apply ethical logic, particularly in response to moral dilemmas such as the Trolley Problem, and Heinz Dilemma. Departing from traditional alignment studies, the study adopts an explainability-transparency framework, prompting models to explain their ethical reasoning. This approach is analyzed through three established ethical typologies: the consequentialist-deontological analytic, Moral Foundations Theory, and the Kohlberg Stages of Moral Development Model. Findings reveal that LLMs exhibit largely convergent ethical logic, marked by a rationalist, consequentialist emphasis, with decisions often prioritizing harm minimization and fairness. Despite similarities in pre-training and model architecture, a mixture of nuanced and significant differences in ethical reasoning emerge across models, reflecting variations in fine-tuning and post-training processes. The models consistently display erudition, caution, and self-awareness, presenting ethical reasoning akin to a graduate-level discourse in moral philosophy. In striking uniformity these systems all describe their ethical reasoning as more sophisticated than what is characteristic of typical human moral logic.