 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying relationships between drugs and medical conditions: winning experience in the Challenge 2 of the OMOP 2010 Cup
Oct 04, 2011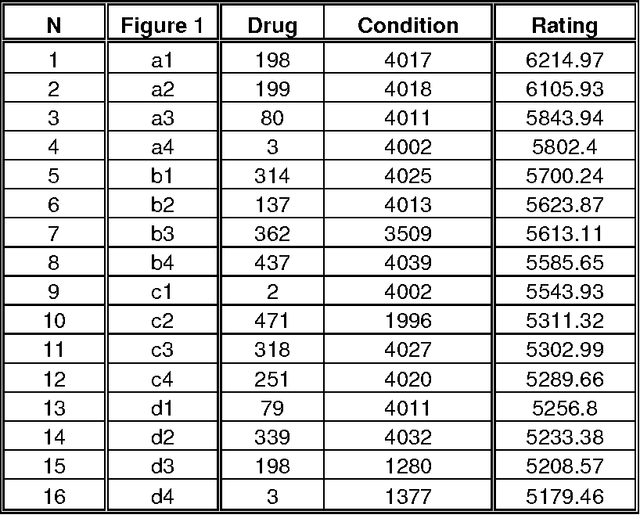
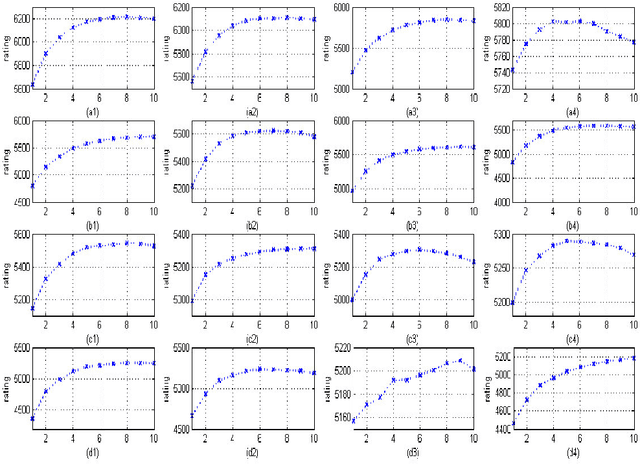
There is a growing interest in using a longitudinal observational databases to detect drug safety signal. In this paper we present a novel method, which we used online during the OMOP Cup. We consider homogeneous ensembling, which is based on random re-sampling (known, also, as bagging) as a main innovation compared to the previous publications in the related field. This study is based on a very large simulated database of the 10 million patients records, which was created by the Observational Medical Outcomes Partnership (OMOP). Compared to the traditional classification problem, the given data are unlabelled. The objective of this study is to discover hidden associations between drugs and conditions. The main idea of the approach, which we used during the OMOP Cup is to compare the numbers of observed and expected patterns. This comparison may be organised in several different ways, and the outcomes (base learners) may be quite different as well. It is proposed to construct the final decision function as an ensemble of the base learners. Our method was recognised formally by the Organisers of the OMOP Cup as a top performing method for the Challenge N2.
On the Evaluation Criterions for the Active Learning Processes
Aug 02, 2011



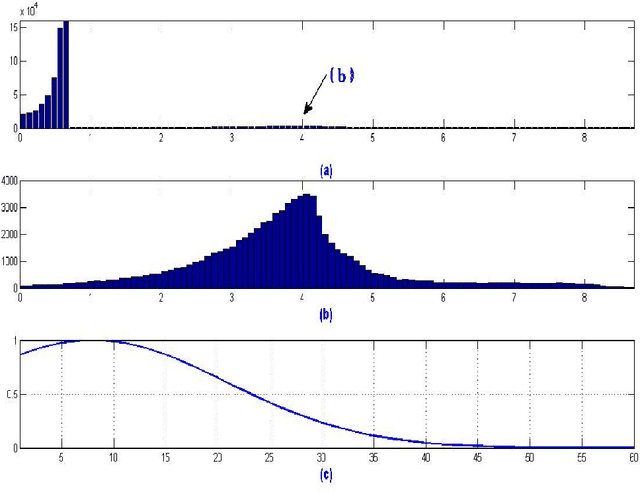
In many data mining applications collection of sufficiently large datasets is the most time consuming and expensive. On the other hand, industrial methods of data collection create huge databases, and make difficult direct applications of the advanced machine learning algorithms. To address the above problems, we consider active learning (AL), which may be very efficient either for the experimental design or for the data filtering. In this paper we demonstrate using the online evaluation opportunity provided by the AL Challenge that quite competitive results may be produced using a small percentage of the available data. Also, we present several alternative criteria, which may be useful for the evaluation of the active learning processes. The author of this paper attended special presentation in Barcelona, where results of the WCCI 2010 AL Challenge were discussed.
A Very Fast Algorithm for Matrix Factorization
Nov 02, 2010



We present a very fast algorithm for general matrix factorization of a data matrix for use in the statistical analysis of high-dimensional data via latent factors. Such data are prevalent across many application areas and generate an ever-increasing demand for methods of dimension reduction in order to undertake the statistical analysis of interest. Our algorithm uses a gradient-based approach which can be used with an arbitrary loss function provided the latter is differentiable. The speed and effectiveness of our algorithm for dimension reduction is demonstrated in the context of supervised classification of some real high-dimensional data sets from the bioinformatics literature.
Strong Consistency of Prototype Based Clustering in Probabilistic Space
Apr 19, 2010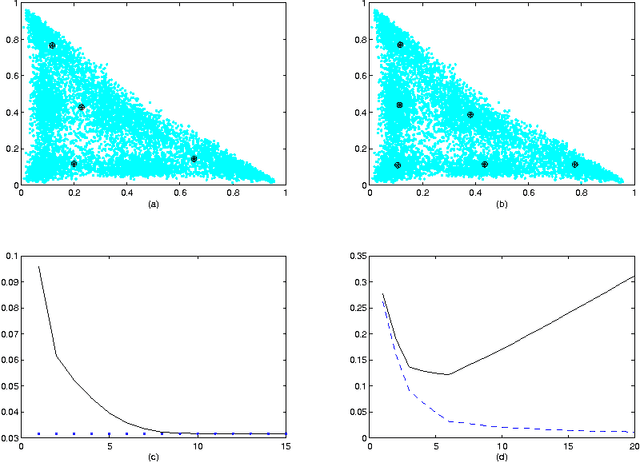
In this paper we formulate in general terms an approach to prove strong consistency of the Empirical Risk Minimisation inductive principle applied to the prototype or distance based clustering. This approach was motivated by the Divisive Information-Theoretic Feature Clustering model in probabilistic space with Kullback-Leibler divergence which may be regarded as a special case within the Clustering Minimisation framework. Also, we propose clustering regularization restricting creation of additional clusters which are not significant or are not essentially different comparing with existing clusters.