 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaRU: A Manga Retrieval and Understanding System Connecting Vision and Language
Oct 22, 2023Manga, a widely celebrated Japanese comic art form, is renowned for its diverse narratives and distinct artistic styles. However, the inherently visual and intricate structure of Manga, which comprises images housing multiple panels, poses significant challenges for content retrieval. To address this, we present MaRU (Manga Retrieval and Understanding), a multi-staged system that connects vision and language to facilitate efficient search of both dialogues and scenes within Manga frames. The architecture of MaRU integrates an object detection model for identifying text and frame bounding boxes, a Vision Encoder-Decoder model for text recognition, a text encoder for embedding text, and a vision-text encoder that merges textual and visual information into a unified embedding space for scene retrieval. Rigorous evaluations reveal that MaRU excels in end-to-end dialogue retrieval and exhibits promising results for scene retrieval.
A Streaming Approach For Efficient Batched Beam Search
Oct 06, 2020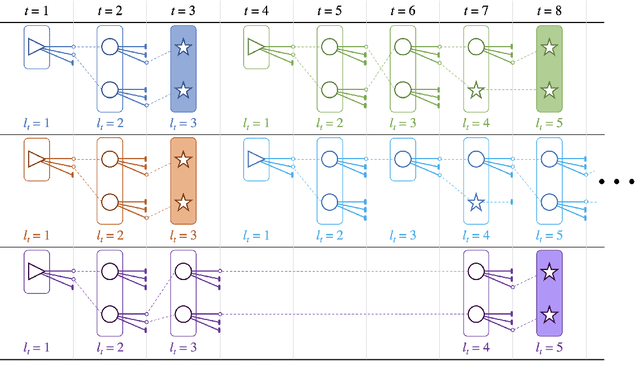


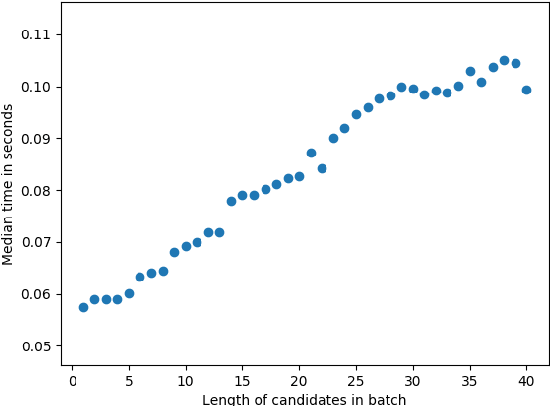
We propose an efficient batching strategy for variable-length decoding on GPU architectures. During decoding, when candidates terminate or are pruned according to heuristics, our streaming approach periodically "refills" the batch before proceeding with a selected subset of candidates. We apply our method to variable-width beam search on a state-of-the-art machine translation model. Our method decreases runtime by up to 71% compared to a fixed-width beam search baseline and 17% compared to a variable-width baseline, while matching baselines' BLEU. Finally, experiments show that our method can speed up decoding in other domains, such as semantic and syntactic parsing.