Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Streaming Approach For Efficient Batched Beam Search
Paper and Code
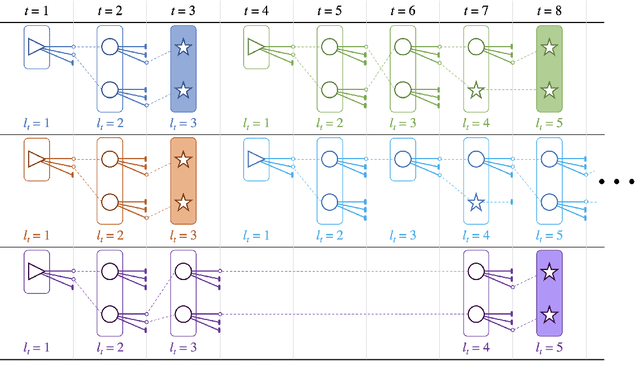


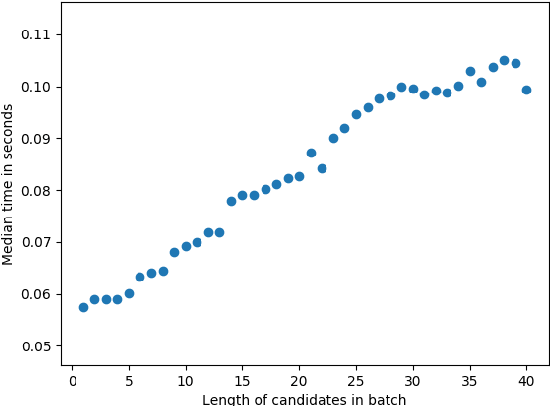
We propose an efficient batching strategy for variable-length decoding on GPU architectures. During decoding, when candidates terminate or are pruned according to heuristics, our streaming approach periodically "refills" the batch before proceeding with a selected subset of candidates. We apply our method to variable-width beam search on a state-of-the-art machine translation model. Our method decreases runtime by up to 71% compared to a fixed-width beam search baseline and 17% compared to a variable-width baseline, while matching baselines' BLEU. Finally, experiments show that our method can speed up decoding in other domains, such as semantic and syntactic parsing.
* EMNLP 2020
View paper on