 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking use of supercomputers in financial machine learning
Mar 01, 2022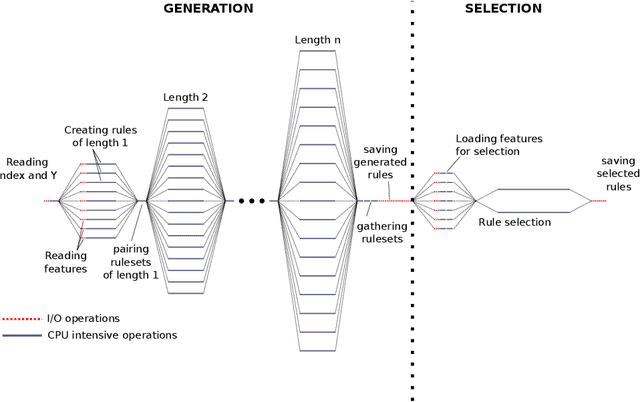

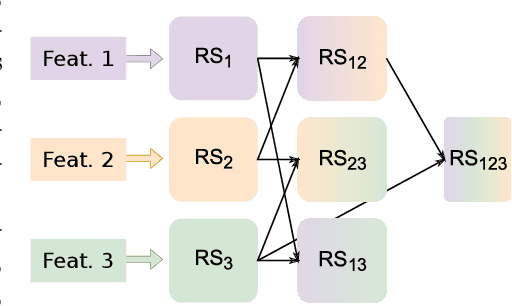
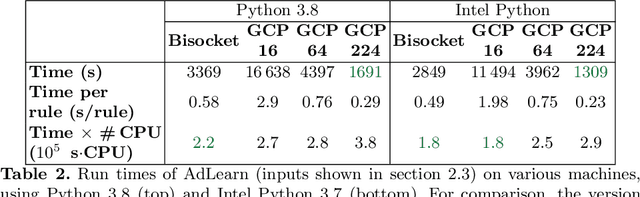
This article is the result of a collaboration between Fujitsu and Advestis. This collaboration aims at refactoring and running an algorithm based on systematic exploration producing investment recommendations on a high-performance computer of the Fugaku, to see whether a very high number of cores could allow for a deeper exploration of the data compared to a cloud machine, hopefully resulting in better predictions. We found that an increase in the number of explored rules results in a net increase in the predictive performance of the final ruleset. Also, in the particular case of this study, we found that using more than around 40 cores does not bring a significant computation time gain. However, the origin of this limitation is explained by a threshold-based search heuristic used to prune the search space. We have evidence that for similar data sets with less restrictive thresholds, the number of cores actually used could very well be much higher, allowing parallelization to have a much greater effect.
A rigorous method to compare interpretability of rule-based algorithms
Apr 06, 2020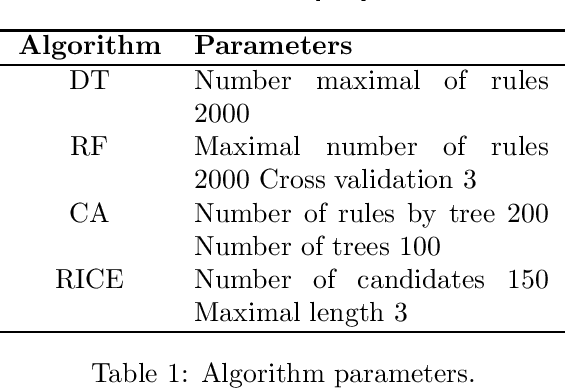

Interpretability is becoming increasingly important in predictive model analysis. Unfortunately, as mentioned by many authors, there is still no consensus on that idea. The aim of this article is to propose a rigorous mathematical definition of the concept of interpretability, allowing fair comparisons between any rule-based algorithms. This definition is built from three notions, each of which being quantitatively measured by a simple formula: predictivity, stability and simplicity. While predictivity has been widely studied to measure the accuracy of predictive algorithms, stability is based on the Dice-Sorensen index to compare two sets of rules generated by an algorithm using two independent samples. Simplicity is based on the sum of the length of the rules deriving from the generated model. The final objective measure of the interpretability of any rule-based algorithm ends up as a weighted sum of the three aforementioned concepts. This paper concludes with the comparison of the interpretability between four rule-based algorithms.
ESG investments: Filtering versus machine learning approaches
Feb 18, 2020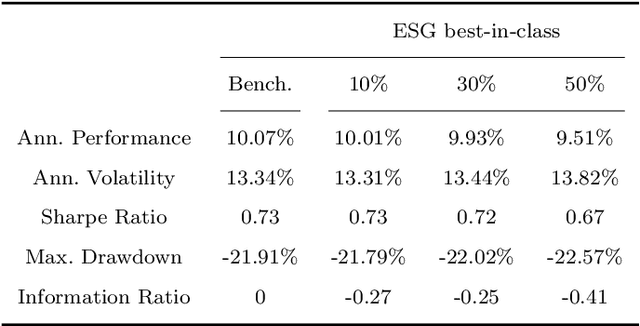
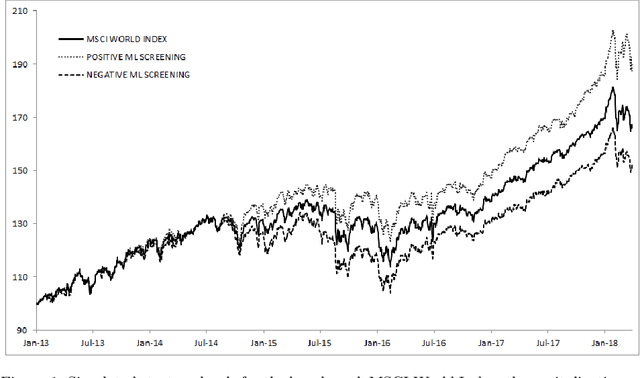
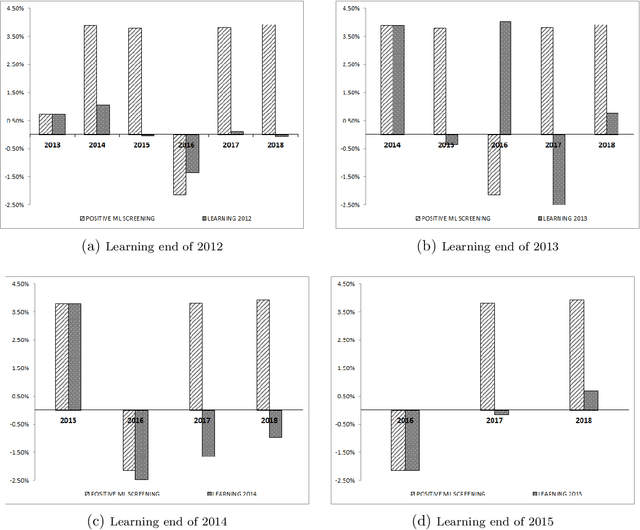
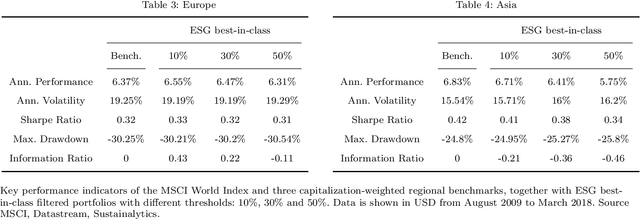
We designed a machine learning algorithm that identifies patterns between ESG profiles and financial performances for companies in a large investment universe. The algorithm consists of regularly updated sets of rules that map regions into the high-dimensional space of ESG features to excess return predictions. The final aggregated predictions are transformed into scores which allow us to design simple strategies that screen the investment universe for stocks with positive scores. By linking the ESG features with financial performances in a non-linear way, our strategy based upon our machine learning algorithm turns out to be an efficient stock picking tool, which outperforms classic strategies that screen stocks according to their ESG ratings, as the popular best-in-class approach. Our paper brings new ideas in the growing field of financial literature that investigates the links between ESG behavior and the economy. We show indeed that there is clearly some form of alpha in the ESG profile of a company, but that this alpha can be accessed only with powerful, non-linear techniques such as machine learning.
Consistent Regression using Data-Dependent Coverings
Jul 04, 2019
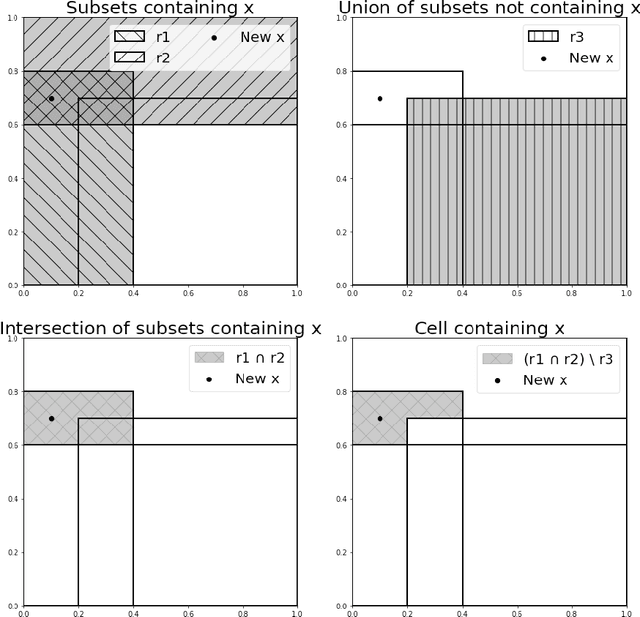
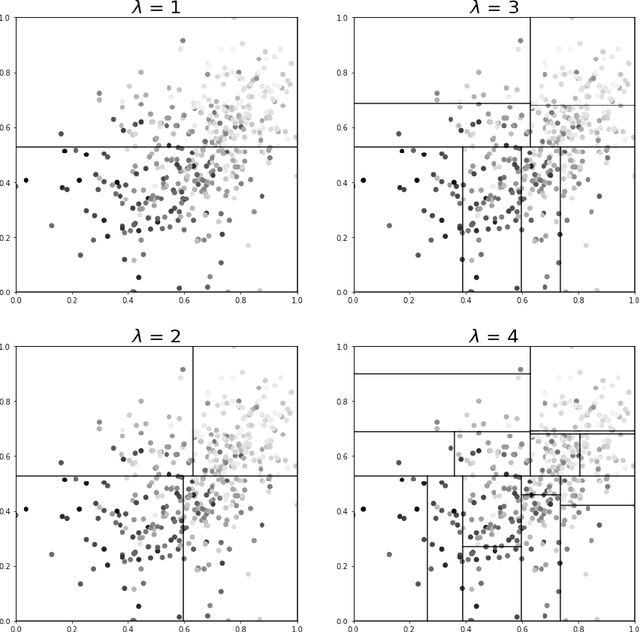
In this paper, we introduce a novel method to generate interpretable regression function estimators. The idea is based on called data-dependent coverings. The aim is to extract from the data a covering of the feature space instead of a partition. The estimator predicts the empirical conditional expectation over the cells of the partitions generated from the coverings. Thus, such estimator has the same form as those issued from data-dependent partitioning algorithms. We give sufficient conditions to ensure the consistency, avoiding the sufficient condition of shrinkage of the cells that appears in the former literature. Doing so, we reduce the number of covering elements. We show that such coverings are interpretable and each element of the covering is tagged as significant or insignificant. The proof of the consistency is based on a control of the error of the empirical estimation of conditional expectations which is interesting on its own.
Rule Induction Partitioning Estimator
Jul 12, 2018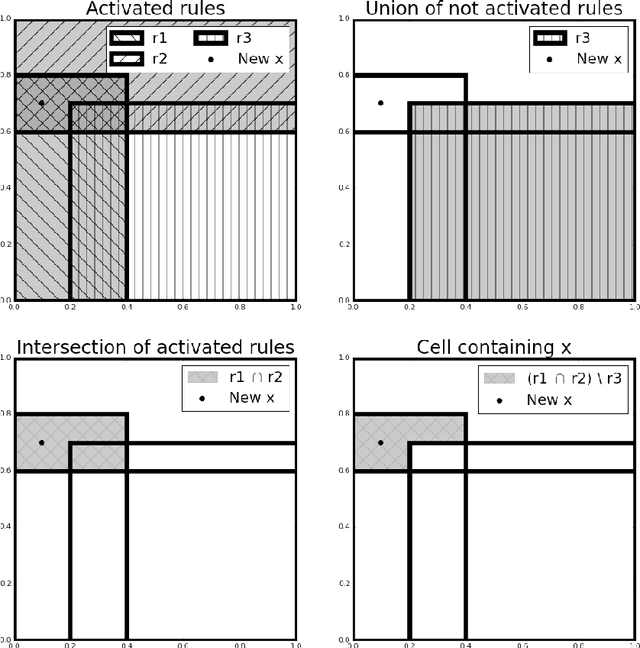
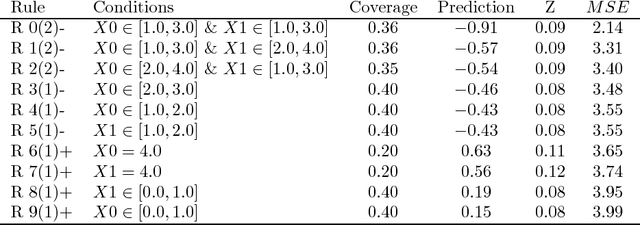
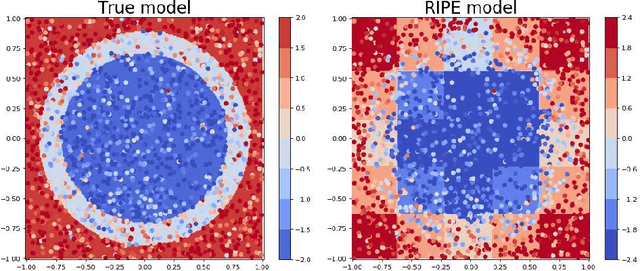
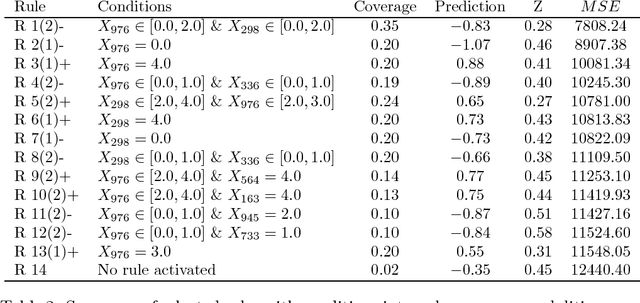
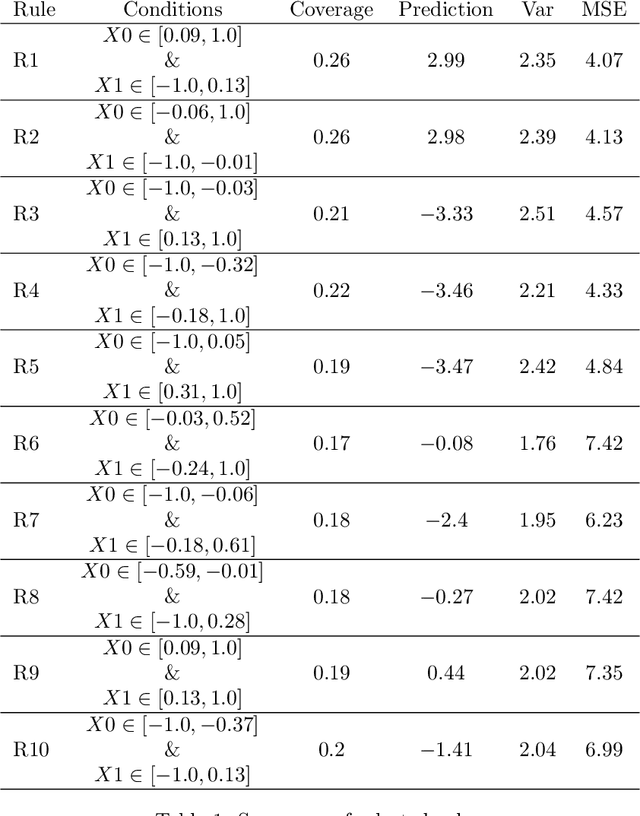
RIPE is a novel deterministic and easily understandable prediction algorithm developed for continuous and discrete ordered data. It infers a model, from a sample, to predict and to explain a real variable $Y$ given an input variable $X \in \mathcal X$ (features). The algorithm extracts a sparse set of hyperrectangles $\mathbf r \subset \mathcal X$, which can be thought of as rules of the form If-Then. This set is then turned into a partition of the features space $\mathcal X$ of which each cell is explained as a list of rules with satisfied their If conditions. The process of RIPE is illustrated on simulated datasets and its efficiency compared with that of other usual algorithms.