 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoxNTF: A New Approach for Joint Clustering and Prediction in Survival Analysis
Jun 06, 2025The interpretation of the results of survival analysis often benefits from latent factor representations of baseline covariates. However, existing methods, such as Nonnegative Matrix Factorization (NMF), do not incorporate survival information, limiting their predictive power. We present CoxNTF, a novel approach that uses non-negative tensor factorization (NTF) to derive meaningful latent representations that are closely associated with survival outcomes. CoxNTF constructs a weighted covariate tensor in which survival probabilities derived from the Coxnet model are used to guide the tensorization process. Our results show that CoxNTF achieves survival prediction performance comparable to using Coxnet with the original covariates, while providing a structured and interpretable clustering framework. In addition, the new approach effectively handles feature redundancy, making it a powerful tool for joint clustering and prediction in survival analysis.
Time to Market Reduction for Hydrogen Fuel Cell Stacks using Generative Adversarial Networks
Dec 22, 2022To face the dependency on fossil fuels and limit carbon emissions, fuel cells are a very promising technology and appear to be a key candidate to tackle the increase of the energy demand and promote the energy transition. To meet future needs for both transport and stationary applications, the time to market of fuel cell stacks must be drastically reduced. Here, a new concept to shorten their development time by introducing a disruptive and highefficiency data augmentation approach based on artificial intelligence is presented. Our results allow reducing the testing time before introducing a product on the market from a thousand to a few hours. The innovative concept proposed here can support engineering and research tasks during the fuel cell development process to achieve decreased development costs alongside a reduced time to market.
Making use of supercomputers in financial machine learning
Mar 01, 2022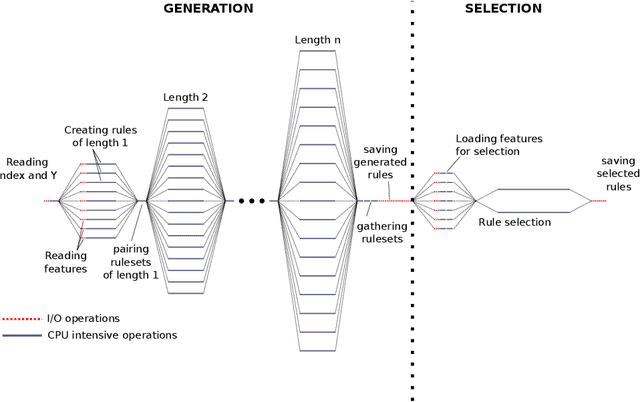

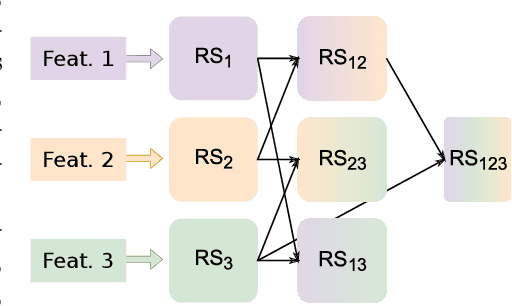
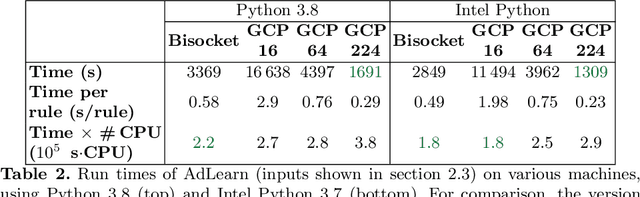
This article is the result of a collaboration between Fujitsu and Advestis. This collaboration aims at refactoring and running an algorithm based on systematic exploration producing investment recommendations on a high-performance computer of the Fugaku, to see whether a very high number of cores could allow for a deeper exploration of the data compared to a cloud machine, hopefully resulting in better predictions. We found that an increase in the number of explored rules results in a net increase in the predictive performance of the final ruleset. Also, in the particular case of this study, we found that using more than around 40 cores does not bring a significant computation time gain. However, the origin of this limitation is explained by a threshold-based search heuristic used to prune the search space. We have evidence that for similar data sets with less restrictive thresholds, the number of cores actually used could very well be much higher, allowing parallelization to have a much greater effect.
ESG investments: Filtering versus machine learning approaches
Feb 18, 2020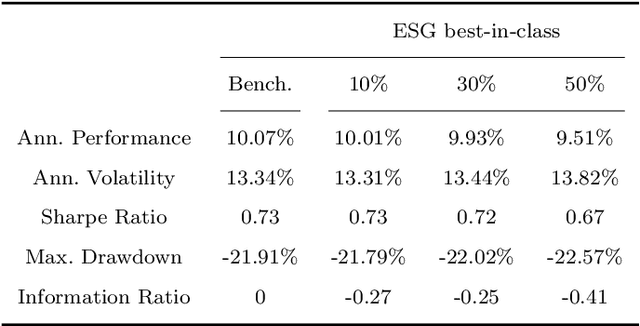
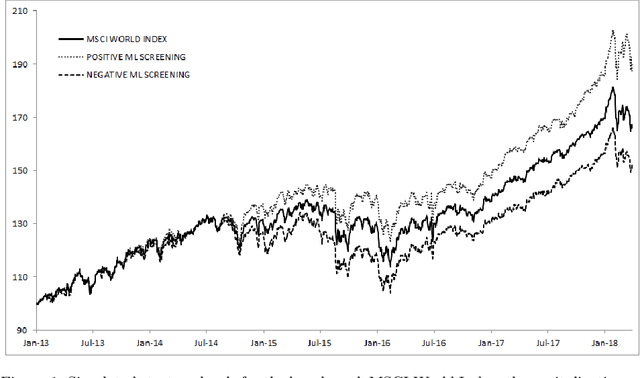
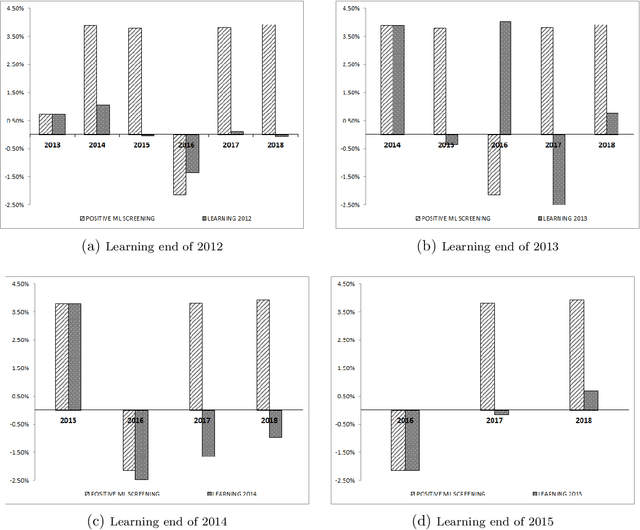
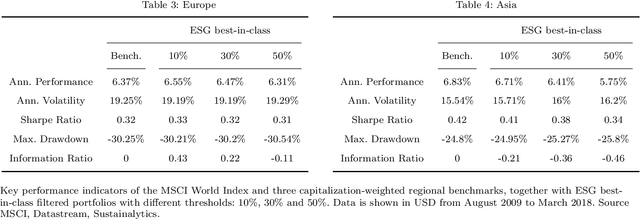
We designed a machine learning algorithm that identifies patterns between ESG profiles and financial performances for companies in a large investment universe. The algorithm consists of regularly updated sets of rules that map regions into the high-dimensional space of ESG features to excess return predictions. The final aggregated predictions are transformed into scores which allow us to design simple strategies that screen the investment universe for stocks with positive scores. By linking the ESG features with financial performances in a non-linear way, our strategy based upon our machine learning algorithm turns out to be an efficient stock picking tool, which outperforms classic strategies that screen stocks according to their ESG ratings, as the popular best-in-class approach. Our paper brings new ideas in the growing field of financial literature that investigates the links between ESG behavior and the economy. We show indeed that there is clearly some form of alpha in the ESG profile of a company, but that this alpha can be accessed only with powerful, non-linear techniques such as machine learning.