 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multivariate Extreme Value Theory Approach to Anomaly Clustering and Visualization
Jul 17, 2019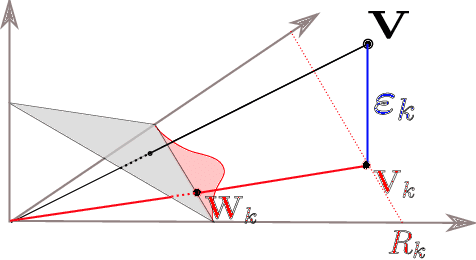



In a wide variety of situations, anomalies in the behaviour of a complex system, whose health is monitored through the observation of a random vector X = (X1,. .. , X d) valued in R d , correspond to the simultaneous occurrence of extreme values for certain subgroups $\alpha$ $\subset$ {1,. .. , d} of variables Xj. Under the heavy-tail assumption, which is precisely appropriate for modeling these phenomena, statistical methods relying on multivariate extreme value theory have been developed in the past few years for identifying such events/subgroups. This paper exploits this approach much further by means of a novel mixture model that permits to describe the distribution of extremal observations and where the anomaly type $\alpha$ is viewed as a latent variable. One may then take advantage of the model by assigning to any extreme point a posterior probability for each anomaly type $\alpha$, defining implicitly a similarity measure between anomalies. It is explained at length how the latter permits to cluster extreme observations and obtain an informative planar representation of anomalies using standard graph-mining tools. The relevance and usefulness of the clustering and 2-d visual display thus designed is illustrated on simulated datasets and on real observations as well, in the aeronautics application domain.
Anomaly detection with Wasserstein GAN
Dec 11, 2018



Generative adversarial networks are a class of generative algorithms that have been widely used to produce state-of-the-art samples. In this paper, we investigate GAN to perform anomaly detection on time series dataset. In order to achieve this goal, a bibliography is made focusing on theoretical properties of GAN and GAN used for anomaly detection. A Wasserstein GAN has been chosen to learn the representation of normal data distribution and a stacked encoder with the generator performs the anomaly detection. W-GAN with encoder seems to produce state of the art anomaly detection scores on MNIST dataset and we investigate its usage on multi-variate time series.
Calibration of One-Class SVM for MV set estimation
Aug 30, 2015
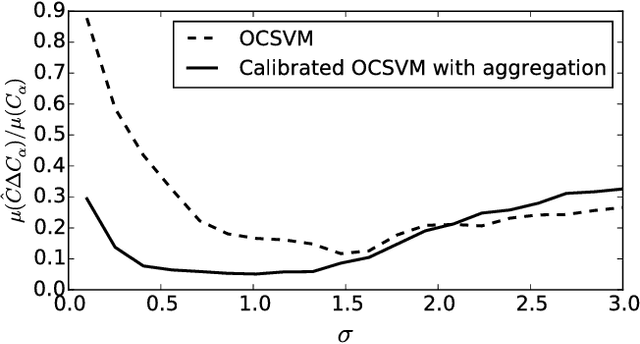


A general approach for anomaly detection or novelty detection consists in estimating high density regions or Minimum Volume (MV) sets. The One-Class Support Vector Machine (OCSVM) is a state-of-the-art algorithm for estimating such regions from high dimensional data. Yet it suffers from practical limitations. When applied to a limited number of samples it can lead to poor performance even when picking the best hyperparameters. Moreover the solution of OCSVM is very sensitive to the selection of hyperparameters which makes it hard to optimize in an unsupervised setting. We present a new approach to estimate MV sets using the OCSVM with a different choice of the parameter controlling the proportion of outliers. The solution function of the OCSVM is learnt on a training set and the desired probability mass is obtained by adjusting the offset on a test set to prevent overfitting. Models learnt on different train/test splits are then aggregated to reduce the variance induced by such random splits. Our approach makes it possible to tune the hyperparameters automatically and obtain nested set estimates. Experimental results show that our approach outperforms the standard OCSVM formulation while suffering less from the curse of dimensionality than kernel density estimates. Results on actual data sets are also presented.