 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1-bit Matrix Completion: PAC-Bayesian Analysis of a Variational Approximation
Apr 14, 2016



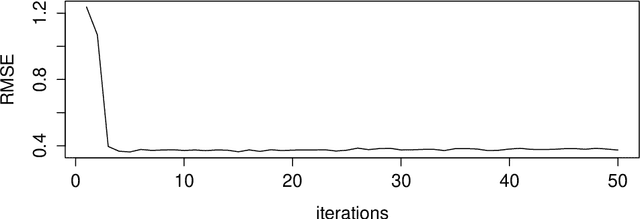
Due to challenging applications such as collaborative filtering, the matrix completion problem has been widely studied in the past few years. Different approaches rely on different structure assumptions on the matrix in hand. Here, we focus on the completion of a (possibly) low-rank matrix with binary entries, the so-called 1-bit matrix completion problem. Our approach relies on tools from machine learning theory: empirical risk minimization and its convex relaxations. We propose an algorithm to compute a variational approximation of the pseudo-posterior. Thanks to the convex relaxation, the corresponding minimization problem is bi-convex, and thus the method behaves well in practice. We also study the performance of this variational approximation through PAC-Bayesian learning bounds. On the contrary to previous works that focused on upper bounds on the estimation error of M with various matrix norms, we are able to derive from this analysis a PAC bound on the prediction error of our algorithm. We focus essentially on convex relaxation through the hinge loss, for which we present the complete analysis, a complete simulation study and a test on the MovieLens data set. However, we also discuss a variational approximation to deal with the logistic loss.
Bayesian matrix completion: prior specification
Oct 22, 2014

Low-rank matrix estimation from incomplete measurements recently received increased attention due to the emergence of several challenging applications, such as recommender systems; see in particular the famous Netflix challenge. While the behaviour of algorithms based on nuclear norm minimization is now well understood, an as yet unexplored avenue of research is the behaviour of Bayesian algorithms in this context. In this paper, we briefly review the priors used in the Bayesian literature for matrix completion. A standard approach is to assign an inverse gamma prior to the singular values of a certain singular value decomposition of the matrix of interest; this prior is conjugate. However, we show that two other types of priors (again for the singular values) may be conjugate for this model: a gamma prior, and a discrete prior. Conjugacy is very convenient, as it makes it possible to implement either Gibbs sampling or Variational Bayes. Interestingly enough, the maximum a posteriori for these different priors is related to the nuclear norm minimization problems. We also compare all these priors on simulated datasets, and on the classical MovieLens and Netflix datasets.