 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Aware Rate-Distortion Limits for Task-Oriented Source Coding
Feb 13, 2026Task-Oriented Source Coding (TOSC) has emerged as a paradigm for efficient visual data communication in machine-centric inference systems, where bitrate, latency, and task performance must be jointly optimized under resource constraints. While recent works have proposed rate-distortion bounds for coding for machines, these results often rely on strong assumptions on task identifiability and neglect the impact of deployed task models. In this work, we revisit the fundamental limits of single-TOSC through the lens of indirect rate-distortion theory. We highlight the conditions under which existing rate-distortion bounds are achievable and show their limitations in realistic settings. We then introduce task model-aware rate-distortion bounds that account for task model suboptimality and architectural constraints. Experiments on standard classification benchmarks confirm that current learned TOSC schemes operate far from these limits, highlighting transmitter-side complexity as a key bottleneck.
Model-based Neural Data Augmentation for sub-wavelength Radio Localization
Jun 05, 2025The increasing deployment of large antenna arrays at base stations has significantly improved the spatial resolution and localization accuracy of radio-localization methods. However, traditional signal processing techniques struggle in complex radio environments, particularly in scenarios dominated by non line of sight (NLoS) propagation paths, resulting in degraded localization accuracy. Recent developments in machine learning have facilitated the development of machine learning-assisted localization techniques, enhancing localization accuracy in complex radio environments. However, these methods often involve substantial computational complexity during both the training and inference phases. This work extends the well-established fingerprinting-based localization framework by simultaneously reducing its memory requirements and improving its accuracy. Specifically, a model-based neural network is used to learn the location-to-channel mapping, and then serves as a generative neural channel model. This generative model augments the fingerprinting comparison dictionary while reducing the memory requirements. The proposed method outperforms fingerprinting baselines by achieving sub-wavelength localization accuracy, even in NLoS environments. Remarkably, it offers an improvement by several orders of magnitude in localization accuracy, while simultaneously reducing memory requirements by an order of magnitude compared to classical fingerprinting methods.
Differentiable High-Order Markov Models for Spectrum Prediction
Nov 30, 2024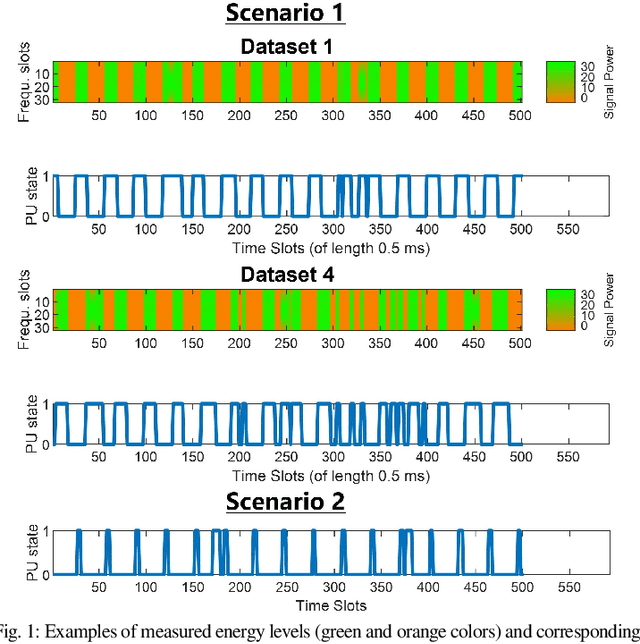
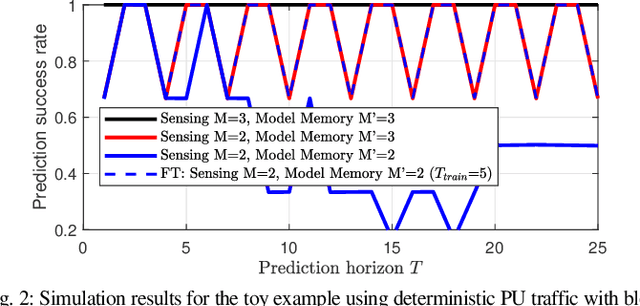
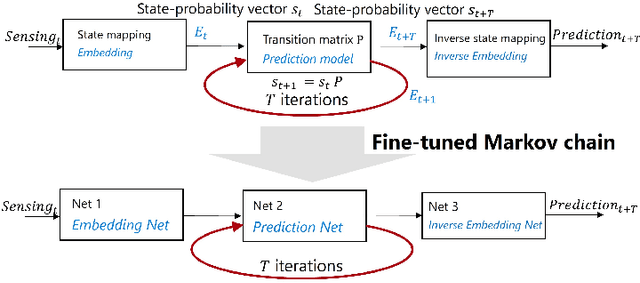
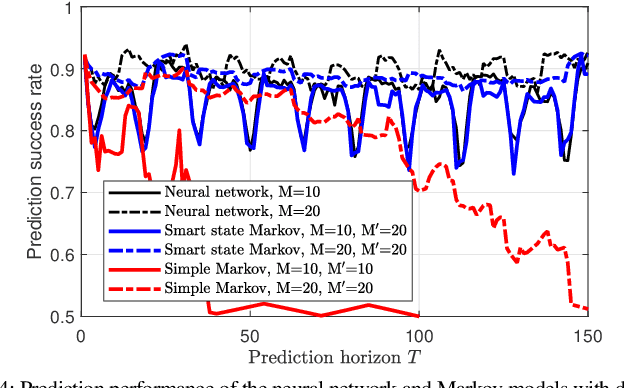
The advent of deep learning and recurrent neural networks revolutionized the field of time-series processing. Therefore, recent research on spectrum prediction has focused on the use of these tools. However, spectrum prediction, which involves forecasting wireless spectrum availability, is an older field where many "classical" tools were considered around the 2010s, such as Markov models. This work revisits high-order Markov models for spectrum prediction in dynamic wireless environments. We introduce a framework to address mismatches between sensing length and model order as well as state-space complexity arising with large order. Furthermore, we extend this Markov framework by enabling fine-tuning of the probability transition matrix through gradient-based supervised learning, offering a hybrid approach that bridges probabilistic modeling and modern machine learning. Simulations on real-world Wi-Fi traffic demonstrate the competitive performance of high-order Markov models compared to deep learning methods, particularly in scenarios with constrained datasets containing outliers.
Fusion of Time and Angle Measurements for Digital-Twin-Aided Probabilistic 3D Positioning
Oct 20, 2024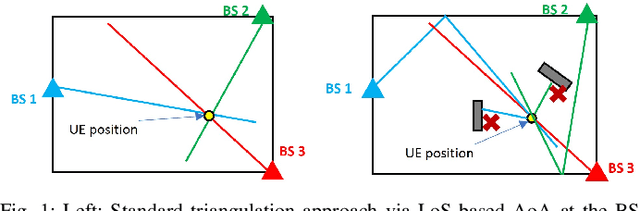
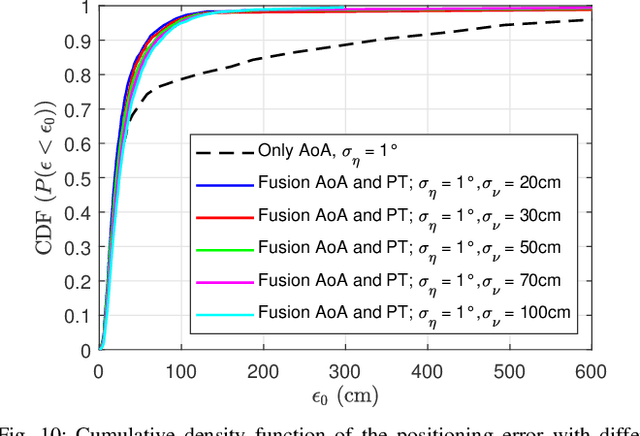
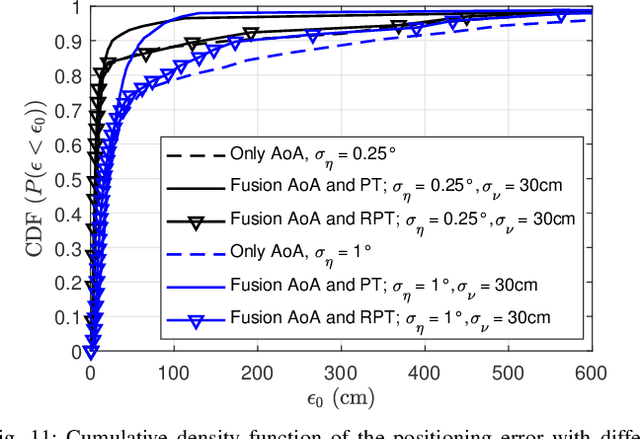
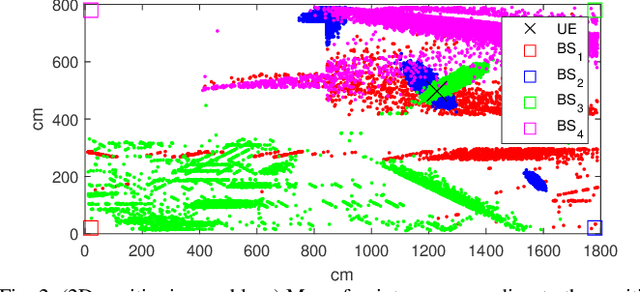
Previous studies explained how the 2D positioning problem in indoor non line-of-sight environments can be addressed using ray tracing with noisy angle of arrival (AoA) measurements. In this work, we generalize these results on two aspects. First, we outline how to adapt the proposed methods to address the 3D positioning problem. Second, we introduce efficient algorithms for data fusion, where propagation-time or relative propagation-time measurements (obtained via e.g., the time difference of arrival) are used in addition to AoA measurements. Simulation results are provided to illustrate the advantages of the approach.
A New Method for the Identification of a Wiener-Hammerstein Model in a Communication Context
Aug 30, 2024We propose a new algorithm to identify a Wiener-Hammerstein system. This model represents a communication channel where two linear filters are separated by a non-linear function modelling an amplifier. The algorithm enables to recover each parameter of the model, namely the two linear filters and the non-linear function. This is to be opposed with estimation algorithms which identify the equivalent Volterra system. The algorithm is composed of three main steps and uses three distinct pilot sequences. The estimation of the parameters is done in the time domain via several instances of the least-square algorithm. However, arguments based on the spectral representation of the signals and filters are used to design the pilot sequences. We also provide an analysis of the proposed algorithm. We estimate, via the theory and simulations, the minimum required size of the pilot sequences to achieve a target mean squared error between the output of the true channel and the output of the estimated model. We obtain that the new method requires reduced-size pilot sequences: The sum of the length of the pilot sequences is approximately the one needed to estimate the convolutional product of the two linear filters with a back-off. A comparison with the Volterra approach is also provided.
Active learning for efficient data selection in radio-signal based positioning via deep learning
Aug 21, 2024We consider the problem of user equipment (UE) positioning based on radio signals via deep learning. As in most supervised-learning tasks, a critical aspect is the availability of a relevant dataset to train a model. However, in a cellular network, the data-collection step may induce a high communication overhead. As a result, to reduce the required size of the dataset, it may be interesting to carefully choose the positions to be labelled and to be used in the training. We therefore propose an active learning approach for efficient data collection. We first show that significant gains (both in terms of positioning accuracy and size of the required dataset) can be obtained for the considered positioning problem using a genie. This validates the interest of active learning for positioning. We then propose a \textcolor{blue}{practical} method to approximate this genie.
Optimal sensing policy with interference-model uncertainty
Jun 12, 2024Assume that an interferer behaves according to a parametric model but one does not know the value of the model parameters. Sensing enables to improve the model knowledge and therefore perform a better link adaptation. However, we consider a half-duplex scenario where, at each time slot, the communication system should decide between sensing and communication. We thus propose to investigate the optimal policy to maximize the expected sum rate given a finite-time communication. % the following question therefore arises: At a given time slot, should one sense or communicate? We first show that this problem can be modelled in the Markov decision process (MDP) framework. We then demonstrate that the optimal open-loop and closed-loop policies can be found significantly faster than the standard backward-induction algorithm.
Probabilistic positioning via ray tracing with noisy angle of arrival measurements
Mar 01, 2024This paper investigates the problems of interference prediction and sensing for efficient spectrum access and link adaptation. The considered approach for interference prediction relies on a parametric model. However, we assume that the number of observations available to learn theses parameters is limited. This implies that they should be treated as random variables rather than fixed values. We show how this can impact the spectrum access and link adaptation strategies. We also introduce the notion of "interferer-coherence time" to establish the number of independent interferer state realizations experienced by a codeword. We explain how it can be computed taking into account the model uncertainty and how this impacts the link adaptation.
Model-based Deep Learning for Beam Prediction based on a Channel Chart
Dec 04, 2023Channel charting builds a map of the radio environment in an unsupervised way. The obtained chart locations can be seen as low-dimensional compressed versions of channel state information that can be used for a wide variety of applications, including beam prediction. In non-standalone or cell-free systems, chart locations computed at a given base station can be transmitted to several other base stations (possibly operating at different frequency bands) for them to predict which beams to use. This potentially yields a dramatic reduction of the overhead due to channel estimation or beam management, since only the base station performing charting requires channel state information, the others directly predicting the beam from the chart location. In this paper, advanced model-based neural network architectures are proposed for both channel charting and beam prediction. The proposed methods are assessed on realistic synthetic channels, yielding promising results.
Model-based learning for location-to-channel mapping
Aug 28, 2023Modern communication systems rely on accurate channel estimation to achieve efficient and reliable transmission of information. As the communication channel response is highly related to the user's location, one can use a neural network to map the user's spatial coordinates to the channel coefficients. However, these latter are rapidly varying as a function of the location, on the order of the wavelength. Classical neural architectures being biased towards learning low frequency functions (spectral bias), such mapping is therefore notably difficult to learn. In order to overcome this limitation, this paper presents a frugal, model-based network that separates the low frequency from the high frequency components of the target mapping function. This yields an hypernetwork architecture where the neural network only learns low frequency sparse coefficients in a dictionary of high frequency components. Simulation results show that the proposed neural network outperforms standard approaches on realistic synthetic data.