 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multiscale spatiotemporal approach for smallholder irrigation detection
Feb 09, 2022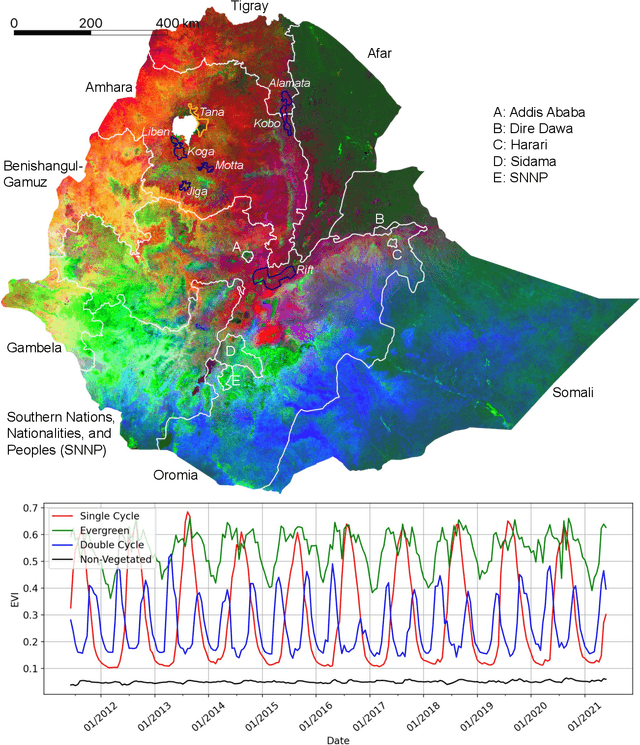
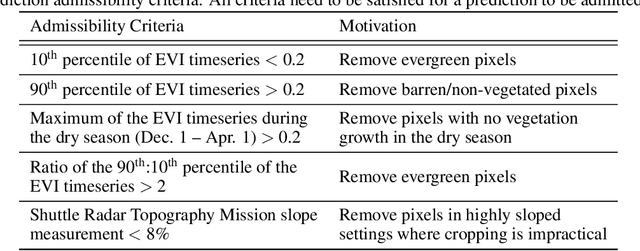
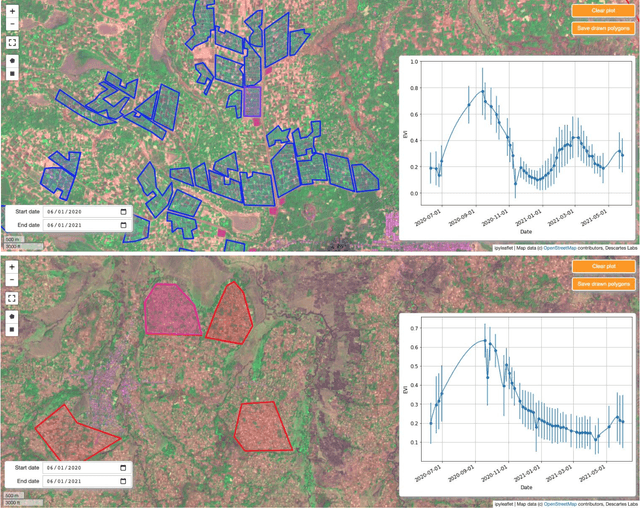
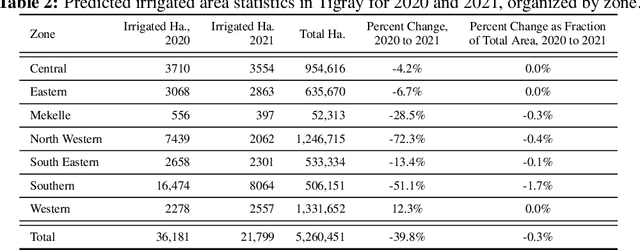
In presenting an irrigation detection methodology that leverages multiscale satellite imagery of vegetation abundance, this paper introduces a process to supplement limited ground-collected labels and ensure classifier applicability in an area of interest. Spatiotemporal analysis of MODIS 250m Enhanced Vegetation Index (EVI) timeseries characterizes native vegetation phenologies at regional scale to provide the basis for a continuous phenology map that guides supplementary label collection over irrigated and non-irrigated agriculture. Subsequently, validated dry season greening and senescence cycles observed in 10m Sentinel-2 imagery are used to train a suite of classifiers for automated detection of potential smallholder irrigation. Strategies to improve model robustness are demonstrated, including a method of data augmentation that randomly shifts training samples; and an assessment of classifier types that produce the best performance in withheld target regions. The methodology is applied to detect smallholder irrigation in two states in the Ethiopian highlands, Tigray and Amhara. Results show that a transformer-based neural network architecture allows for the most robust prediction performance in withheld regions, followed closely by a CatBoost random forest model. Over withheld ground-collection survey labels, the transformer-based model achieves 96.7% accuracy over non-irrigated samples and 95.9% accuracy over irrigated samples. Over a larger set of samples independently collected via the introduced method of label supplementation, non-irrigated and irrigated labels are predicted with 98.3% and 95.5% accuracy, respectively. The detection model is then deployed over Tigray and Amhara, revealing crop rotation patterns and year-over-year irrigated area change. Predictions suggest that irrigated area in these two states has decreased by approximately 40% from 2020 to 2021.
Predicting Levels of Household Electricity Consumption in Low-Access Settings
Dec 15, 2021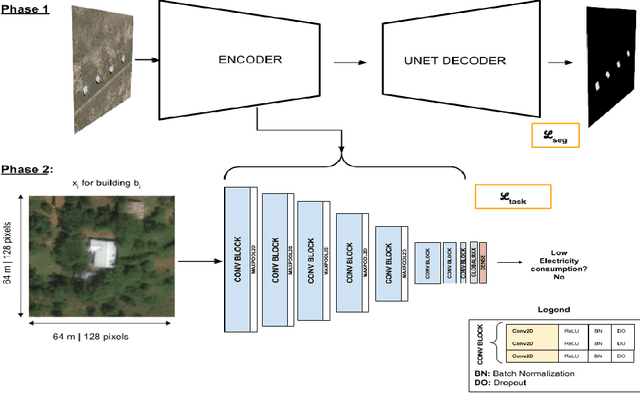


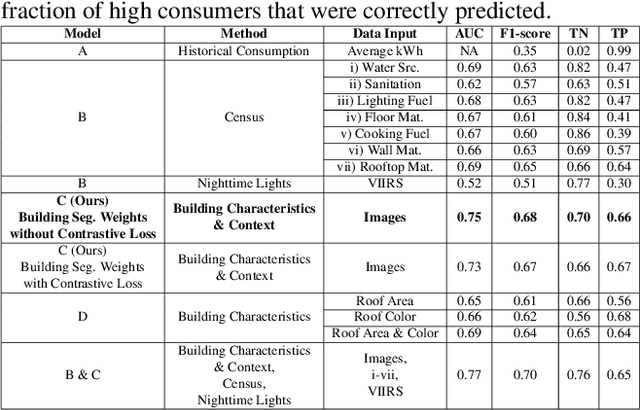
In low-income settings, the most critical piece of information for electric utilities is the anticipated consumption of a customer. Electricity consumption assessment is difficult to do in settings where a significant fraction of households do not yet have an electricity connection. In such settings the absolute levels of anticipated consumption can range from 5-100 kWh/month, leading to high variability amongst these customers. Precious resources are at stake if a significant fraction of low consumers are connected over those with higher consumption. This is the first study of it's kind in low-income settings that attempts to predict a building's consumption and not that of an aggregate administrative area. We train a Convolutional Neural Network (CNN) over pre-electrification daytime satellite imagery with a sample of utility bills from 20,000 geo-referenced electricity customers in Kenya (0.01% of Kenya's residential customers). This is made possible with a two-stage approach that uses a novel building segmentation approach to leverage much larger volumes of no-cost satellite imagery to make the most of scarce and expensive customer data. Our method shows that competitive accuracies can be achieved at the building level, addressing the challenge of consumption variability. This work shows that the building's characteristics and it's surrounding context are both important in predicting consumption levels. We also evaluate the addition of lower resolution geospatial datasets into the training process, including nighttime lights and census-derived data. The results are already helping inform site selection and distribution-level planning, through granular predictions at the level of individual structures in Kenya and there is no reason this cannot be extended to other countries.
Learning to segment from misaligned and partial labels
May 27, 2020

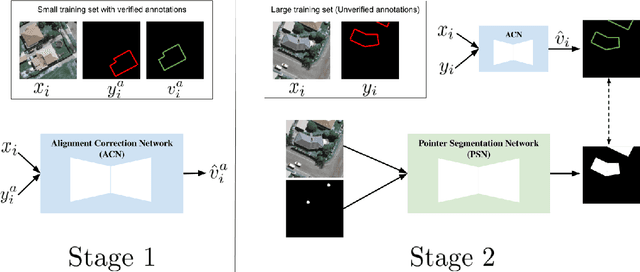
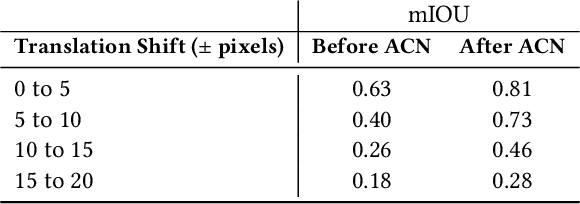
To extract information at scale, researchers increasingly apply semantic segmentation techniques to remotely-sensed imagery. While fully-supervised learning enables accurate pixel-wise segmentation, compiling the exhaustive datasets required is often prohibitively expensive. As a result, many non-urban settings lack the ground-truth needed for accurate segmentation. Existing open source infrastructure data for these regions can be inexact and non-exhaustive. Open source infrastructure annotations like OpenStreetMaps (OSM) are representative of this issue: while OSM labels provide global insights to road and building footprints, noisy and partial annotations limit the performance of segmentation algorithms that learn from them. In this paper, we present a novel and generalizable two-stage framework that enables improved pixel-wise image segmentation given misaligned and missing annotations. First, we introduce the Alignment Correction Network to rectify incorrectly registered open source labels. Next, we demonstrate a segmentation model -- the Pointer Segmentation Network -- that uses corrected labels to predict infrastructure footprints despite missing annotations. We test sequential performance on the AIRS dataset, achieving a mean intersection-over-union score of 0.79; more importantly, model performance remains stable as we decrease the fraction of annotations present. We demonstrate the transferability of our method to lower quality data, by applying the Alignment Correction Network to OSM labels to correct building footprints; we also demonstrate the accuracy of the Pointer Segmentation Network in predicting cropland boundaries in California from medium resolution data. Overall, our methodology is robust for multiple applications with varied amounts of training data present, thus offering a method to extract reliable information from noisy, partial data.