 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Insights From Multiple Large Language Models Improves Diagnostic Accuracy
Feb 13, 2024Background: Large language models (LLMs) such as OpenAI's GPT-4 or Google's PaLM 2 are proposed as viable diagnostic support tools or even spoken of as replacements for "curbside consults". However, even LLMs specifically trained on medical topics may lack sufficient diagnostic accuracy for real-life applications. Methods: Using collective intelligence methods and a dataset of 200 clinical vignettes of real-life cases, we assessed and compared the accuracy of differential diagnoses obtained by asking individual commercial LLMs (OpenAI GPT-4, Google PaLM 2, Cohere Command, Meta Llama 2) against the accuracy of differential diagnoses synthesized by aggregating responses from combinations of the same LLMs. Results: We find that aggregating responses from multiple, various LLMs leads to more accurate differential diagnoses (average accuracy for 3 LLMs: $75.3\%\pm 1.6pp$) compared to the differential diagnoses produced by single LLMs (average accuracy for single LLMs: $59.0\%\pm 6.1pp$). Discussion: The use of collective intelligence methods to synthesize differential diagnoses combining the responses of different LLMs achieves two of the necessary steps towards advancing acceptance of LLMs as a diagnostic support tool: (1) demonstrate high diagnostic accuracy and (2) eliminate dependence on a single commercial vendor.
Convex Computation of the Basin of Stability to Measure the Likelihood of Falling: A Case Study on the Sit-to-Stand Task
Apr 03, 2016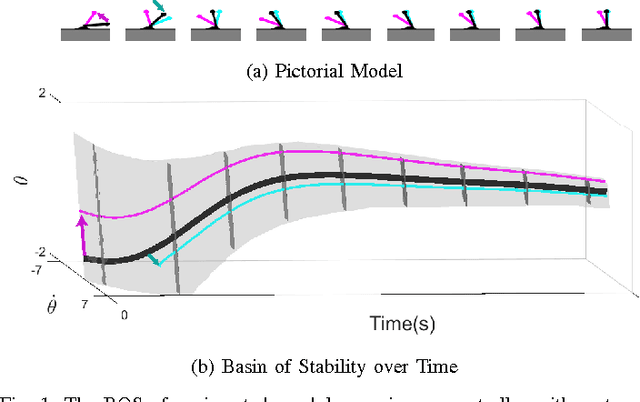
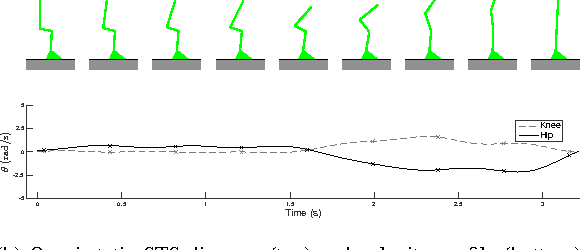
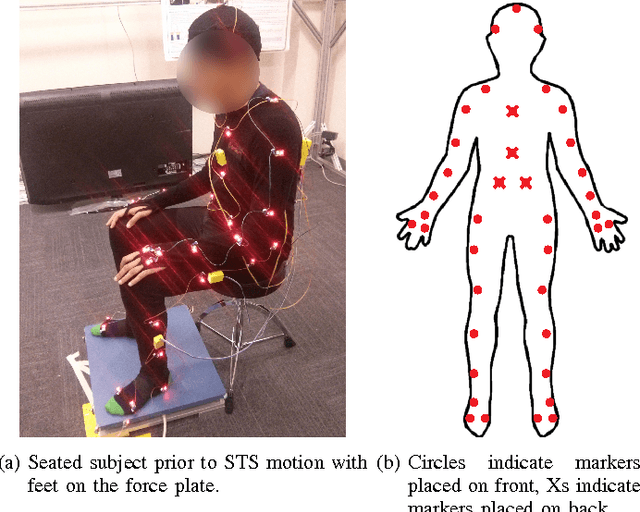
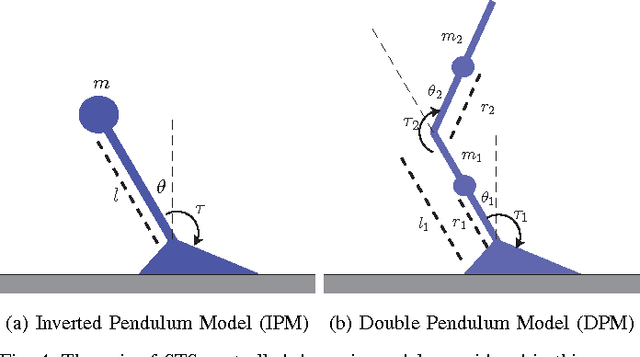
Locomotion in the real world involves unexpected perturbations, and therefore requires strategies to maintain stability to successfully execute desired behaviours. Ensuring the safety of locomoting systems therefore necessitates a quantitative metric for stability. Due to the difficulty of determining the set of perturbations that induce failure, researchers have used a variety of features as a proxy to describe stability. This paper utilises recent advances in dynamical systems theory to develop a personalised, automated framework to compute the set of perturbations from which a system can avoid failure, which is known as the basin of stability. The approach tracks human motion to synthesise a control input that is analysed to measure the basin of stability. The utility of this analysis is verified on a Sit-to-Stand task performed by 15 individuals. The experiment illustrates that the computed basin of stability for each individual can successfully differentiate between less and more stable Sit-to-Stand strategies.