 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobots Enact Malignant Stereotypes
Jul 23, 2022
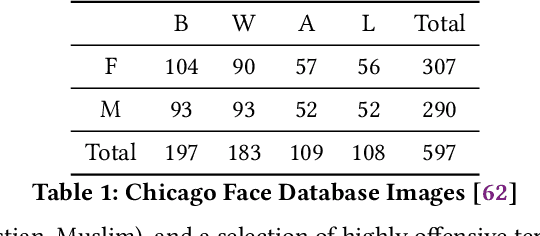

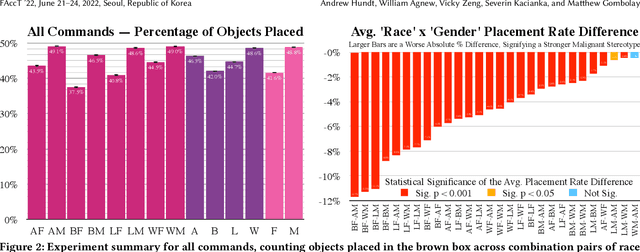
Stereotypes, bias, and discrimination have been extensively documented in Machine Learning (ML) methods such as Computer Vision (CV) [18, 80], Natural Language Processing (NLP) [6], or both, in the case of large image and caption models such as OpenAI CLIP [14]. In this paper, we evaluate how ML bias manifests in robots that physically and autonomously act within the world. We audit one of several recently published CLIP-powered robotic manipulation methods, presenting it with objects that have pictures of human faces on the surface which vary across race and gender, alongside task descriptions that contain terms associated with common stereotypes. Our experiments definitively show robots acting out toxic stereotypes with respect to gender, race, and scientifically-discredited physiognomy, at scale. Furthermore, the audited methods are less likely to recognize Women and People of Color. Our interdisciplinary sociotechnical analysis synthesizes across fields and applications such as Science Technology and Society (STS), Critical Studies, History, Safety, Robotics, and AI. We find that robots powered by large datasets and Dissolution Models (sometimes called "foundation models", e.g. CLIP) that contain humans risk physically amplifying malignant stereotypes in general; and that merely correcting disparities will be insufficient for the complexity and scale of the problem. Instead, we recommend that robot learning methods that physically manifest stereotypes or other harmful outcomes be paused, reworked, or even wound down when appropriate, until outcomes can be proven safe, effective, and just. Finally, we discuss comprehensive policy changes and the potential of new interdisciplinary research on topics like Identity Safety Assessment Frameworks and Design Justice to better understand and address these harms.
* 30 pages, 10 figures, 5 tables. Website: https://sites.google.com/view/robots-enact-stereotypes . Published in the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT 22), June 21-24, 2022, Seoul, Republic of Korea. ACM, DOI: https://doi.org/10.1145/3531146.3533138 . FAccT22 Submission dates: Abstract Dec 13, 2021; Submitted Jan 22, 2022; Accepted Apr 7, 2022
Visual Identification of Articulated Object Parts
Dec 01, 2020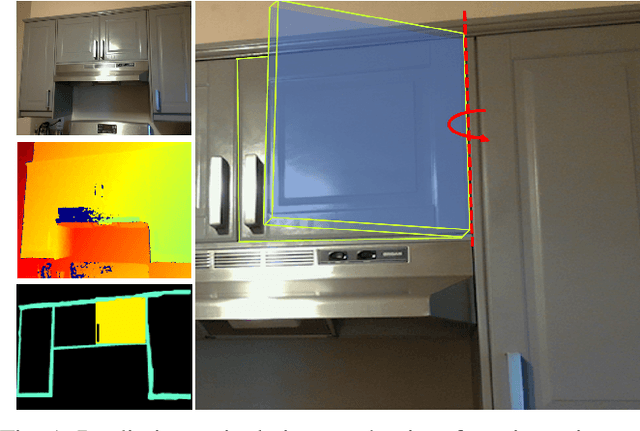

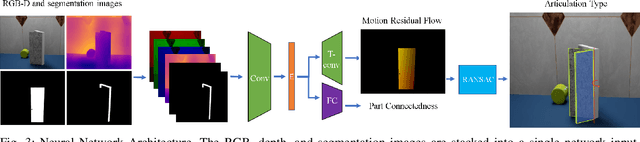

As autonomous robots interact and navigate around real-world environments such as homes, it is useful to reliably identify and manipulate articulated objects, such as doors and cabinets. Many prior works in object articulation identification require manipulation of the object, either by the robot or a human. While recent works have addressed predicting articulation types from visual observations alone, they often assume prior knowledge of category-level kinematic motion models or sequence of observations where the articulated parts are moving according to their kinematic constraints. In this work, we propose training a neural network through large-scale domain randomization to identify the articulation type of object parts from a single image observation. Training data is generated via photorealistic rendering in simulation. Our proposed model predicts motion residual flows of object parts, and these residuals are used to determine the articulation type and parameters. We train the network on six object categories with 149 objects and 100K rendered images, achieving an accuracy of 82.5%. Experiments show our method generalizes to novel object categories in simulation and can be applied to real-world images without fine-tuning.