 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultistream CNN for Robust Acoustic Modeling
May 21, 2020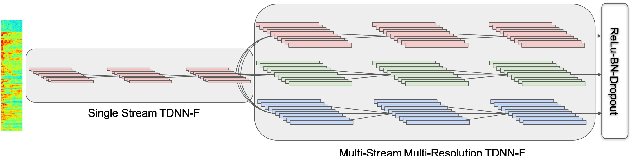
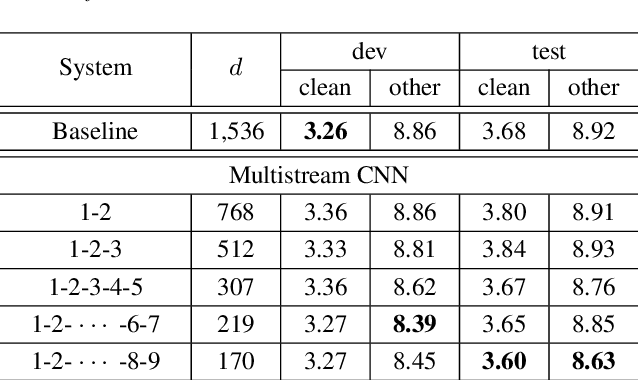
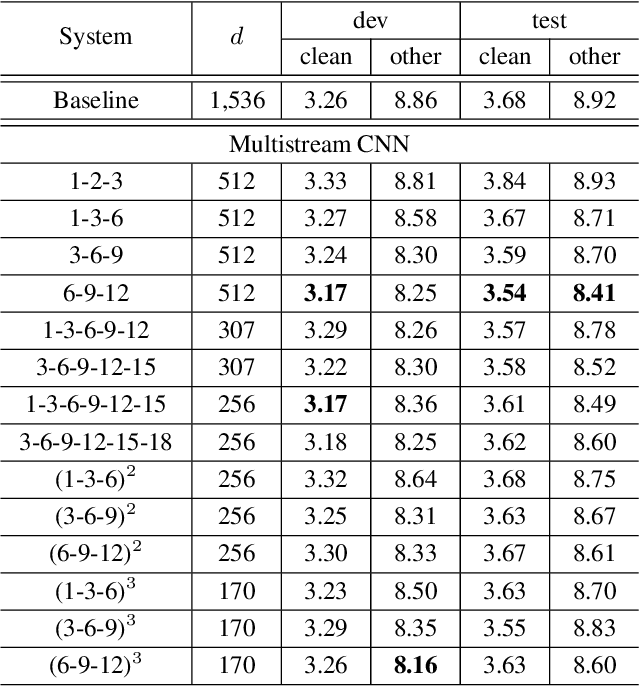
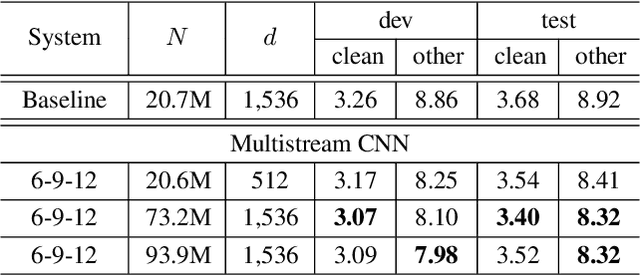
This paper presents multistream CNN, a novel neural network architecture for robust acoustic modeling in speech recognition tasks. The proposed architecture accommodates diverse temporal resolutions in multiple streams to achieve robustness in acoustic modeling. For the diversity of temporal resolution in embedding processing, we consider dilation on TDNN-F, a variant of 1D-CNN. Each stream stacks narrower TDNN-F layers whose kernel has a unique, stream-specific dilation rate when processing input speech frames in parallel. Hence it can better represent acoustic events without the increase of model complexity. We validate the effectiveness of the proposed multistream CNN architecture by showing consistent improvement across various data sets. Trained with data augmentation methods, multistream CNN improves the WER of the test-other set in the LibriSpeech corpus by 12% (relative). On custom data from ASAPP's production system for a contact center, it records a relative WER improvement of 11% for the customer channel audios (10% on average for the agent and customer channel recordings) to prove the superiority of the proposed model architecture in the wild. In terms of real-time factor (RTF), multistream CNN outperforms the normal TDNN-F by 15%, which also suggests its practicality on production systems or applications.