 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in an embedding? Would a rose by any embedding smell as sweet?
Jun 11, 2024



Large Language Models (LLMs) are often criticized for lacking true "understanding" and an ability to "reason" with their knowledge, being seen merely as advanced autocomplete systems. We believe that this perspective might be missing an important insight. We suggest that LLMs do develop a kind of empirical "understanding" that is "geometry"-like, which seems quite sufficient for a range of applications in NLP, computer vision, coding assistance, etc. However, this "geometric" understanding, built from incomplete and noisy data, makes them unreliable, difficult to generalize, and lacking in inference capabilities and explanations, similar to the challenges faced by heuristics-based expert systems decades ago. To overcome these limitations, we suggest that LLMs should be integrated with an "algebraic" representation of knowledge that includes symbolic AI elements used in expert systems. This integration aims to create large knowledge models (LKMs) that not only possess "deep" knowledge grounded in first principles, but also have the ability to reason and explain, mimicking human expert capabilities. To harness the full potential of generative AI safely and effectively, a paradigm shift from LLMs to the more comprehensive LKMs is needed.
Quo Vadis ChatGPT? From Large Language Models to Large Knowledge Models
May 29, 2024



The startling success of ChatGPT and other large language models (LLMs) using transformer-based generative neural network architecture in applications such as natural language processing and image synthesis has many researchers excited about potential opportunities in process systems engineering (PSE). The almost human-like performance of LLMs in these areas is indeed very impressive, surprising, and a major breakthrough. Their capabilities are very useful in certain tasks, such as writing first drafts of documents, code writing assistance, text summarization, etc. However, their success is limited in highly scientific domains as they cannot yet reason, plan, or explain due to their lack of in-depth domain knowledge. This is a problem in domains such as chemical engineering as they are governed by fundamental laws of physics and chemistry (and biology), constitutive relations, and highly technical knowledge about materials, processes, and systems. Although purely data-driven machine learning has its immediate uses, the long-term success of AI in scientific and engineering domains would depend on developing hybrid AI systems that use first principles and technical knowledge effectively. We call these hybrid AI systems Large Knowledge Models (LKMs), as they will not be limited to only NLP-based techniques or NLP-like applications. In this paper, we discuss the challenges and opportunities in developing such systems in chemical engineering.
Jaynes Machine: The universal microstructure of deep neural networks
Oct 10, 2023We present a novel theory of the microstructure of deep neural networks. Using a theoretical framework called statistical teleodynamics, which is a conceptual synthesis of statistical thermodynamics and potential game theory, we predict that all highly connected layers of deep neural networks have a universal microstructure of connection strengths that is distributed lognormally ($LN({\mu}, {\sigma})$). Furthermore, under ideal conditions, the theory predicts that ${\mu}$ and ${\sigma}$ are the same for all layers in all networks. This is shown to be the result of an arbitrage equilibrium where all connections compete and contribute the same effective utility towards the minimization of the overall loss function. These surprising predictions are shown to be supported by empirical data from six large-scale deep neural networks in real life. We also discuss how these results can be exploited to reduce the amount of data, time, and computational resources needed to train large deep neural networks.
G-MATT: Single-step Retrosynthesis Prediction using Molecular Grammar Tree Transformer
May 04, 2023In recent years, several reaction templates-based and template-free approaches have been reported for single-step retrosynthesis prediction. Even though many of these approaches perform well from traditional data-driven metrics standpoint, there is a disconnect between model architectures used and underlying chemistry principles governing retrosynthesis. Here, we propose a novel chemistry-aware retrosynthesis prediction framework that combines powerful data-driven models with chemistry knowledge. We report a tree-to-sequence transformer architecture based on hierarchical SMILES grammar trees as input containing underlying chemistry information that is otherwise ignored by models based on purely SMILES-based representations. The proposed framework, grammar-based molecular attention tree transformer (G-MATT), achieves significant performance improvements compared to baseline retrosynthesis models. G-MATT achieves a top-1 accuracy of 51% (top-10 accuracy of 79.1%), invalid rate of 1.5%, and bioactive similarity rate of 74.8%. Further analyses based on attention maps demonstrate G-MATT's ability to preserve chemistry knowledge without having to use extremely complex model architectures.
AI-driven Hypernetwork of Organic Chemistry: Network Statistics and Applications in Reaction Classification
Aug 02, 2022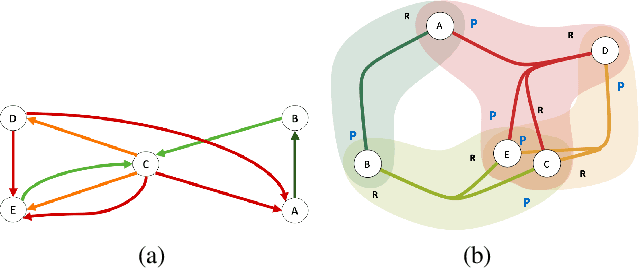
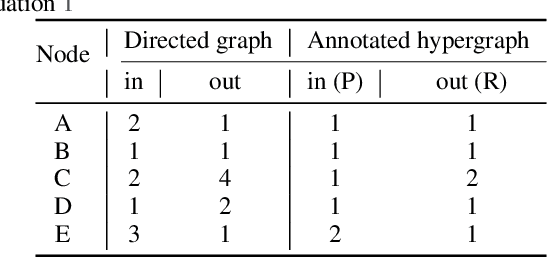
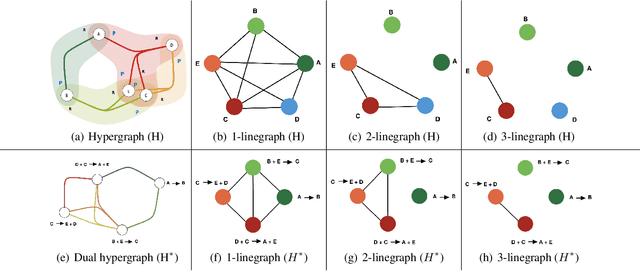
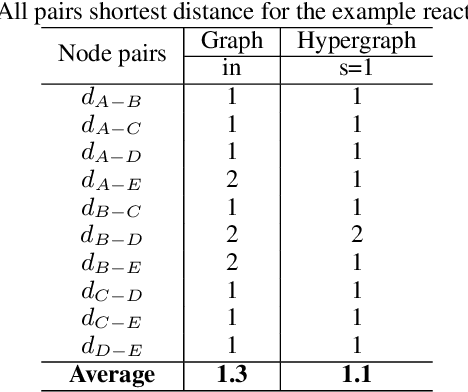
Rapid discovery of new reactions and molecules in recent years has been facilitated by the advancements in high throughput screening, accessibility to a much more complex chemical design space, and the development of accurate molecular modeling frameworks. A holistic study of the growing chemistry literature is, therefore, required that focuses on understanding the recent trends and extrapolating them into possible future trajectories. To this end, several network theory-based studies have been reported that use a directed graph representation of chemical reactions. Here, we perform a study based on representing chemical reactions as hypergraphs where the hyperedges represent chemical reactions and nodes represent the participating molecules. We use a standard reactions dataset to construct a hypernetwork and report its statistics such as degree distributions, average path length, assortativity or degree correlations, PageRank centrality, and graph-based clusters (or communities). We also compute each statistic for an equivalent directed graph representation of reactions to draw parallels and highlight differences between the two. To demonstrate the AI applicability of hypergraph reaction representation, we generate dense hypergraph embeddings and use them in the reaction classification problem. We conclude that the hypernetwork representation is flexible, preserves reaction context, and uncovers hidden insights that are otherwise not apparent in a traditional directed graph representation of chemical reactions.
Robust and Efficient Swarm Communication Topologies for Hostile Environments
Aug 21, 2020
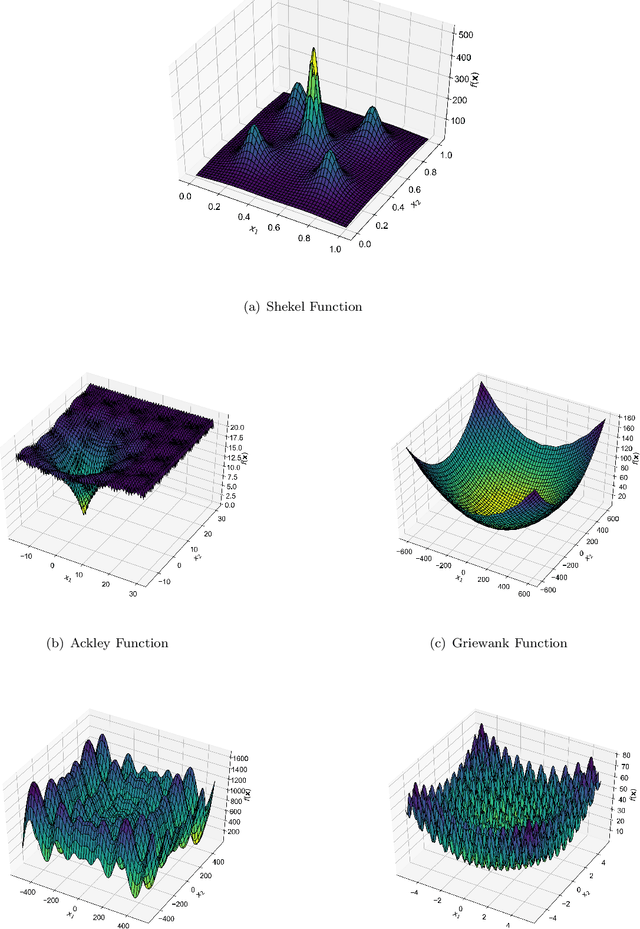

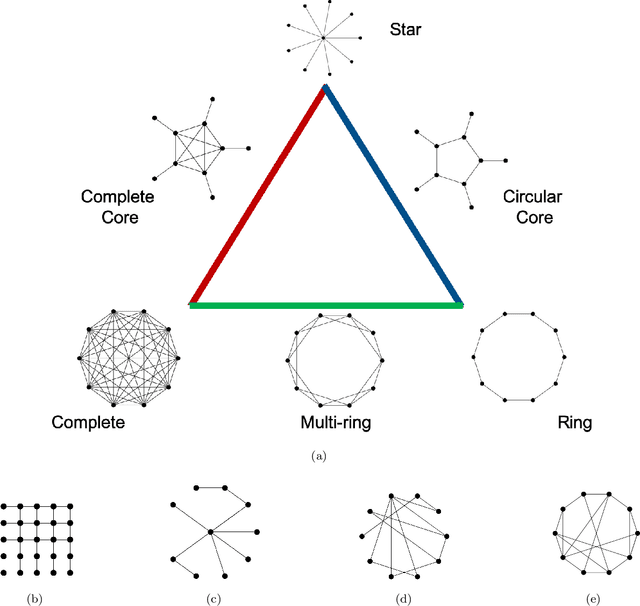
Swarm Intelligence-based optimization techniques combine systematic exploration of the search space with information available from neighbors and rely strongly on communication among agents. These algorithms are typically employed to solve problems where the function landscape is not adequately known and there are multiple local optima that could result in premature convergence for other algorithms. Applications of such algorithms can be found in communication systems involving design of networks for efficient information dissemination to a target group, targeted drug-delivery where drug molecules search for the affected site before diffusing, and high-value target localization with a network of drones. In several of such applications, the agents face a hostile environment that can result in loss of agents during the search. Such a loss changes the communication topology of the agents and hence the information available to agents, ultimately influencing the performance of the algorithm. In this paper, we present a study of the impact of loss of agents on the performance of such algorithms as a function of the initial network configuration. We use particle swarm optimization to optimize an objective function with multiple sub-optimal regions in a hostile environment and study its performance for a range of network topologies with loss of agents. The results reveal interesting trade-offs between efficiency, robustness, and performance for different topologies that are subsequently leveraged to discover general properties of networks that maximize performance. Moreover, networks with small-world properties are seen to maximize performance under hostile conditions.