 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosis and Severity Assessment of Ulcerative Colitis using Self Supervised Learning
Dec 09, 2024Ulcerative Colitis (UC) is an incurable inflammatory bowel disease that leads to ulcers along the large intestine and rectum. The increase in the prevalence of UC coupled with gastrointestinal physician shortages stresses the healthcare system and limits the care UC patients receive. A colonoscopy is performed to diagnose UC and assess its severity based on the Mayo Endoscopic Score (MES). The MES ranges between zero and three, wherein zero indicates no inflammation and three indicates that the inflammation is markedly high. Artificial Intelligence (AI)-based neural network models, such as convolutional neural networks (CNNs) are capable of analyzing colonoscopies to diagnose and determine the severity of UC by modeling colonoscopy analysis as a multi-class classification problem. Prior research for AI-based UC diagnosis relies on supervised learning approaches that require large annotated datasets to train the CNNs. However, creating such datasets necessitates that domain experts invest a significant amount of time, rendering the process expensive and challenging. To address the challenge, this research employs self-supervised learning (SSL) frameworks that can efficiently train on unannotated datasets to analyze colonoscopies and, aid in diagnosing UC and its severity. A comparative analysis with supervised learning models shows that SSL frameworks, such as SwAV and SparK outperform supervised learning models on the LIMUC dataset, the largest publicly available annotated dataset of colonoscopy images for UC.
Predicting Mortality and Functional Status Scores of Traumatic Brain Injury Patients using Supervised Machine Learning
Oct 27, 2024Traumatic brain injury (TBI) presents a significant public health challenge, often resulting in mortality or lasting disability. Predicting outcomes such as mortality and Functional Status Scale (FSS) scores can enhance treatment strategies and inform clinical decision-making. This study applies supervised machine learning (ML) methods to predict mortality and FSS scores using a real-world dataset of 300 pediatric TBI patients from the University of Colorado School of Medicine. The dataset captures clinical features, including demographics, injury mechanisms, and hospitalization outcomes. Eighteen ML models were evaluated for mortality prediction, and thirteen models were assessed for FSS score prediction. Performance was measured using accuracy, ROC AUC, F1-score, and mean squared error. Logistic regression and Extra Trees models achieved high precision in mortality prediction, while linear regression demonstrated the best FSS score prediction. Feature selection reduced 103 clinical variables to the most relevant, enhancing model efficiency and interpretability. This research highlights the role of ML models in identifying high-risk patients and supporting personalized interventions, demonstrating the potential of data-driven analytics to improve TBI care and integrate into clinical workflows.
Leaf Angle Estimation using Mask R-CNN and LETR Vision Transformer
Aug 01, 2024



Modern day studies show a high degree of correlation between high yielding crop varieties and plants with upright leaf angles. It is observed that plants with upright leaf angles intercept more light than those without upright leaf angles, leading to a higher rate of photosynthesis. Plant scientists and breeders benefit from tools that can directly measure plant parameters in the field i.e. on-site phenotyping. The estimation of leaf angles by manual means in a field setting is tedious and cumbersome. We mitigate the tedium using a combination of the Mask R-CNN instance segmentation neural network, and Line Segment Transformer (LETR), a vision transformer. The proposed Computer Vision (CV) pipeline is applied on two image datasets, Summer 2015-Ames ULA and Summer 2015- Ames MLA, with a combined total of 1,827 plant images collected in the field using FieldBook, an Android application aimed at on-site phenotyping. The leaf angles estimated by the proposed pipeline on the image datasets are compared to two independent manual measurements using ImageJ, a Java-based image processing program developed at the National Institutes of Health and the Laboratory for Optical and Computational Instrumentation. The results, when compared for similarity using the Cosine Similarity measure, exhibit 0.98 similarity scores on both independent measurements of Summer 2015-Ames ULA and Summer 2015-Ames MLA image datasets, demonstrating the feasibility of the proposed pipeline for on-site measurement of leaf angles.
Seed Kernel Counting using Domain Randomization and Object Tracking Neural Networks
Aug 10, 2023High-throughput phenotyping (HTP) of seeds, also known as seed phenotyping, is the comprehensive assessment of complex seed traits such as growth, development, tolerance, resistance, ecology, yield, and the measurement of parameters that form more complex traits. One of the key aspects of seed phenotyping is cereal yield estimation that the seed production industry relies upon to conduct their business. While mechanized seed kernel counters are available in the market currently, they are often priced high and sometimes outside the range of small scale seed production firms' affordability. The development of object tracking neural network models such as You Only Look Once (YOLO) enables computer scientists to design algorithms that can estimate cereal yield inexpensively. The key bottleneck with neural network models is that they require a plethora of labelled training data before they can be put to task. We demonstrate that the use of synthetic imagery serves as a feasible substitute to train neural networks for object tracking that includes the tasks of object classification and detection. Furthermore, we propose a seed kernel counter that uses a low-cost mechanical hopper, trained YOLOv8 neural network model, and object tracking algorithms on StrongSORT and ByteTrack to estimate cereal yield from videos. The experiment yields a seed kernel count with an accuracy of 95.2\% and 93.2\% for Soy and Wheat respectively using the StrongSORT algorithm, and an accuray of 96.8\% and 92.4\% for Soy and Wheat respectively using the ByteTrack algorithm.
Fractional Vegetation Cover Estimation using Hough Lines and Linear Iterative Clustering
Apr 30, 2022
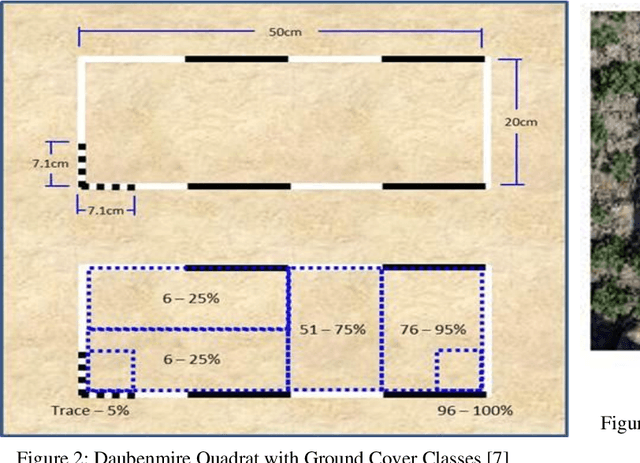
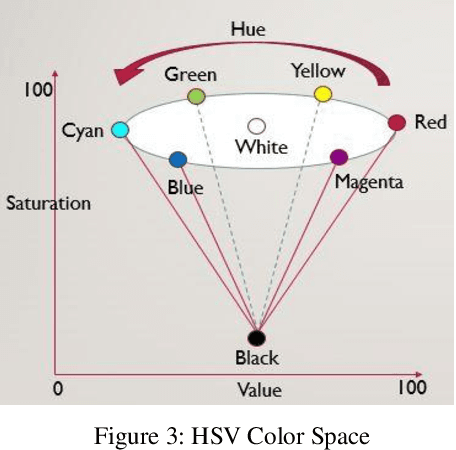

A common requirement of plant breeding programs across the country is companion planting -- growing different species of plants in close proximity so they can mutually benefit each other. However, the determination of companion plants requires meticulous monitoring of plant growth. The technique of ocular monitoring is often laborious and error prone. The availability of image processing techniques can be used to address the challenge of plant growth monitoring and provide robust solutions that assist plant scientists to identify companion plants. This paper presents a new image processing algorithm to determine the amount of vegetation cover present in a given area, called fractional vegetation cover. The proposed technique draws inspiration from the trusted Daubenmire method for vegetation cover estimation and expands upon it. Briefly, the idea is to estimate vegetation cover from images containing multiple rows of plant species growing in close proximity separated by a multi-segment PVC frame of known size. The proposed algorithm applies a Hough Transform and Simple Linear Iterative Clustering (SLIC) to estimate the amount of vegetation cover within each segment of the PVC frame. The analysis when repeated over images captured at regular intervals of time provides crucial insights into plant growth. As a means of comparison, the proposed algorithm is compared with SamplePoint and Canopeo, two trusted applications used for vegetation cover estimation. The comparison shows a 99% similarity with both SamplePoint and Canopeo demonstrating the accuracy and feasibility of the algorithm for fractional vegetation cover estimation.
Seed Classification using Synthetic Image Datasets Generated from Low-Altitude UAV Imagery
Oct 06, 2021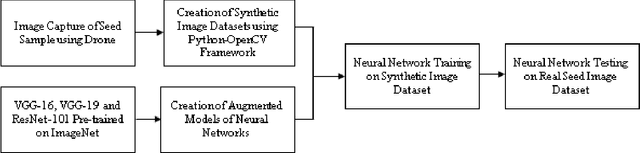
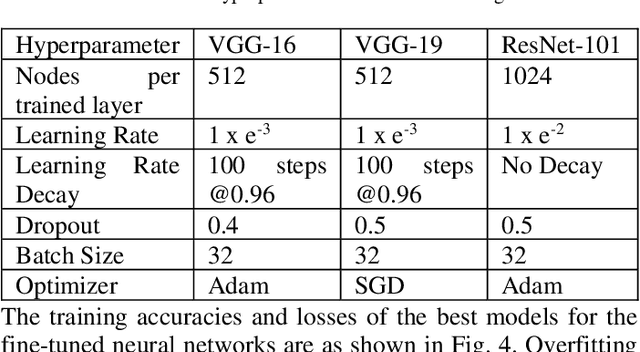

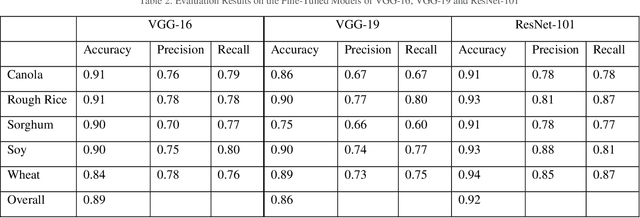
Plant breeding programs extensively monitor the evolution of seed kernels for seed certification, wherein lies the need to appropriately label the seed kernels by type and quality. However, the breeding environments are large where the monitoring of seed kernels can be challenging due to the minuscule size of seed kernels. The use of unmanned aerial vehicles aids in seed monitoring and labeling since they can capture images at low altitudes whilst being able to access even the remotest areas in the environment. A key bottleneck in the labeling of seeds using UAV imagery is drone altitude i.e. the classification accuracy decreases as the altitude increases due to lower image detail. Convolutional neural networks are a great tool for multi-class image classification when there is a training dataset that closely represents the different scenarios that the network might encounter during evaluation. The article addresses the challenge of training data creation using Domain Randomization wherein synthetic image datasets are generated from a meager sample of seeds captured by the bottom camera of an autonomously driven Parrot AR Drone 2.0. Besides, the article proposes a seed classification framework as a proof-of-concept using the convolutional neural networks of Microsoft's ResNet-100, Oxford's VGG-16, and VGG-19. To enhance the classification accuracy of the framework, an ensemble model is developed resulting in an overall accuracy of 94.6%.
PiBase: An IoT-based Security System using Raspberry Pi and Google Firebase
Jul 29, 2021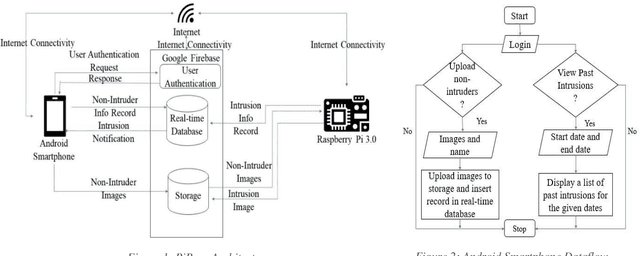
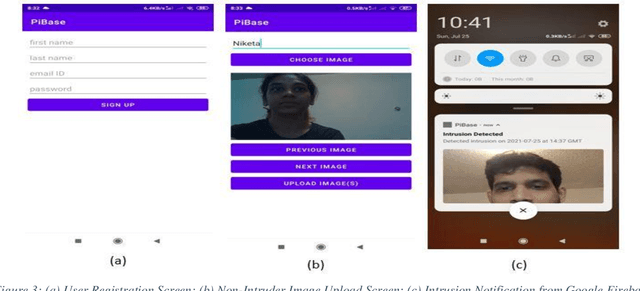
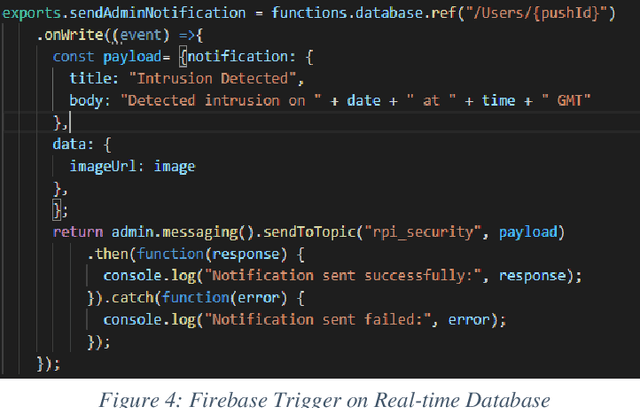
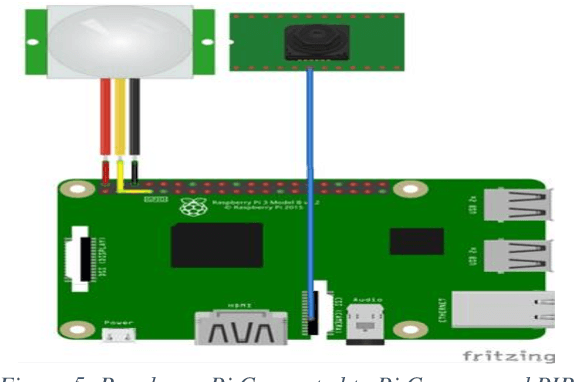
Smart environments are environments where digital devices are connected to each other over the Internet and operate in sync. Security is of paramount importance in such environments. This paper addresses aspects of authorized access and intruder detection for smart environments. Proposed is PiBase, an Internet of Things (IoT)-based app that aids in detecting intruders and providing security. The hardware for the application consists of a Raspberry Pi, a PIR motion sensor to detect motion from infrared radiation in the environment, an Android mobile phone and a camera. The software for the application is written in Java, Python and NodeJS. The PIR sensor and Pi camera module connected to the Raspberry Pi aid in detecting human intrusion. Machine learning algorithms, namely Haar-feature based cascade classifiers and Linear Binary Pattern Histograms (LBPH), are used for face detection and face recognition, respectively. The app lets the user create a list of non-intruders and anyone that is not on the list is identified as an intruder. The app alerts the user only in the event of an intrusion by using the Google Firebase Cloud Messaging service to trigger a notification to the app. The user may choose to add the detected intruder to the list of non-intruders through the app to avoid further detections as intruder. Face detection by the Haar Cascade algorithm yields a recall of 94.6%. Thus, the system is both highly effective and relatively low cost.
Classification of Seeds using Domain Randomization on Self-Supervised Learning Frameworks
Mar 29, 2021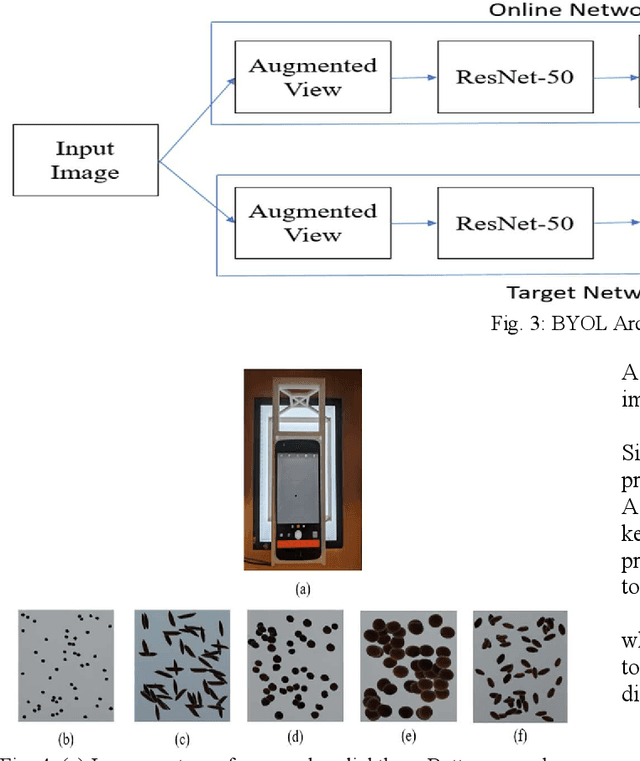
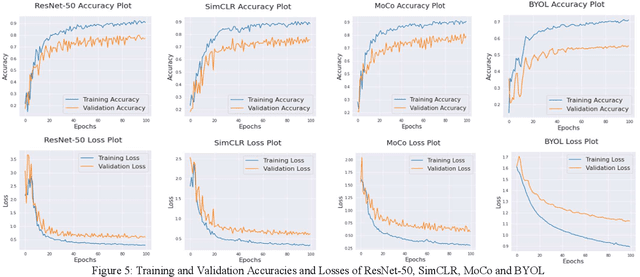
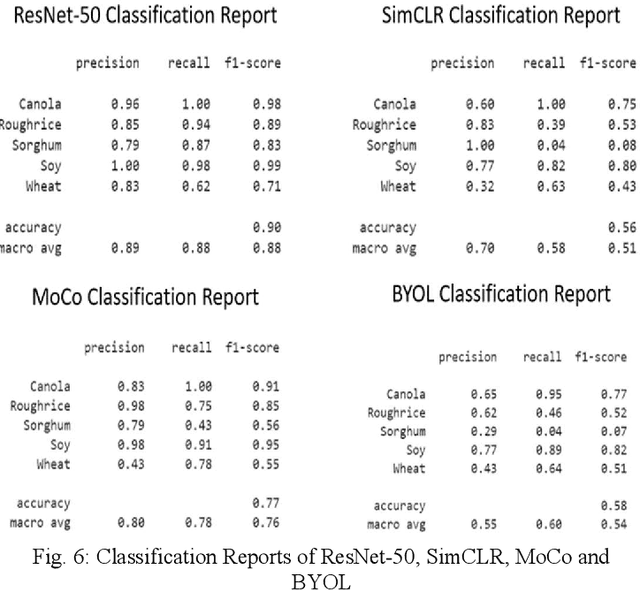
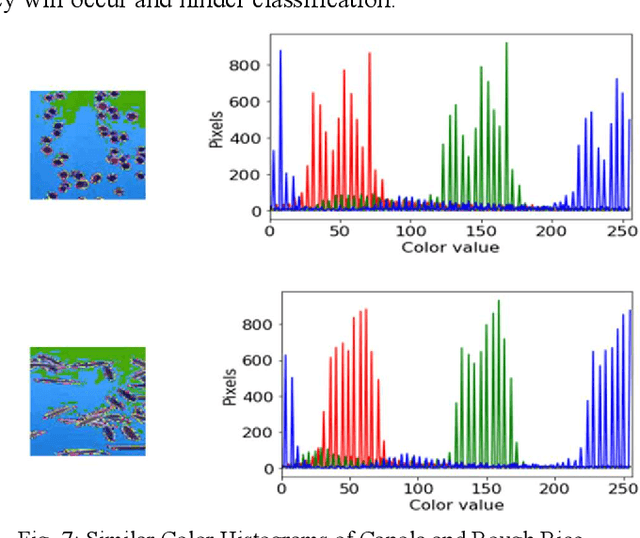
The first step toward Seed Phenotyping i.e. the comprehensive assessment of complex seed traits such as growth, development, tolerance, resistance, ecology, yield, and the measurement of pa-rameters that form more complex traits is the identification of seed type. Generally, a plant re-searcher inspects the visual attributes of a seed such as size, shape, area, color and texture to identify the seed type, a process that is tedious and labor-intensive. Advances in the areas of computer vision and deep learning have led to the development of convolutional neural networks (CNN) that aid in classification using images. While they classify efficiently, a key bottleneck is the need for an extensive amount of labelled data to train the CNN before it can be put to the task of classification. The work leverages the concepts of Contrastive Learning and Domain Randomi-zation in order to achieve the same. Briefly, domain randomization is the technique of applying models trained on images containing simulated objects to real-world objects. The use of synthetic images generated from a representational sample crop of real-world images alleviates the need for a large volume of test subjects. As part of the work, synthetic image datasets of five different types of seed images namely, canola, rough rice, sorghum, soy and wheat are applied to three different self-supervised learning frameworks namely, SimCLR, Momentum Contrast (MoCo) and Build Your Own Latent (BYOL) where ResNet-50 is used as the backbone in each of the networks. When the self-supervised models are fine-tuned with only 5% of the labels from the synthetic dataset, results show that MoCo, the model that yields the best performance of the self-supervised learning frameworks in question, achieves an accuracy of 77% on the test dataset which is only ~13% less than the accuracy of 90% achieved by ResNet-50 trained on 100% of the labels.
Seed Phenotyping on Neural Networks using Domain Randomization and Transfer Learning
Dec 24, 2020
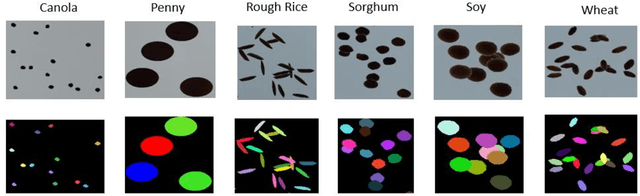
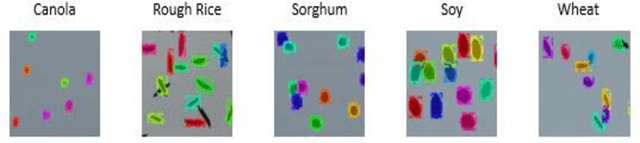
Seed phenotyping is the idea of analyzing the morphometric characteristics of a seed to predict the behavior of the seed in terms of development, tolerance and yield in various environmental conditions. The focus of the work is the application and feasibility analysis of the state-of-the-art object detection and localization neural networks, Mask R-CNN and YOLO (You Only Look Once), for seed phenotyping using Tensorflow. One of the major bottlenecks of such an endeavor is the need for large amounts of training data. While the capture of a multitude of seed images is taunting, the images are also required to be annotated to indicate the boundaries of the seeds on the image and converted to data formats that the neural networks are able to consume. Although tools to manually perform the task of annotation are available for free, the amount of time required is enormous. In order to tackle such a scenario, the idea of domain randomization i.e. the technique of applying models trained on images containing simulated objects to real-world objects, is considered. In addition, transfer learning i.e. the idea of applying the knowledge obtained while solving a problem to a different problem, is used. The networks are trained on pre-trained weights from the popular ImageNet and COCO data sets. As part of the work, experiments with different parameters are conducted on five different seed types namely, canola, rough rice, sorghum, soy, and wheat.
Bombus Species Image Classification
Jun 09, 2020
Entomologists, ecologists and others struggle to rapidly and accurately identify the species of bumble bees they encounter in their field work and research. The current process requires the bees to be mounted, then physically shipped to a taxonomic expert for proper categorization. We investigated whether an image classification system derived from transfer learning can do this task. We used Google Inception, Oxford VGG16 and VGG19 and Microsoft ResNet 50. We found Inception and VGG classifiers were able to make some progress at identifying bumble bee species from the available data, whereas ResNet was not. Individual classifiers achieved accuracies of up to 23% for single species identification and 44% top-3 labels, where a composite model performed better, 27% and 50%. We feel the performance was most hampered by our limited data set of 5,000-plus labeled images of 29 species, with individual species represented by 59 -315 images.