 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Seeds using Domain Randomization on Self-Supervised Learning Frameworks
Paper and Code
Mar 29, 2021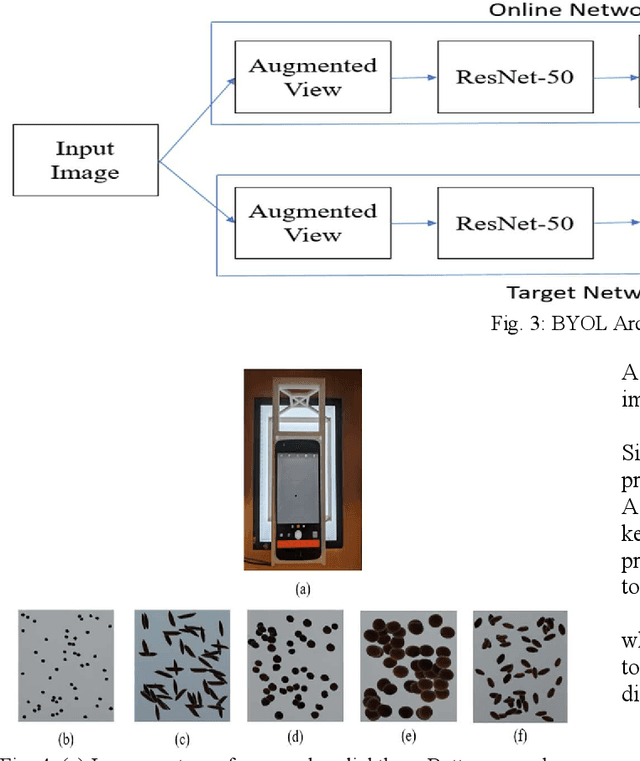
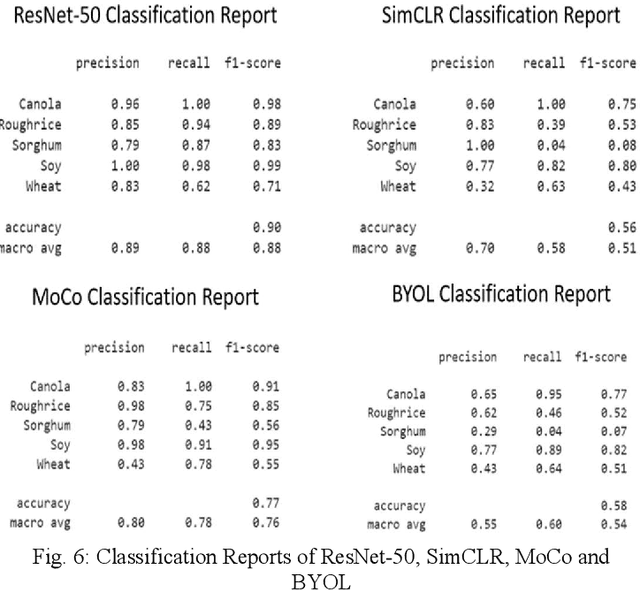
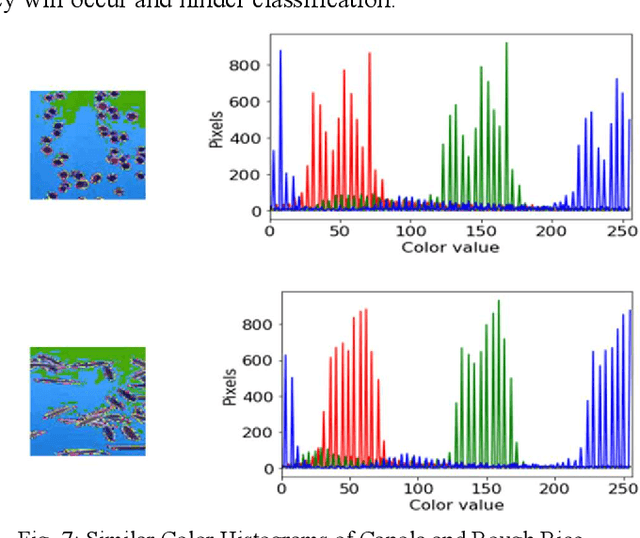
The first step toward Seed Phenotyping i.e. the comprehensive assessment of complex seed traits such as growth, development, tolerance, resistance, ecology, yield, and the measurement of pa-rameters that form more complex traits is the identification of seed type. Generally, a plant re-searcher inspects the visual attributes of a seed such as size, shape, area, color and texture to identify the seed type, a process that is tedious and labor-intensive. Advances in the areas of computer vision and deep learning have led to the development of convolutional neural networks (CNN) that aid in classification using images. While they classify efficiently, a key bottleneck is the need for an extensive amount of labelled data to train the CNN before it can be put to the task of classification. The work leverages the concepts of Contrastive Learning and Domain Randomi-zation in order to achieve the same. Briefly, domain randomization is the technique of applying models trained on images containing simulated objects to real-world objects. The use of synthetic images generated from a representational sample crop of real-world images alleviates the need for a large volume of test subjects. As part of the work, synthetic image datasets of five different types of seed images namely, canola, rough rice, sorghum, soy and wheat are applied to three different self-supervised learning frameworks namely, SimCLR, Momentum Contrast (MoCo) and Build Your Own Latent (BYOL) where ResNet-50 is used as the backbone in each of the networks. When the self-supervised models are fine-tuned with only 5% of the labels from the synthetic dataset, results show that MoCo, the model that yields the best performance of the self-supervised learning frameworks in question, achieves an accuracy of 77% on the test dataset which is only ~13% less than the accuracy of 90% achieved by ResNet-50 trained on 100% of the labels.