 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neural Network Approaches for Long Document Classification
Jan 18, 2022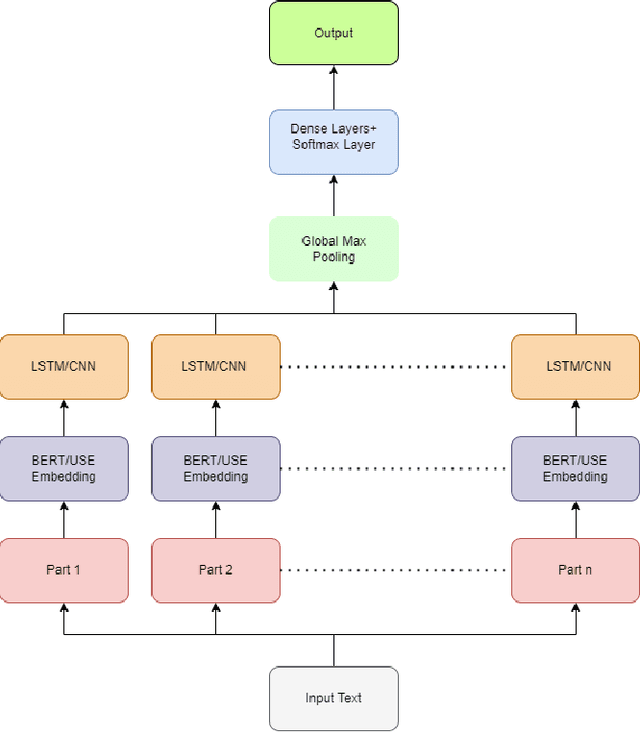
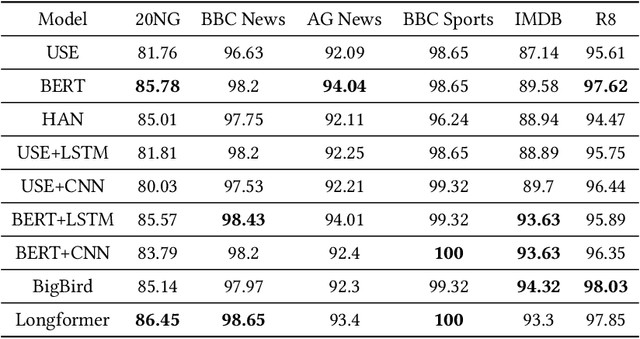
Text classification algorithms investigate the intricate relationships between words or phrases and attempt to deduce the document's interpretation. In the last few years, these algorithms have progressed tremendously. Transformer architecture and sentence encoders have proven to give superior results on natural language processing tasks. But a major limitation of these architectures is their applicability for text no longer than a few hundred words. In this paper, we explore hierarchical transfer learning approaches for long document classification. We employ pre-trained Universal Sentence Encoder (USE) and Bidirectional Encoder Representations from Transformers (BERT) in a hierarchical setup to capture better representations efficiently. Our proposed models are conceptually simple where we divide the input data into chunks and then pass this through base models of BERT and USE. Then output representation for each chunk is then propagated through a shallow neural network comprising of LSTMs or CNNs for classifying the text data. These extensions are evaluated on 6 benchmark datasets. We show that USE + CNN/LSTM performs better than its stand-alone baseline. Whereas the BERT + CNN/LSTM performs on par with its stand-alone counterpart. However, the hierarchical BERT models are still desirable as it avoids the quadratic complexity of the attention mechanism in BERT. Along with the hierarchical approaches, this work also provides a comparison of different deep learning algorithms like USE, BERT, HAN, Longformer, and BigBird for long document classification. The Longformer approach consistently performs well on most of the datasets.
AtteSTNet -- An attention and subword tokenization based approach for code-switched Hindi-English hate speech detection
Dec 10, 2021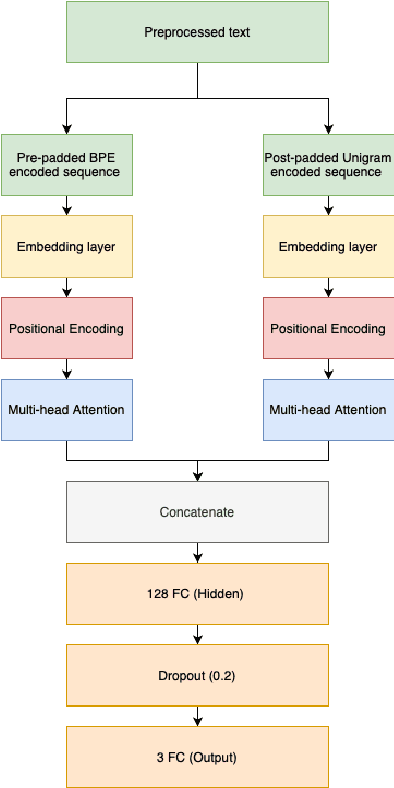
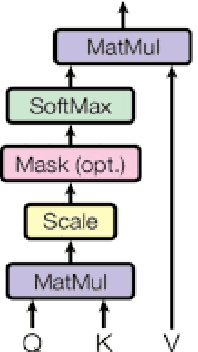
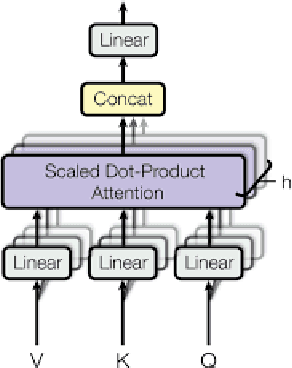
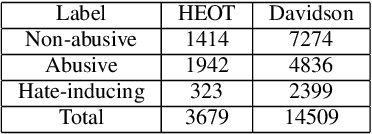
Recent advancements in technology have led to a boost in social media usage which has ultimately led to large amounts of user-generated data which also includes hateful and offensive speech. The language used in social media is often a combination of English and the native language in the region. In India, Hindi is used predominantly and is often code-switched with English, giving rise to the Hinglish (Hindi+English) language. Various approaches have been made in the past to classify the code-mixed Hinglish hate speech using different machine learning and deep learning-based techniques. However, these techniques make use of recurrence on convolution mechanisms which are computationally expensive and have high memory requirements. Past techniques also make use of complex data processing making the existing techniques very complex and non-sustainable to change in data. We propose a much simpler approach which is not only at par with these complex networks but also exceeds performance with the use of subword tokenization algorithms like BPE and Unigram along with multi-head attention-based technique giving an accuracy of 87.41% and F1 score of 0.851 on standard datasets. Efficient use of BPE and Unigram algorithms help handle the non-conventional Hinglish vocabulary making our technique simple, efficient and sustainable to use in the real world.
Comparative Study of Long Document Classification
Nov 01, 2021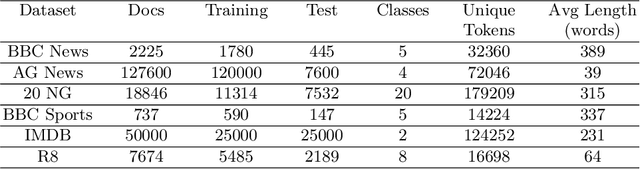
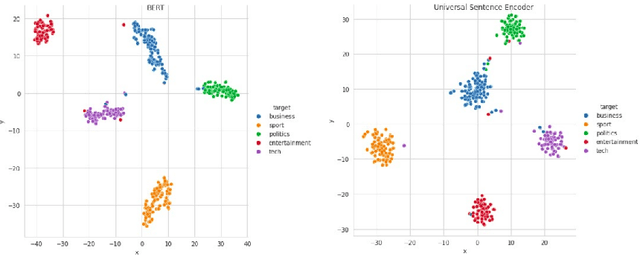
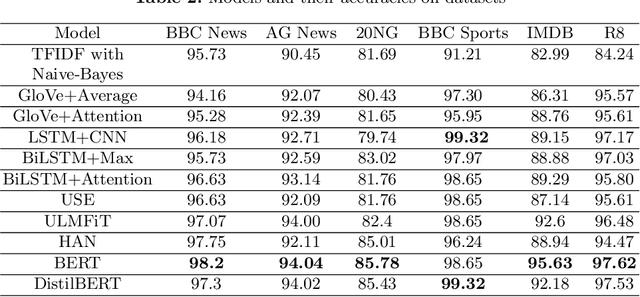
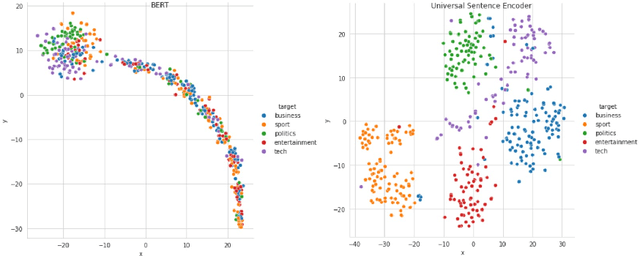
The amount of information stored in the form of documents on the internet has been increasing rapidly. Thus it has become a necessity to organize and maintain these documents in an optimum manner. Text classification algorithms study the complex relationships between words in a text and try to interpret the semantics of the document. These algorithms have evolved significantly in the past few years. There has been a lot of progress from simple machine learning algorithms to transformer-based architectures. However, existing literature has analyzed different approaches on different data sets thus making it difficult to compare the performance of machine learning algorithms. In this work, we revisit long document classification using standard machine learning approaches. We benchmark approaches ranging from simple Naive Bayes to complex BERT on six standard text classification datasets. We present an exhaustive comparison of different algorithms on a range of long document datasets. We re-iterate that long document classification is a simpler task and even basic algorithms perform competitively with BERT-based approaches on most of the datasets. The BERT-based models perform consistently well on all the datasets and can be blindly used for the document classification task when the computations cost is not a concern. In the shallow model's category, we suggest the usage of raw BiLSTM + Max architecture which performs decently across all the datasets. Even simpler Glove + Attention bag of words model can be utilized for simpler use cases. The importance of using sophisticated models is clearly visible in the IMDB sentiment dataset which is a comparatively harder task.
Evaluating Deep Learning Approaches for Covid19 Fake News Detection
Jan 13, 2021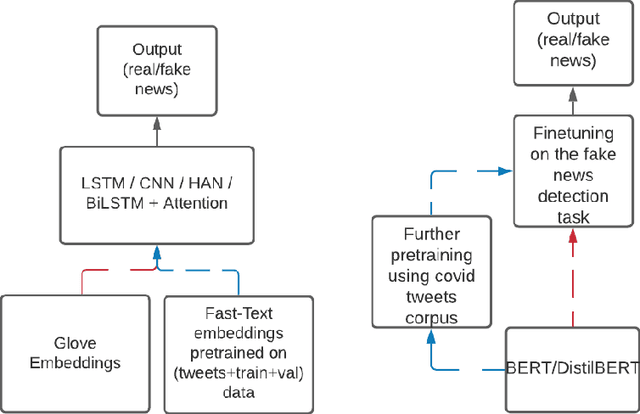

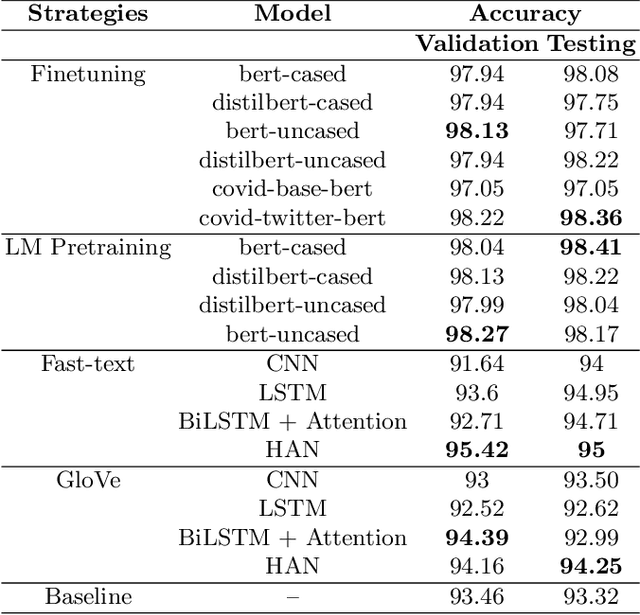
Social media platforms like Facebook, Twitter, and Instagram have enabled connection and communication on a large scale. It has revolutionized the rate at which information is shared and enhanced its reach. However, another side of the coin dictates an alarming story. These platforms have led to an increase in the creation and spread of fake news. The fake news has not only influenced people in the wrong direction but also claimed human lives. During these critical times of the Covid19 pandemic, it is easy to mislead people and make them believe in fatal information. Therefore it is important to curb fake news at source and prevent it from spreading to a larger audience. We look at automated techniques for fake news detection from a data mining perspective. We evaluate different supervised text classification algorithms on Contraint@AAAI 2021 Covid-19 Fake news detection dataset. The classification algorithms are based on Convolutional Neural Networks (CNN), Long Short Term Memory (LSTM), and Bidirectional Encoder Representations from Transformers (BERT). We also evaluate the importance of unsupervised learning in the form of language model pre-training and distributed word representations using unlabelled covid tweets corpus. We report the best accuracy of 98.41\% on the Covid-19 Fake news detection dataset.