 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtteSTNet -- An attention and subword tokenization based approach for code-switched Hindi-English hate speech detection
Paper and Code
Dec 10, 2021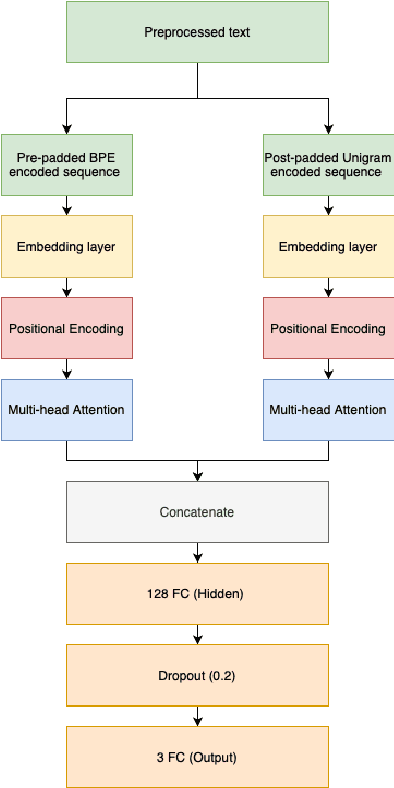
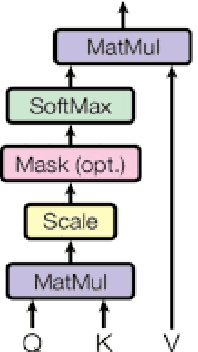
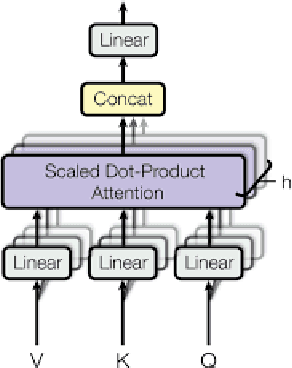
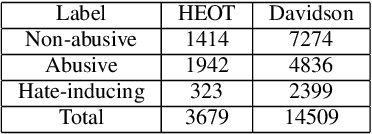
Recent advancements in technology have led to a boost in social media usage which has ultimately led to large amounts of user-generated data which also includes hateful and offensive speech. The language used in social media is often a combination of English and the native language in the region. In India, Hindi is used predominantly and is often code-switched with English, giving rise to the Hinglish (Hindi+English) language. Various approaches have been made in the past to classify the code-mixed Hinglish hate speech using different machine learning and deep learning-based techniques. However, these techniques make use of recurrence on convolution mechanisms which are computationally expensive and have high memory requirements. Past techniques also make use of complex data processing making the existing techniques very complex and non-sustainable to change in data. We propose a much simpler approach which is not only at par with these complex networks but also exceeds performance with the use of subword tokenization algorithms like BPE and Unigram along with multi-head attention-based technique giving an accuracy of 87.41% and F1 score of 0.851 on standard datasets. Efficient use of BPE and Unigram algorithms help handle the non-conventional Hinglish vocabulary making our technique simple, efficient and sustainable to use in the real world.