 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonnet: Spectral Operator Neural Network for Multivariable Time Series Forecasting
May 21, 2025Multivariable time series forecasting methods can integrate information from exogenous variables, leading to significant prediction accuracy gains. Transformer architecture has been widely applied in various time series forecasting models due to its ability to capture long-range sequential dependencies. However, a na\"ive application of transformers often struggles to effectively model complex relationships among variables over time. To mitigate against this, we propose a novel architecture, namely the Spectral Operator Neural Network (Sonnet). Sonnet applies learnable wavelet transformations to the input and incorporates spectral analysis using the Koopman operator. Its predictive skill relies on the Multivariable Coherence Attention (MVCA), an operation that leverages spectral coherence to model variable dependencies. Our empirical analysis shows that Sonnet yields the best performance on $34$ out of $47$ forecasting tasks with an average mean absolute error (MAE) reduction of $1.1\%$ against the most competitive baseline (different per task). We further show that MVCA -- when put in place of the na\"ive attention used in various deep learning models -- can remedy its deficiencies, reducing MAE by $10.7\%$ on average in the most challenging forecasting tasks.
Machine-generated text detection prevents language model collapse
Feb 21, 2025As Large Language Models (LLMs) become increasingly prevalent, their generated outputs are proliferating across the web, risking a future where machine-generated content dilutes human-authored text. Since web data is the primary resource for LLM pretraining, future models will be trained on an unknown portion of synthetic data. This will lead to model collapse, a degenerative process which causes models to reinforce their own errors and experience a drop in model performance. In this study, we investigate the impact of decoding strategy on model collapse, where we analyse the characteristics of the generated data during recursive training, its similarity to human references and the resulting model performance. Using the decoding strategies that lead to the most significant model degradation, we tackle the question: how to avoid model collapse when the origin (human or synthetic) of the training data is unknown. We design a novel methodology based on resampling the data distribution using importance weights from our machine-generated text detector. Our method is validated on two LLM variants (GPT-2 and SmolLM2) on the open-ended text generation task, demonstrating that we can successfully prevent model collapse and when there is enough human-authored data in the training dataset, our method improves model performance.
DeformTime: Capturing Variable Dependencies with Deformable Attention for Time Series Forecasting
Jun 11, 2024



In multivariate time series (MTS) forecasting, existing state-of-the-art deep learning approaches tend to focus on autoregressive formulations and overlook the information within exogenous indicators. To address this limitation, we present DeformTime, a neural network architecture that attempts to capture correlated temporal patterns from the input space, and hence, improve forecasting accuracy. It deploys two core operations performed by deformable attention blocks (DABs): learning dependencies across variables from different time steps (variable DAB), and preserving temporal dependencies in data from previous time steps (temporal DAB). Input data transformation is explicitly designed to enhance learning from the deformed series of information while passing through a DAB. We conduct extensive experiments on 6 MTS data sets, using previously established benchmarks as well as challenging infectious disease modelling tasks with more exogenous variables. The results demonstrate that DeformTime improves accuracy against previous competitive methods across the vast majority of MTS forecasting tasks, reducing the mean absolute error by 10% on average. Notably, performance gains remain consistent across longer forecasting horizons.
Unsupervised hard Negative Augmentation for contrastive learning
Jan 05, 2024


We present Unsupervised hard Negative Augmentation (UNA), a method that generates synthetic negative instances based on the term frequency-inverse document frequency (TF-IDF) retrieval model. UNA uses TF-IDF scores to ascertain the perceived importance of terms in a sentence and then produces negative samples by replacing terms with respect to that. Our experiments demonstrate that models trained with UNA improve the overall performance in semantic textual similarity tasks. Additional performance gains are obtained when combining UNA with the paraphrasing augmentation. Further results show that our method is compatible with different backbone models. Ablation studies also support the choice of having a TF-IDF-driven control on negative augmentation.
E-NER -- An Annotated Named Entity Recognition Corpus of Legal Text
Dec 19, 2022



Identifying named entities such as a person, location or organization, in documents can highlight key information to readers. Training Named Entity Recognition (NER) models requires an annotated data set, which can be a time-consuming labour-intensive task. Nevertheless, there are publicly available NER data sets for general English. Recently there has been interest in developing NER for legal text. However, prior work and experimental results reported here indicate that there is a significant degradation in performance when NER methods trained on a general English data set are applied to legal text. We describe a publicly available legal NER data set, called E-NER, based on legal company filings available from the US Securities and Exchange Commission's EDGAR data set. Training a number of different NER algorithms on the general English CoNLL-2003 corpus but testing on our test collection confirmed significant degradations in accuracy, as measured by the F1-score, of between 29.4\% and 60.4\%, compared to training and testing on the E-NER collection.
Estimating the Uncertainty of Neural Network Forecasts for Influenza Prevalence Using Web Search Activity
May 26, 2021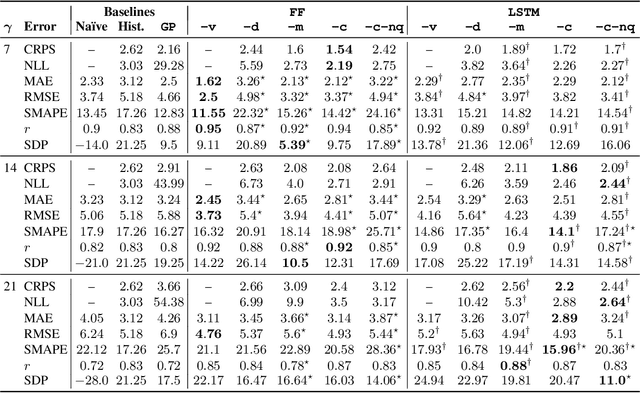
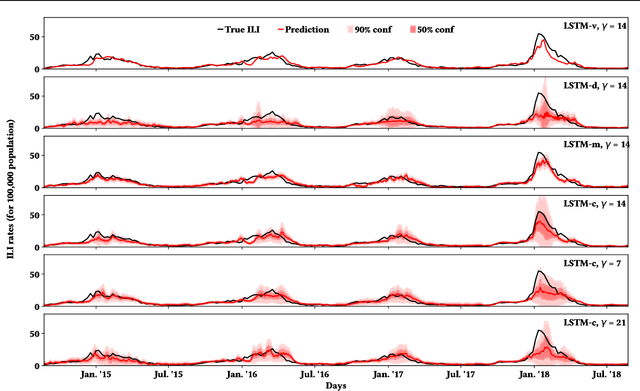
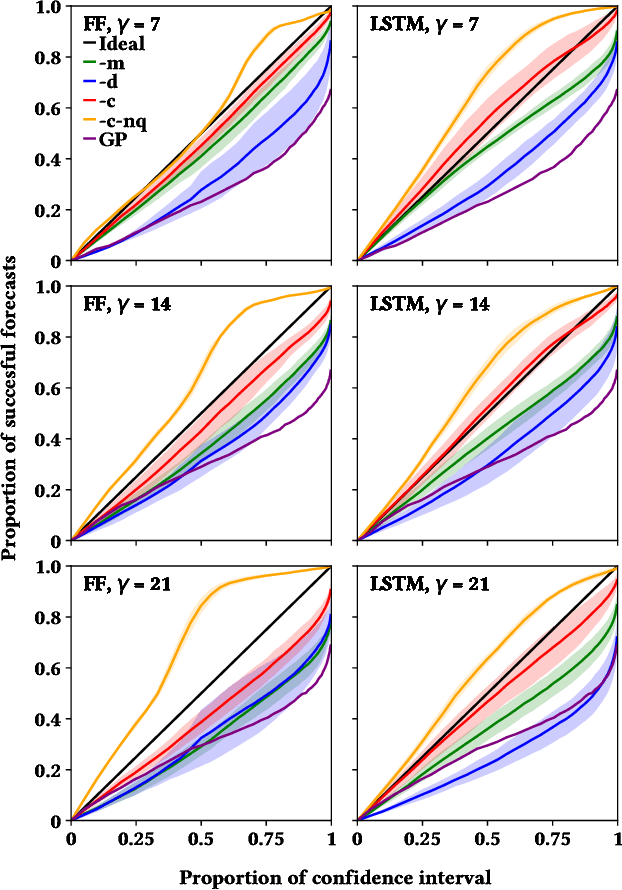
Influenza is an infectious disease with the potential to become a pandemic, and hence, forecasting its prevalence is an important undertaking for planning an effective response. Research has found that web search activity can be used to improve influenza models. Neural networks (NN) can provide state-of-the-art forecasting accuracy but do not commonly incorporate uncertainty in their estimates, something essential for using them effectively during decision making. In this paper, we demonstrate how Bayesian Neural Networks (BNNs) can be used to both provide a forecast and a corresponding uncertainty without significant loss in forecasting accuracy compared to traditional NNs. Our method accounts for two sources of uncertainty: data and model uncertainty, arising due to measurement noise and model specification, respectively. Experiments are conducted using 14 years of data for England, assessing the model's accuracy over the last 4 flu seasons in this dataset. We evaluate the performance of different models including competitive baselines with conventional metrics as well as error functions that incorporate uncertainty estimates. Our empirical analysis indicates that considering both sources of uncertainty simultaneously is superior to considering either one separately. We also show that a BNN with recurrent layers that models both sources of uncertainty yields superior accuracy for these metrics for forecasting horizons greater than 7 days.
Flu Detector: Estimating influenza-like illness rates from online user-generated content
Dec 11, 2016
We provide a brief technical description of an online platform for disease monitoring, titled as the Flu Detector (fludetector.cs.ucl.ac.uk). Flu Detector, in its current version (v.0.5), uses either Twitter or Google search data in conjunction with statistical Natural Language Processing models to estimate the rate of influenza-like illness in the population of England. Its back-end is a live service that collects online data, utilises modern technologies for large-scale text processing, and finally applies statistical inference models that are trained offline. The front-end visualises the various disease rate estimates. Notably, the models based on Google data achieve a high level of accuracy with respect to the most recent four flu seasons in England (2012/13 to 2015/16). This highlighted Flu Detector as having a great potential of becoming a complementary source to the domestic traditional flu surveillance schemes.
Detecting Events and Patterns in Large-Scale User Generated Textual Streams with Statistical Learning Methods
Aug 13, 2012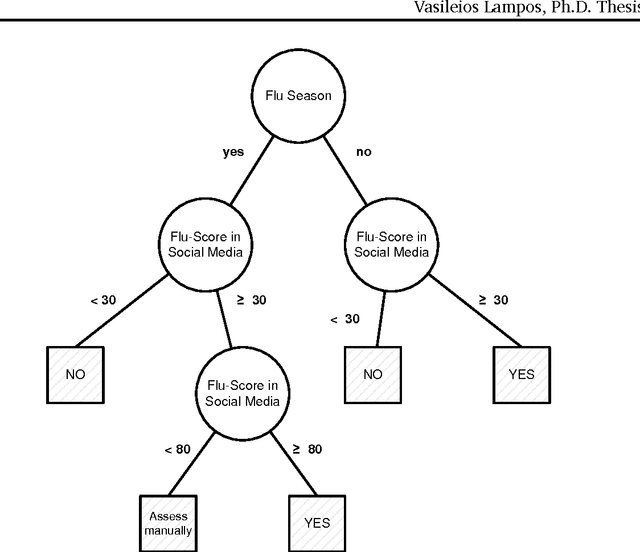

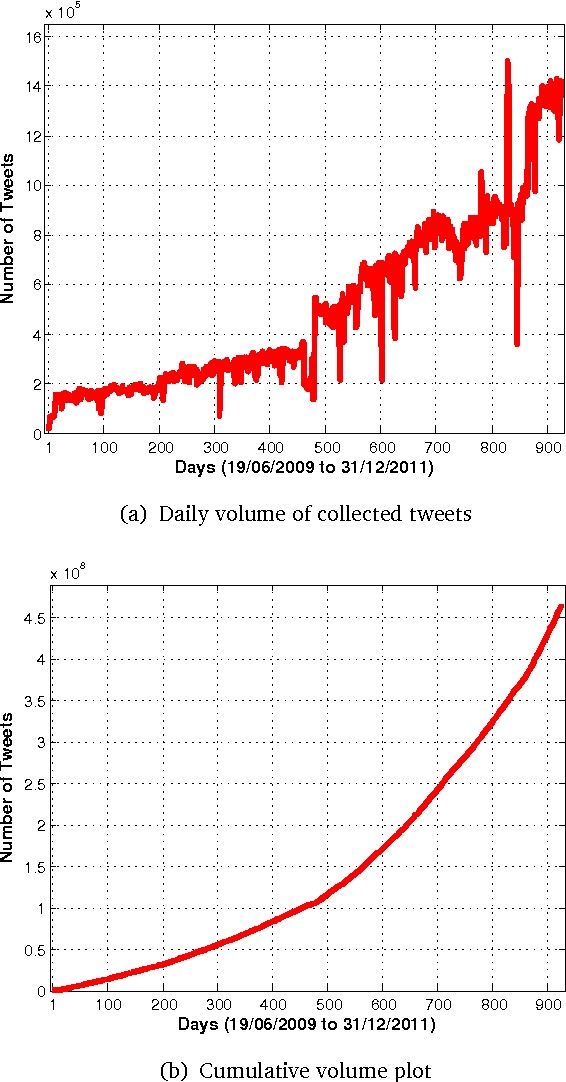
A vast amount of textual web streams is influenced by events or phenomena emerging in the real world. The social web forms an excellent modern paradigm, where unstructured user generated content is published on a regular basis and in most occasions is freely distributed. The present Ph.D. Thesis deals with the problem of inferring information - or patterns in general - about events emerging in real life based on the contents of this textual stream. We show that it is possible to extract valuable information about social phenomena, such as an epidemic or even rainfall rates, by automatic analysis of the content published in Social Media, and in particular Twitter, using Statistical Machine Learning methods. An important intermediate task regards the formation and identification of features which characterise a target event; we select and use those textual features in several linear, non-linear and hybrid inference approaches achieving a significantly good performance in terms of the applied loss function. By examining further this rich data set, we also propose methods for extracting various types of mood signals revealing how affective norms - at least within the social web's population - evolve during the day and how significant events emerging in the real world are influencing them. Lastly, we present some preliminary findings showing several spatiotemporal characteristics of this textual information as well as the potential of using it to tackle tasks such as the prediction of voting intentions.