 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-generated text detection prevents language model collapse
Feb 21, 2025As Large Language Models (LLMs) become increasingly prevalent, their generated outputs are proliferating across the web, risking a future where machine-generated content dilutes human-authored text. Since web data is the primary resource for LLM pretraining, future models will be trained on an unknown portion of synthetic data. This will lead to model collapse, a degenerative process which causes models to reinforce their own errors and experience a drop in model performance. In this study, we investigate the impact of decoding strategy on model collapse, where we analyse the characteristics of the generated data during recursive training, its similarity to human references and the resulting model performance. Using the decoding strategies that lead to the most significant model degradation, we tackle the question: how to avoid model collapse when the origin (human or synthetic) of the training data is unknown. We design a novel methodology based on resampling the data distribution using importance weights from our machine-generated text detector. Our method is validated on two LLM variants (GPT-2 and SmolLM2) on the open-ended text generation task, demonstrating that we can successfully prevent model collapse and when there is enough human-authored data in the training dataset, our method improves model performance.
CC-SGG: Corner Case Scenario Generation using Learned Scene Graphs
Sep 18, 2023


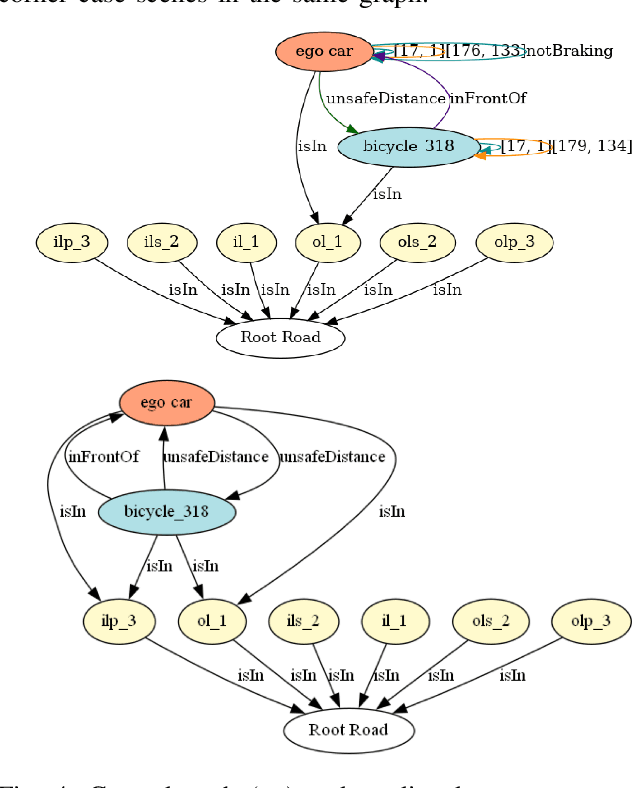
Corner case scenarios are an essential tool for testing and validating the safety of autonomous vehicles (AVs). As these scenarios are often insufficiently present in naturalistic driving datasets, augmenting the data with synthetic corner cases greatly enhances the safe operation of AVs in unique situations. However, the generation of synthetic, yet realistic, corner cases poses a significant challenge. In this work, we introduce a novel approach based on Heterogeneous Graph Neural Networks (HGNNs) to transform regular driving scenarios into corner cases. To achieve this, we first generate concise representations of regular driving scenes as scene graphs, minimally manipulating their structure and properties. Our model then learns to perturb those graphs to generate corner cases using attention and triple embeddings. The input and perturbed graphs are then imported back into the simulation to generate corner case scenarios. Our model successfully learned to produce corner cases from input scene graphs, achieving 89.9% prediction accuracy on our testing dataset. We further validate the generated scenarios on baseline autonomous driving methods, demonstrating our model's ability to effectively create critical situations for the baselines.