 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIC-SR-ICD11: A Dataset for Narrative-Based Diagnosis
Nov 07, 2025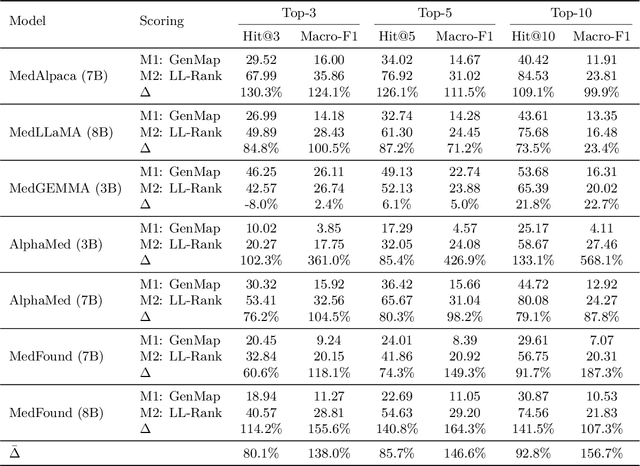
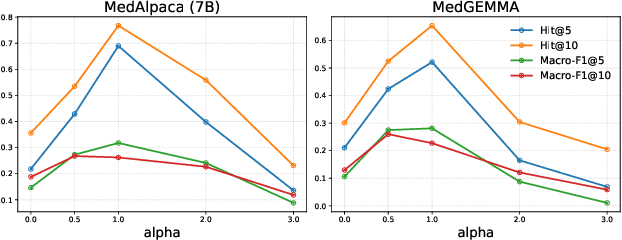
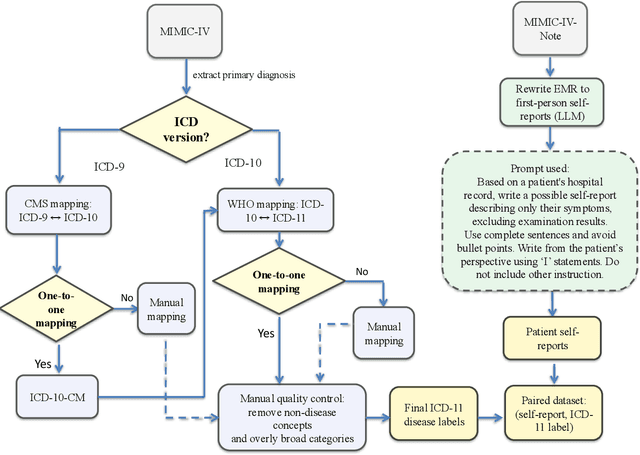
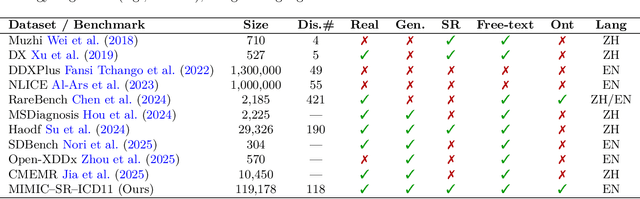
Disease diagnosis is a central pillar of modern healthcare, enabling early detection and timely intervention for acute conditions while guiding lifestyle adjustments and medication regimens to prevent or slow chronic disease. Self-reports preserve clinically salient signals that templated electronic health record (EHR) documentation often attenuates or omits, especially subtle but consequential details. To operationalize this shift, we introduce MIMIC-SR-ICD11, a large English diagnostic dataset built from EHR discharge notes and natively aligned to WHO ICD-11 terminology. We further present LL-Rank, a likelihood-based re-ranking framework that computes a length-normalized joint likelihood of each label given the clinical report context and subtracts the corresponding report-free prior likelihood for that label. Across seven model backbones, LL-Rank consistently outperforms a strong generation-plus-mapping baseline (GenMap). Ablation experiments show that LL-Rank's gains primarily stem from its PMI-based scoring, which isolates semantic compatibility from label frequency bias.
Automated Assessment of Students' Code Comprehension using LLMs
Dec 19, 2023Assessing student's answers and in particular natural language answers is a crucial challenge in the field of education. Advances in machine learning, including transformer-based models such as Large Language Models(LLMs), have led to significant progress in various natural language tasks. Nevertheless, amidst the growing trend of evaluating LLMs across diverse tasks, evaluating LLMs in the realm of automated answer assesment has not received much attention. To address this gap, we explore the potential of using LLMs for automated assessment of student's short and open-ended answer. Particularly, we use LLMs to compare students' explanations with expert explanations in the context of line-by-line explanations of computer programs. For comparison purposes, we assess both Large Language Models (LLMs) and encoder-based Semantic Textual Similarity (STS) models in the context of assessing the correctness of students' explanation of computer code. Our findings indicate that LLMs, when prompted in few-shot and chain-of-thought setting perform comparable to fine-tuned encoder-based models in evaluating students' short answers in programming domain.
The Behavior of Large Language Models When Prompted to Generate Code Explanations
Nov 09, 2023This paper systematically investigates the generation of code explanations by Large Language Models (LLMs) for code examples commonly encountered in introductory programming courses. Our findings reveal significant variations in the nature of code explanations produced by LLMs, influenced by factors such as the wording of the prompt, the specific code examples under consideration, the programming language involved, the temperature parameter, and the version of the LLM. However, a consistent pattern emerges for Java and Python, where explanations exhibit a Flesch-Kincaid readability level of approximately 7-8 grade and a consistent lexical density, indicating the proportion of meaningful words relative to the total explanation size. Additionally, the generated explanations consistently achieve high scores for correctness, but lower scores on three other metrics: completeness, conciseness, and specificity.
Scalable and Equitable Math Problem Solving Strategy Prediction in Big Educational Data
Aug 07, 2023Understanding a student's problem-solving strategy can have a significant impact on effective math learning using Intelligent Tutoring Systems (ITSs) and Adaptive Instructional Systems (AISs). For instance, the ITS/AIS can better personalize itself to correct specific misconceptions that are indicated by incorrect strategies, specific problems can be designed to improve strategies and frustration can be minimized by adapting to a student's natural way of thinking rather than trying to fit a standard strategy for all. While it may be possible for human experts to identify strategies manually in classroom settings with sufficient student interaction, it is not possible to scale this up to big data. Therefore, we leverage advances in Machine Learning and AI methods to perform scalable strategy prediction that is also fair to students at all skill levels. Specifically, we develop an embedding called MVec where we learn a representation based on the mastery of students. We then cluster these embeddings with a non-parametric clustering method where we progressively learn clusters such that we group together instances that have approximately symmetrical strategies. The strategy prediction model is trained on instances sampled from these clusters. This ensures that we train the model over diverse strategies and also that strategies from a particular group do not bias the DNN model, thus allowing it to optimize its parameters over all groups. Using real world large-scale student interaction datasets from MATHia, we implement our approach using transformers and Node2Vec for learning the mastery embeddings and LSTMs for predicting strategies. We show that our approach can scale up to achieve high accuracy by training on a small sample of a large dataset and also has predictive equality, i.e., it can predict strategies equally well for learners at diverse skill levels.