 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Word Suggestion using Graph Neural Network
May 13, 2025Language Modeling is a prevalent task in Natural Language Processing. The currently existing most recent and most successful language models often tend to build a massive model with billions of parameters, feed in a tremendous amount of text data, and train with enormous computation resources which require millions of dollars. In this project, we aim to address an important sub-task in language modeling, i.e., context embedding. We propose an approach to exploit the Graph Convolution operation in GNNs to encode the context and use it in coalition with LSTMs to predict the next word given a local context of preceding words. We test this on the custom Wikipedia text corpus using a very limited amount of resources and show that this approach works fairly well to predict the next word.
Verifying Relational Explanations: A Probabilistic Approach
Jan 05, 2024Explanations on relational data are hard to verify since the explanation structures are more complex (e.g. graphs). To verify interpretable explanations (e.g. explanations of predictions made in images, text, etc.), typically human subjects are used since it does not necessarily require a lot of expertise. However, to verify the quality of a relational explanation requires expertise and is hard to scale-up. GNNExplainer is arguably one of the most popular explanation methods for Graph Neural Networks. In this paper, we develop an approach where we assess the uncertainty in explanations generated by GNNExplainer. Specifically, we ask the explainer to generate explanations for several counterfactual examples. We generate these examples as symmetric approximations of the relational structure in the original data. From these explanations, we learn a factor graph model to quantify uncertainty in an explanation. Our results on several datasets show that our approach can help verify explanations from GNNExplainer by reliably estimating the uncertainty of a relation specified in the explanation.
On the verification of Embeddings using Hybrid Markov Logic
Dec 13, 2023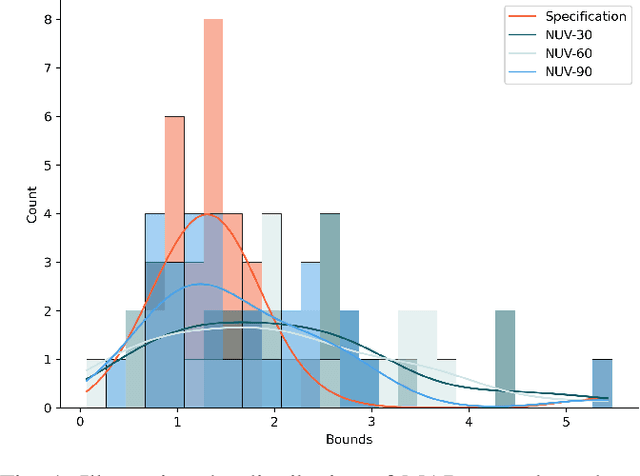



The standard approach to verify representations learned by Deep Neural Networks is to use them in specific tasks such as classification or regression, and measure their performance based on accuracy in such tasks. However, in many cases, we would want to verify more complex properties of a learned representation. To do this, we propose a framework based on a probabilistic first-order language, namely, Hybrid Markov Logic Networks (HMLNs) where we specify properties over embeddings mixed with symbolic domain knowledge. We present an approach to learn parameters for the properties within this framework. Further, we develop a verification method to test embeddings in this framework by encoding this task as a Mixed Integer Linear Program for which we can leverage existing state-of-the-art solvers. We illustrate verification in Graph Neural Networks, Deep Knowledge Tracing and Intelligent Tutoring Systems to demonstrate the generality of our approach.
Scalable and Equitable Math Problem Solving Strategy Prediction in Big Educational Data
Aug 07, 2023Understanding a student's problem-solving strategy can have a significant impact on effective math learning using Intelligent Tutoring Systems (ITSs) and Adaptive Instructional Systems (AISs). For instance, the ITS/AIS can better personalize itself to correct specific misconceptions that are indicated by incorrect strategies, specific problems can be designed to improve strategies and frustration can be minimized by adapting to a student's natural way of thinking rather than trying to fit a standard strategy for all. While it may be possible for human experts to identify strategies manually in classroom settings with sufficient student interaction, it is not possible to scale this up to big data. Therefore, we leverage advances in Machine Learning and AI methods to perform scalable strategy prediction that is also fair to students at all skill levels. Specifically, we develop an embedding called MVec where we learn a representation based on the mastery of students. We then cluster these embeddings with a non-parametric clustering method where we progressively learn clusters such that we group together instances that have approximately symmetrical strategies. The strategy prediction model is trained on instances sampled from these clusters. This ensures that we train the model over diverse strategies and also that strategies from a particular group do not bias the DNN model, thus allowing it to optimize its parameters over all groups. Using real world large-scale student interaction datasets from MATHia, we implement our approach using transformers and Node2Vec for learning the mastery embeddings and LSTMs for predicting strategies. We show that our approach can scale up to achieve high accuracy by training on a small sample of a large dataset and also has predictive equality, i.e., it can predict strategies equally well for learners at diverse skill levels.