 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing multiple LLMs for Information Retrieval: A case study on Deep Learning methodologies in Biodiversity publications
Nov 14, 2024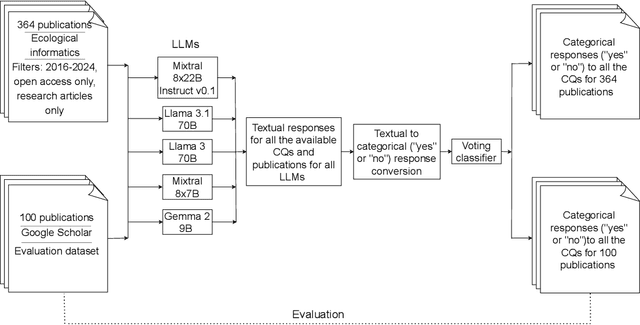
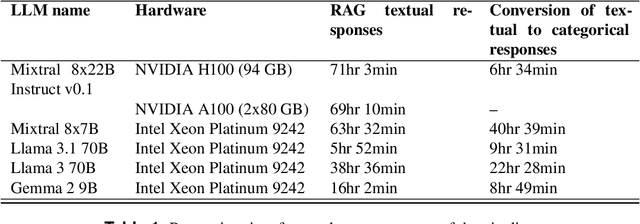


Deep Learning (DL) techniques are increasingly applied in scientific studies across various domains to address complex research questions. However, the methodological details of these DL models are often hidden in the unstructured text. As a result, critical information about how these models are designed, trained, and evaluated is challenging to access and comprehend. To address this issue, in this work, we use five different open-source Large Language Models (LLMs): Llama-3 70B, Llama-3.1 70B, Mixtral-8x22B-Instruct-v0.1, Mixtral 8x7B, and Gemma 2 9B in combination with Retrieval-Augmented Generation (RAG) approach to extract and process DL methodological details from scientific publications automatically. We built a voting classifier from the outputs of five LLMs to accurately report DL methodological information. We tested our approach using biodiversity publications, building upon our previous research. To validate our pipeline, we employed two datasets of DL-related biodiversity publications: a curated set of 100 publications from our prior work and a set of 364 publications from the Ecological Informatics journal. Our results demonstrate that the multi-LLM, RAG-assisted pipeline enhances the retrieval of DL methodological information, achieving an accuracy of 69.5% (417 out of 600 comparisons) based solely on textual content from publications. This performance was assessed against human annotators who had access to code, figures, tables, and other supplementary information. Although demonstrated in biodiversity, our methodology is not limited to this field; it can be applied across other scientific domains where detailed methodological reporting is essential for advancing knowledge and ensuring reproducibility. This study presents a scalable and reliable approach for automating information extraction, facilitating better reproducibility and knowledge transfer across studies.
Evaluating the method reproducibility of deep learning models in the biodiversity domain
Jul 10, 2024Artificial Intelligence (AI) is revolutionizing biodiversity research by enabling advanced data analysis, species identification, and habitats monitoring, thereby enhancing conservation efforts. Ensuring reproducibility in AI-driven biodiversity research is crucial for fostering transparency, verifying results, and promoting the credibility of ecological findings.This study investigates the reproducibility of deep learning (DL) methods within the biodiversity domain. We design a methodology for evaluating the reproducibility of biodiversity-related publications that employ DL techniques across three stages. We define ten variables essential for method reproducibility, divided into four categories: resource requirements, methodological information, uncontrolled randomness, and statistical considerations. These categories subsequently serve as the basis for defining different levels of reproducibility. We manually extract the availability of these variables from a curated dataset comprising 61 publications identified using the keywords provided by biodiversity experts. Our study shows that the dataset is shared in 47% of the publications; however, a significant number of the publications lack comprehensive information on deep learning methods, including details regarding randomness.
From human experts to machines: An LLM supported approach to ontology and knowledge graph construction
Mar 13, 2024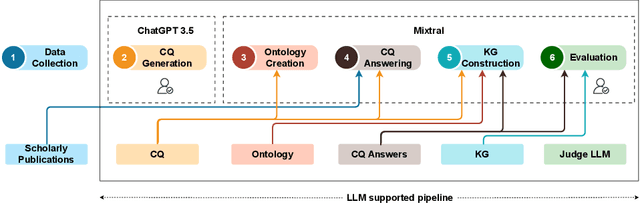
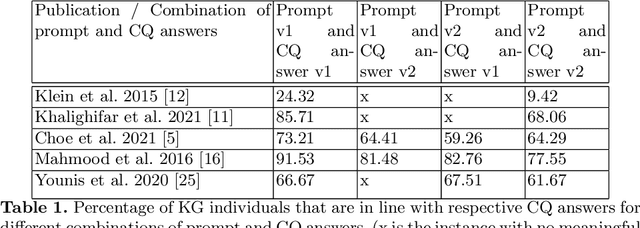
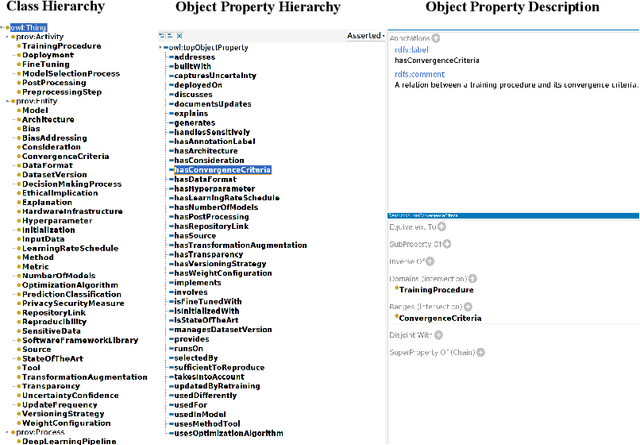
The conventional process of building Ontologies and Knowledge Graphs (KGs) heavily relies on human domain experts to define entities and relationship types, establish hierarchies, maintain relevance to the domain, fill the ABox (or populate with instances), and ensure data quality (including amongst others accuracy and completeness). On the other hand, Large Language Models (LLMs) have recently gained popularity for their ability to understand and generate human-like natural language, offering promising ways to automate aspects of this process. This work explores the (semi-)automatic construction of KGs facilitated by open-source LLMs. Our pipeline involves formulating competency questions (CQs), developing an ontology (TBox) based on these CQs, constructing KGs using the developed ontology, and evaluating the resultant KG with minimal to no involvement of human experts. We showcase the feasibility of our semi-automated pipeline by creating a KG on deep learning methodologies by exploiting scholarly publications. To evaluate the answers generated via Retrieval-Augmented-Generation (RAG) as well as the KG concepts automatically extracted using LLMs, we design a judge LLM, which rates the generated content based on ground truth. Our findings suggest that employing LLMs could potentially reduce the human effort involved in the construction of KGs, although a human-in-the-loop approach is recommended to evaluate automatically generated KGs.