 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification and Risk Control for Multi-Speaker Sound Source Localization
Mar 18, 2026Reliable Sound Source Localization (SSL) plays an essential role in many downstream tasks, where informed decision making depends not only on accurate localization but also on the confidence in each estimate. This need for reliability becomes even more pronounced in challenging conditions, such as reverberant environments and multi-source scenarios. However, existing SSL methods typically provide only point estimates, offering limited or no Uncertainty Quantification (UQ). We leverage the Conformal Prediction (CP) framework and its extensions for controlling general risk functions to develop two complementary UQ approaches for SSL. The first assumes that the number of active sources is known and constructs prediction regions that cover the true source locations. The second addresses the more challenging setting where the source count is unknown, first reliably estimating the number of active sources and then forming corresponding prediction regions. We evaluate the proposed methods on extensive simulations and real-world recordings across varying reverberation levels and source configurations. Results demonstrate reliable finite-sample guarantees and consistent performance for both known and unknown source-count scenarios, highlighting the practical utility of the proposed frameworks for uncertainty-aware SSL.
Enhancing LMMSE Performance with Modest Complexity Increase via Neural Network Equalizers
Nov 03, 2024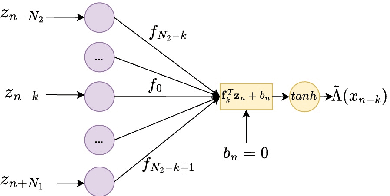
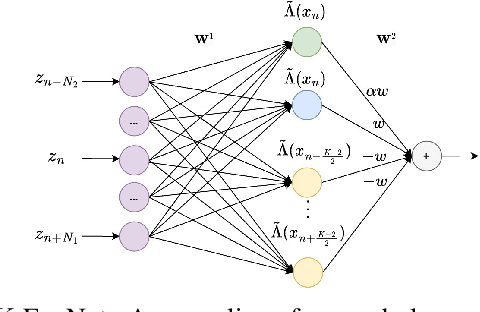
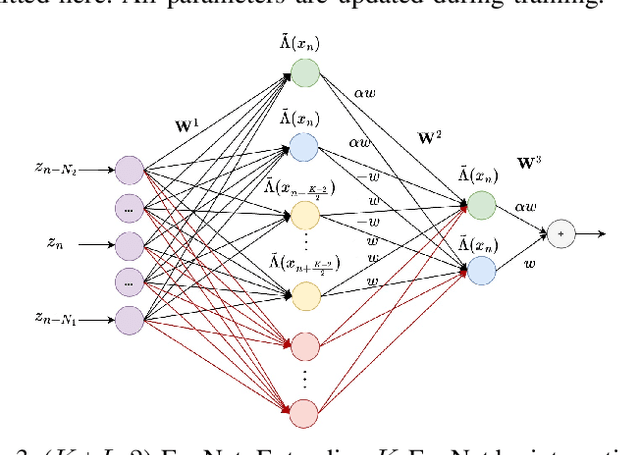
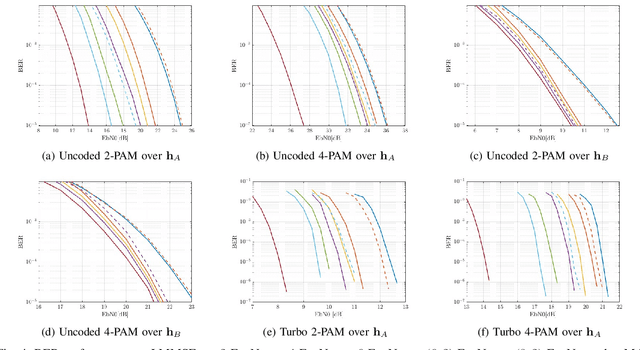
The BCJR algorithm is renowned for its optimal equalization, minimizing bit error rate (BER) over intersymbol interference (ISI) channels. However, its complexity grows exponentially with the channel memory, posing a significant computational burden. In contrast, the linear minimum mean square error (LMMSE) equalizer offers a notably simpler solution, albeit with reduced performance compared to the BCJR. Recently, Neural Network (NN) based equalizers have emerged as promising alternatives. Trained to map observations to the original transmitted symbols, these NNs demonstrate performance similar to the BCJR algorithm. However, they often entail a high number of learnable parameters, resulting in complexities comparable to or even larger than the BCJR. This paper explores the potential of NN-based equalization with a reduced number of learnable parameters and low complexity. We introduce a NN equalizer with complexity comparable to LMMSE, surpassing LMMSE performance and achieving a modest performance gap from the BCJR equalizer. A significant challenge with NNs featuring a limited parameter count is their susceptibility to converging to local minima, leading to suboptimal performance. To address this challenge, we propose a novel NN equalizer architecture with a unique initialization approach based on LMMSE. This innovative method effectively overcomes optimization challenges and enhances LMMSE performance, applicable both with and without turbo decoding.
Conformal Prediction for Manifold-based Source Localization with Gaussian Processes
Sep 18, 2024We tackle the challenge of uncertainty quantification in the localization of a sound source within adverse acoustic environments. Estimating the position of the source is influenced by various factors such as noise and reverberation, leading to significant uncertainty. Quantifying this uncertainty is essential, particularly when localization outcomes impact critical decision-making processes, such as in robot audition, where the accuracy of location estimates directly influences subsequent actions. Despite this, many localization methods typically offer point estimates without quantifying the estimation uncertainty. To address this, we employ conformal prediction (CP)-a framework that delivers statistically valid prediction intervals with finite-sample guarantees, independent of the data distribution. However, commonly used Inductive CP (ICP) methods require a substantial amount of labeled data, which can be difficult to obtain in the localization setting. To mitigate this limitation, we incorporate a manifold-based localization method using Gaussian process regression (GPR), with an efficient Transductive CP (TCP) technique specifically designed for GPR. We demonstrate that our method generates statistically valid uncertainty intervals across different acoustic conditions.