 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCLC: ROI-based joint conventional and learning video compression
Jul 14, 2021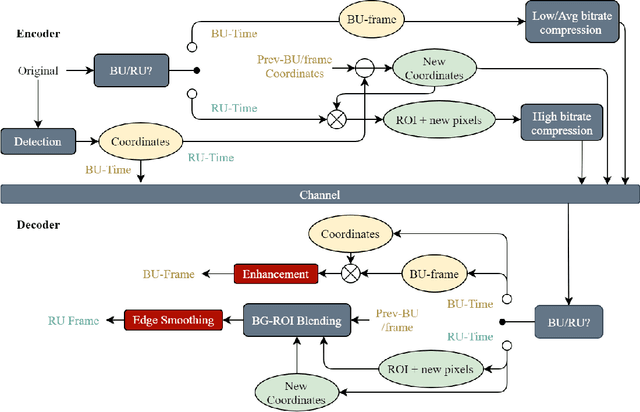
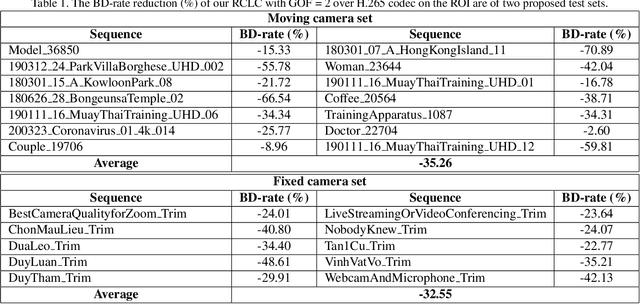

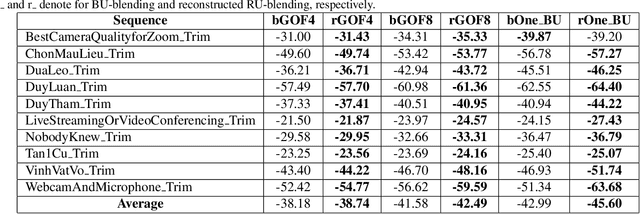
COVID-19 leads to the high demand for remote interactive systems ever seen. One of the key elements of these systems is video streaming, which requires a very high network bandwidth due to its specific real-time demand, especially with high-resolution video. Existing video compression methods are struggling in the trade-off between video quality and the speed requirement. Addressed that the background information rarely changes in most remote meeting cases, we introduce a Region-Of-Interests (ROI) based video compression framework (named RCLC) that leverages the cutting-edge learning-based and conventional technologies. In RCLC, each coming frame is marked as a background-updating (BU) or ROI-updating (RU) frame. By applying the conventional video codec, the BU frame is compressed with low-quality and high-compression, while the ROI from RU-frame is compressed with high-quality and low-compression. The learning-based methods are applied to detect the ROI, blend background-ROI, and enhance video quality. The experimental results show that our RCLC can reduce up to 32.55\% BD-rate for the ROI region compared to H.265 video codec under a similar compression time with 1080p resolution.
B-DRRN: A Block Information Constrained Deep Recursive Residual Network for Video Compression Artifacts Reduction
Jan 30, 2021



Although the video compression ratio nowadays becomes higher, the video coders such as H.264/AVC, H.265/HEVC, H.266/VVC always suffer from the video artifacts. In this paper, we design a neural network to enhance the quality of the compressed frame by leveraging the block information, called B-DRRN (Deep Recursive Residual Network with Block information). Firstly, an extra network branch is designed for leveraging the block information of the coding unit (CU). Moreover, to avoid a great increase in the network size, Recursive Residual structure and sharing weight techniques are applied. We also conduct a new large-scale dataset with 209,152 training samples. Experimental results show that the proposed B-DRRN can reduce 6.16% BD-rate compared to the HEVC standard. After efficiently adding an extra network branch, this work can improve the performance of the main network without increasing any memory for storing.
Image Compression with Encoder-Decoder Matched Semantic Segmentation
Jan 30, 2021



In recent years, layered image compression is demonstrated to be a promising direction, which encodes a compact representation of the input image and apply an up-sampling network to reconstruct the image. To further improve the quality of the reconstructed image, some works transmit the semantic segment together with the compressed image data. Consequently, the compression ratio is also decreased because extra bits are required for transmitting the semantic segment. To solve this problem, we propose a new layered image compression framework with encoder-decoder matched semantic segmentation (EDMS). And then, followed by the semantic segmentation, a special convolution neural network is used to enhance the inaccurate semantic segment. As a result, the accurate semantic segment can be obtained in the decoder without requiring extra bits. The experimental results show that the proposed EDMS framework can get up to 35.31% BD-rate reduction over the HEVC-based (BPG) codec, 5% bitrate, and 24% encoding time saving compare to the state-of-the-art semantic-based image codec.