 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoli-enabled Noncontact Heart Rate Detection for Sleep and Meditation Tracking
Jul 08, 2024Heart rate (HR) is a crucial physiological signal that can be used to monitor health and fitness. Traditional methods for measuring HR require wearable devices, which can be inconvenient or uncomfortable, especially during sleep and meditation. Noncontact HR detection methods employing microwave radar can be a promising alternative. However, the existing approaches in the literature usually use high-gain antennas and require the sensor to face the user's chest or back, making them difficult to integrate into a portable device and unsuitable for sleep and meditation tracking applications. This study presents a novel approach for noncontact HR detection using a miniaturized Soli radar chip embedded in a portable device (Google Nest Hub). The chip has a $6.5 \mbox{ mm} \times 5 \mbox{ mm} \times 0.9 \mbox{ mm}$ dimension and can be easily integrated into various devices. The proposed approach utilizes advanced signal processing and machine learning techniques to extract HRs from radar signals. The approach is validated on a sleep dataset (62 users, 498 hours) and a meditation dataset (114 users, 1131 minutes). The approach achieves a mean absolute error (MAE) of $1.69$ bpm and a mean absolute percentage error (MAPE) of $2.67\%$ on the sleep dataset. On the meditation dataset, the approach achieves an MAE of $1.05$ bpm and a MAPE of $1.56\%$. The recall rates for the two datasets are $88.53\%$ and $98.16\%$, respectively. This study represents the first application of the noncontact HR detection technology to sleep and meditation tracking, offering a promising alternative to wearable devices for HR monitoring during sleep and meditation.
* 15 pages
Enhancing User Experience in On-Device Machine Learning with Gated Compression Layers
May 02, 2024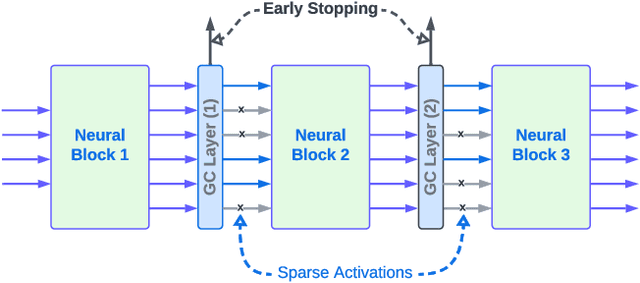
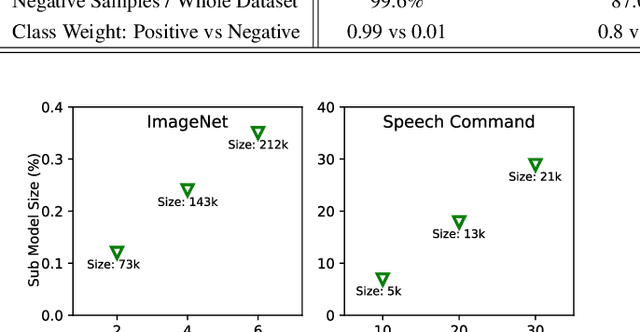
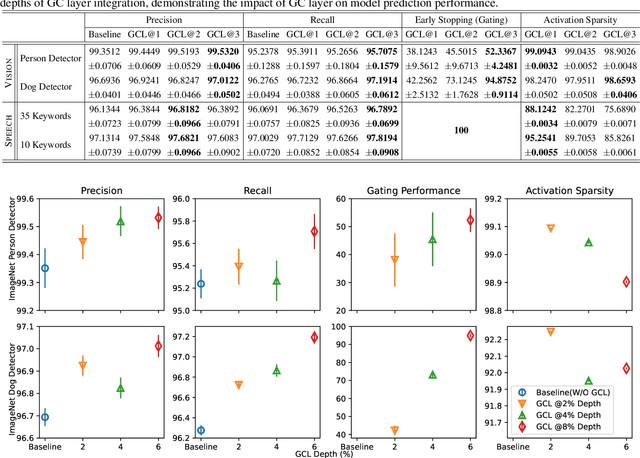
On-device machine learning (ODML) enables powerful edge applications, but power consumption remains a key challenge for resource-constrained devices. To address this, developers often face a trade-off between model accuracy and power consumption, employing either computationally intensive models on high-power cores or pared-down models on low-power cores. Both approaches typically lead to a compromise in user experience (UX). This work focuses on the use of Gated Compression (GC) layer to enhance ODML model performance while conserving power and maximizing cost-efficiency, especially for always-on use cases. GC layers dynamically regulate data flow by selectively gating activations of neurons within the neural network and effectively filtering out non-essential inputs, which reduces power needs without compromising accuracy, and enables more efficient execution on heterogeneous compute cores. These improvements enhance UX through prolonged battery life, improved device responsiveness, and greater user comfort. In this work, we have integrated GC layers into vision and speech domain models including the transformer-based ViT model. Our experiments demonstrate theoretical power efficiency gains ranging from 158x to 30,000x for always-on scenarios. This substantial improvement empowers ODML applications with enhanced UX benefits.
Dynamic Switch Layers For Unsupervised Learning
Apr 05, 2024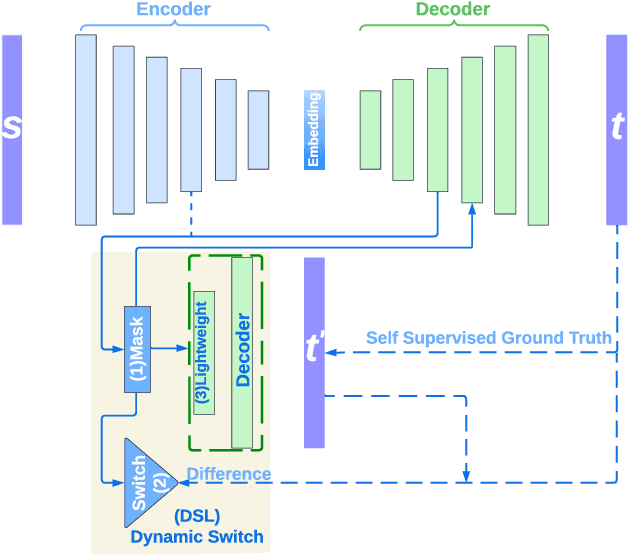
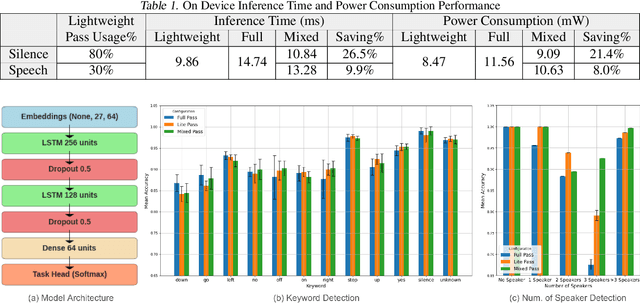
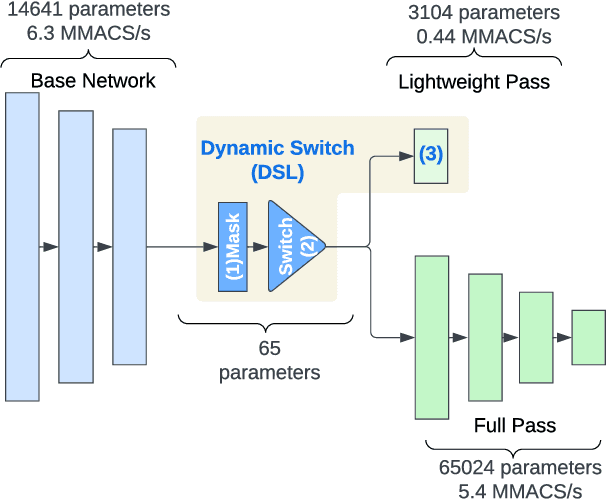
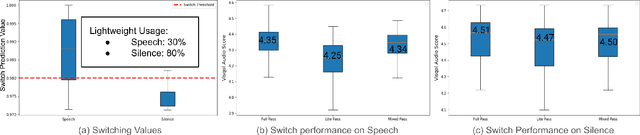
On-device machine learning (ODML) enables intelligent applications on resource-constrained devices. However, power consumption poses a major challenge, forcing a trade-off between model accuracy and power efficiency that often limits model complexity. The previously established Gated Compression (GC) layers offer a solution, enabling power efficiency without sacrificing model performance by selectively gating samples that lack signals of interest. However, their reliance on ground truth labels limits GC layers to supervised tasks. This work introduces the Dynamic Switch Layer (DSL), extending the benefits of GC layers to unsupervised learning scenarios, and maintaining power efficiency without the need for labeled data. The DSL builds upon the GC architecture, leveraging a dynamic pathway selection, and adapting model complexity in response to the innate structure of the data. We integrate the DSL into the SoundStream architecture and demonstrate that by routing up to 80% of samples through a lightweight pass we achieve a 12.3x reduction in the amount of computation performed and a 20.9x reduction in model size. This reduces the on-device inference latency by up to 26.5% and improves power efficiency by up to 21.4% without impacting model performance.
Gated Compression Layers for Efficient Always-On Models
Mar 15, 2023



Mobile and embedded machine learning developers frequently have to compromise between two inferior on-device deployment strategies: sacrifice accuracy and aggressively shrink their models to run on dedicated low-power cores; or sacrifice battery by running larger models on more powerful compute cores such as neural processing units or the main application processor. In this paper, we propose a novel Gated Compression layer that can be applied to transform existing neural network architectures into Gated Neural Networks. Gated Neural Networks have multiple properties that excel for on-device use cases that help significantly reduce power, boost accuracy, and take advantage of heterogeneous compute cores. We provide results across five public image and audio datasets that demonstrate the proposed Gated Compression layer effectively stops up to 96% of negative samples, compresses 97% of positive samples, while maintaining or improving model accuracy.