 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User Experience in On-Device Machine Learning with Gated Compression Layers
May 02, 2024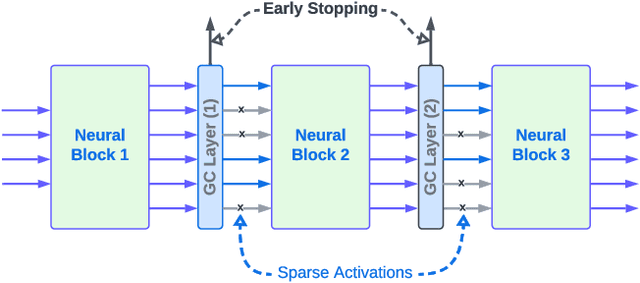
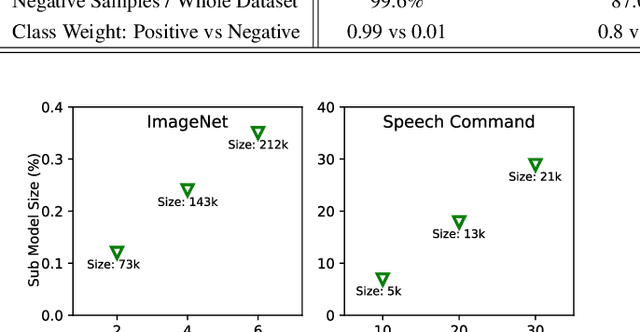
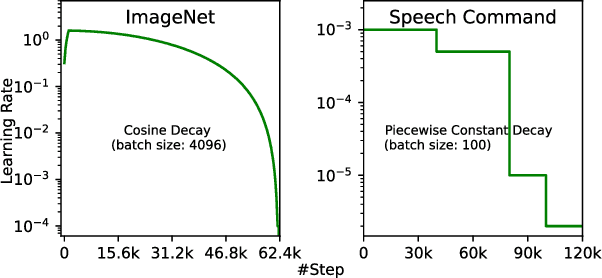
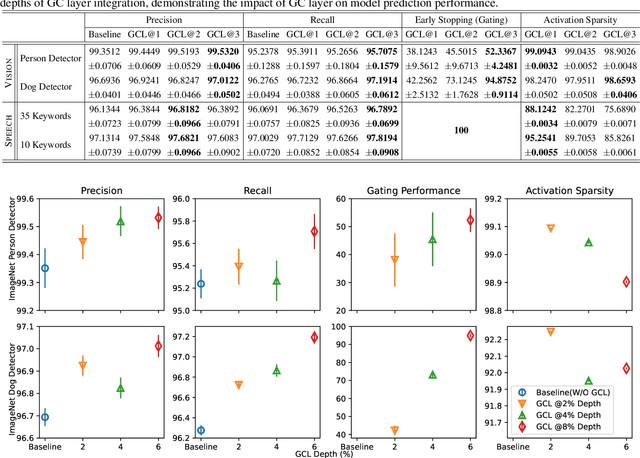
On-device machine learning (ODML) enables powerful edge applications, but power consumption remains a key challenge for resource-constrained devices. To address this, developers often face a trade-off between model accuracy and power consumption, employing either computationally intensive models on high-power cores or pared-down models on low-power cores. Both approaches typically lead to a compromise in user experience (UX). This work focuses on the use of Gated Compression (GC) layer to enhance ODML model performance while conserving power and maximizing cost-efficiency, especially for always-on use cases. GC layers dynamically regulate data flow by selectively gating activations of neurons within the neural network and effectively filtering out non-essential inputs, which reduces power needs without compromising accuracy, and enables more efficient execution on heterogeneous compute cores. These improvements enhance UX through prolonged battery life, improved device responsiveness, and greater user comfort. In this work, we have integrated GC layers into vision and speech domain models including the transformer-based ViT model. Our experiments demonstrate theoretical power efficiency gains ranging from 158x to 30,000x for always-on scenarios. This substantial improvement empowers ODML applications with enhanced UX benefits.
Dynamic Switch Layers For Unsupervised Learning
Apr 05, 2024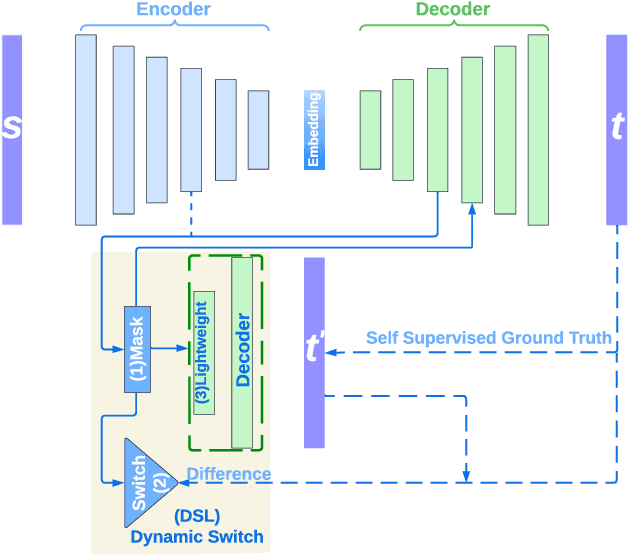
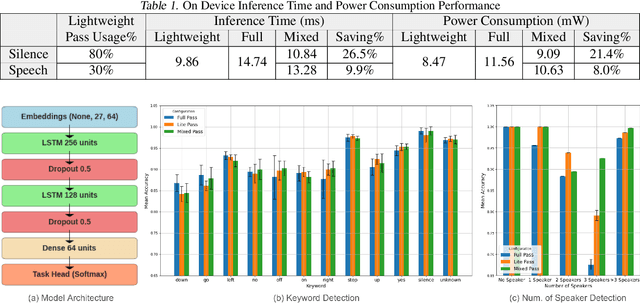
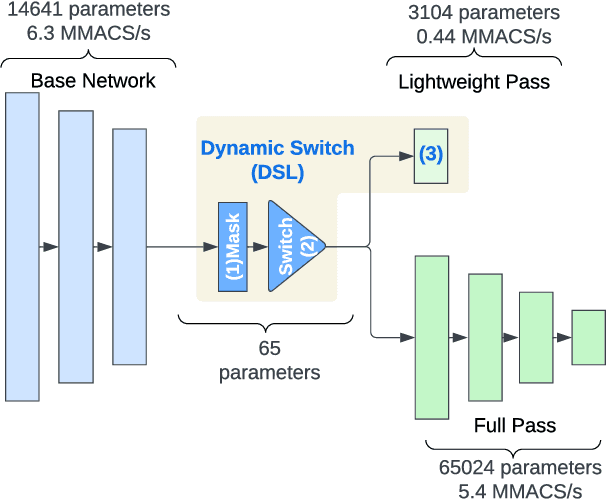
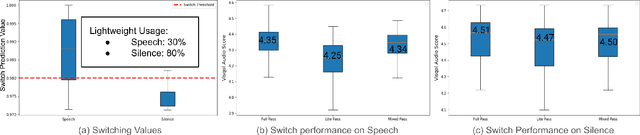
On-device machine learning (ODML) enables intelligent applications on resource-constrained devices. However, power consumption poses a major challenge, forcing a trade-off between model accuracy and power efficiency that often limits model complexity. The previously established Gated Compression (GC) layers offer a solution, enabling power efficiency without sacrificing model performance by selectively gating samples that lack signals of interest. However, their reliance on ground truth labels limits GC layers to supervised tasks. This work introduces the Dynamic Switch Layer (DSL), extending the benefits of GC layers to unsupervised learning scenarios, and maintaining power efficiency without the need for labeled data. The DSL builds upon the GC architecture, leveraging a dynamic pathway selection, and adapting model complexity in response to the innate structure of the data. We integrate the DSL into the SoundStream architecture and demonstrate that by routing up to 80% of samples through a lightweight pass we achieve a 12.3x reduction in the amount of computation performed and a 20.9x reduction in model size. This reduces the on-device inference latency by up to 26.5% and improves power efficiency by up to 21.4% without impacting model performance.
Measuring the Effects of Data Parallelism on Neural Network Training
Nov 21, 2018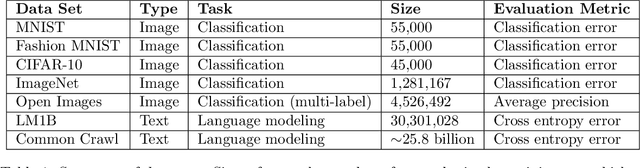
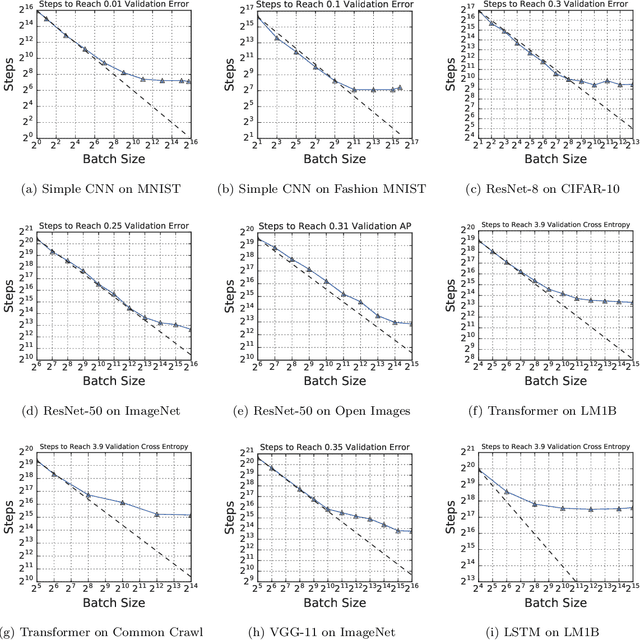
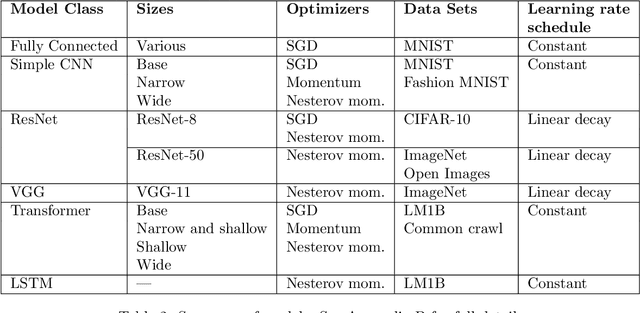
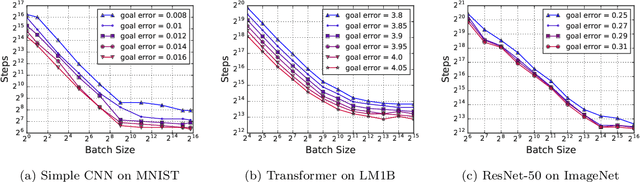
Recent hardware developments have made unprecedented amounts of data parallelism available for accelerating neural network training. Among the simplest ways to harness next-generation accelerators is to increase the batch size in standard mini-batch neural network training algorithms. In this work, we aim to experimentally characterize the effects of increasing the batch size on training time, as measured in the number of steps necessary to reach a goal out-of-sample error. Eventually, increasing the batch size will no longer reduce the number of training steps required, but the exact relationship between the batch size and how many training steps are necessary is of critical importance to practitioners, researchers, and hardware designers alike. We study how this relationship varies with the training algorithm, model, and data set and find extremely large variation between workloads. Along the way, we reconcile disagreements in the literature on whether batch size affects model quality. Finally, we discuss the implications of our results for efforts to train neural networks much faster in the future.