 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity Analysis on Transferred Neural Architectures of BERT and GPT-2 for Financial Sentiment Analysis
Jul 07, 2022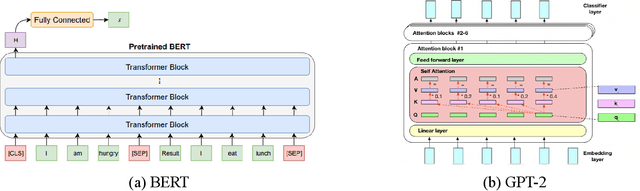



The explosion in novel NLP word embedding and deep learning techniques has induced significant endeavors into potential applications. One of these directions is in the financial sector. Although there is a lot of work done in state-of-the-art models like GPT and BERT, there are relatively few works on how well these methods perform through fine-tuning after being pre-trained, as well as info on how sensitive their parameters are. We investigate the performance and sensitivity of transferred neural architectures from pre-trained GPT-2 and BERT models. We test the fine-tuning performance based on freezing transformer layers, batch size, and learning rate. We find the parameters of BERT are hypersensitive to stochasticity in fine-tuning and that GPT-2 is more stable in such practice. It is also clear that the earlier layers of GPT-2 and BERT contain essential word pattern information that should be maintained.
cMelGAN: An Efficient Conditional Generative Model Based on Mel Spectrograms
May 15, 2022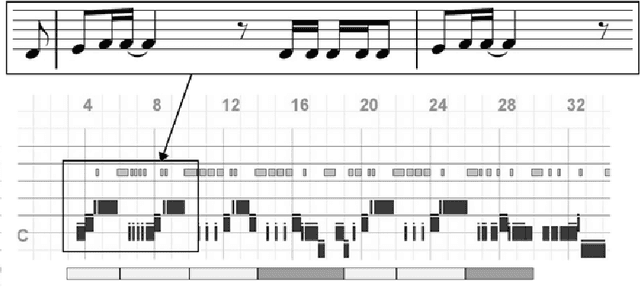
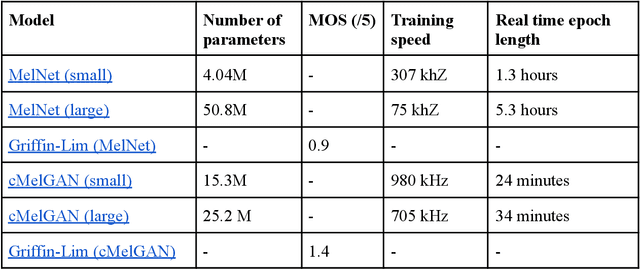

Analysing music in the field of machine learning is a very difficult problem with numerous constraints to consider. The nature of audio data, with its very high dimensionality and widely varying scales of structure, is one of the primary reasons why it is so difficult to model. There are many applications of machine learning in music, like the classifying the mood of a piece of music, conditional music generation, or popularity prediction. The goal for this project was to develop a genre-conditional generative model of music based on Mel spectrograms and evaluate its performance by comparing it to existing generative music models that use note-based representations. We initially implemented an autoregressive, RNN-based generative model called MelNet . However, due to its slow speed and low fidelity output, we decided to create a new, fully convolutional architecture that is based on the MelGAN [4] and conditional GAN architectures, called cMelGAN.