 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity Analysis on Transferred Neural Architectures of BERT and GPT-2 for Financial Sentiment Analysis
Paper and Code
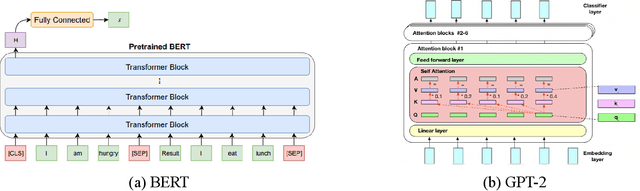



The explosion in novel NLP word embedding and deep learning techniques has induced significant endeavors into potential applications. One of these directions is in the financial sector. Although there is a lot of work done in state-of-the-art models like GPT and BERT, there are relatively few works on how well these methods perform through fine-tuning after being pre-trained, as well as info on how sensitive their parameters are. We investigate the performance and sensitivity of transferred neural architectures from pre-trained GPT-2 and BERT models. We test the fine-tuning performance based on freezing transformer layers, batch size, and learning rate. We find the parameters of BERT are hypersensitive to stochasticity in fine-tuning and that GPT-2 is more stable in such practice. It is also clear that the earlier layers of GPT-2 and BERT contain essential word pattern information that should be maintained.