 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMammographic Breast Positioning Assessment via Deep Learning
Jul 15, 2024



Breast cancer remains a leading cause of cancer-related deaths among women worldwide, with mammography screening as the most effective method for the early detection. Ensuring proper positioning in mammography is critical, as poor positioning can lead to diagnostic errors, increased patient stress, and higher costs due to recalls. Despite advancements in deep learning (DL) for breast cancer diagnostics, limited focus has been given to evaluating mammography positioning. This paper introduces a novel DL methodology to quantitatively assess mammogram positioning quality, specifically in mediolateral oblique (MLO) views using attention and coordinate convolution modules. Our method identifies key anatomical landmarks, such as the nipple and pectoralis muscle, and automatically draws a posterior nipple line (PNL), offering robust and inherently explainable alternative to well-known classification and regression-based approaches. We compare the performance of proposed methodology with various regression and classification-based models. The CoordAtt UNet model achieved the highest accuracy of 88.63% $\pm$ 2.84 and specificity of 90.25% $\pm$ 4.04, along with a noteworthy sensitivity of 86.04% $\pm$ 3.41. In landmark detection, the same model also recorded the lowest mean errors in key anatomical points and the smallest angular error of 2.42 degrees. Our results indicate that models incorporating attention mechanisms and CoordConv module increase the accuracy in classifying breast positioning quality and detecting anatomical landmarks. Furthermore, we make the labels and source codes available to the community to initiate an open research area for mammography, accessible at https://github.com/tanyelai/deep-breast-positioning.
Developing Linguistic Patterns to Mitigate Inherent Human Bias in Offensive Language Detection
Dec 04, 2023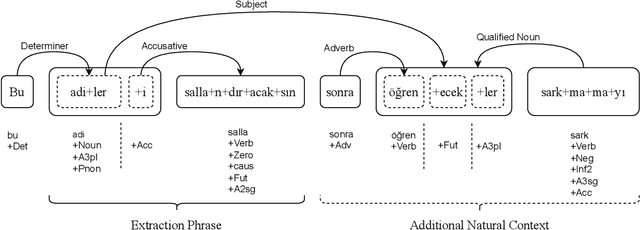



With the proliferation of social media, there has been a sharp increase in offensive content, particularly targeting vulnerable groups, exacerbating social problems such as hatred, racism, and sexism. Detecting offensive language use is crucial to prevent offensive language from being widely shared on social media. However, the accurate detection of irony, implication, and various forms of hate speech on social media remains a challenge. Natural language-based deep learning models require extensive training with large, comprehensive, and labeled datasets. Unfortunately, manually creating such datasets is both costly and error-prone. Additionally, the presence of human-bias in offensive language datasets is a major concern for deep learning models. In this paper, we propose a linguistic data augmentation approach to reduce bias in labeling processes, which aims to mitigate the influence of human bias by leveraging the power of machines to improve the accuracy and fairness of labeling processes. This approach has the potential to improve offensive language classification tasks across multiple languages and reduce the prevalence of offensive content on social media.
Beyond Known Reality: Exploiting Counterfactual Explanations for Medical Research
Jul 28, 2023This study employs counterfactual explanations to explore "what if?" scenarios in medical research, with the aim of expanding our understanding beyond existing boundaries. Specifically, we focus on utilizing MRI features for diagnosing pediatric posterior fossa brain tumors as a case study. The field of artificial intelligence and explainability has witnessed a growing number of studies and increasing scholarly interest. However, the lack of human-friendly interpretations in explaining the outcomes of machine learning algorithms has significantly hindered the acceptance of these methods by clinicians in their clinical practice. To address this, our approach incorporates counterfactual explanations, providing a novel way to examine alternative decision-making scenarios. These explanations offer personalized and context-specific insights, enabling the validation of predictions and clarification of variations under diverse circumstances. Importantly, our approach maintains both statistical and clinical fidelity, allowing for the examination of distinct tumor features through alternative realities. Additionally, we explore the potential use of counterfactuals for data augmentation and evaluate their feasibility as an alternative approach in medical research. The results demonstrate the promising potential of counterfactual explanations to enhance trust and acceptance of AI-driven methods in clinical settings.
Analysis of Perceived Stress Test using Machine Learning
Jun 02, 2023The aim of this study is to determine the perceived stress levels of 150 individuals and analyze the responses given to adapted questions in Turkish using machine learning. The test consists of 14 questions, each scored on a scale of 0 to 4, resulting in a total score range of 0-56. Out of these questions, 7 are formulated in a negative context and scored accordingly, while the remaining 7 are formulated in a positive context and scored in reverse. The test is also designed to identify two sub-factors: perceived self-efficacy and stress/discomfort perception. The main objectives of this research are to demonstrate that test questions may not have equal importance using artificial intelligence techniques, reveal which questions exhibit variations in the society using machine learning, and ultimately demonstrate the existence of distinct patterns observed psychologically. This study provides a different perspective from the existing psychology literature by repeating the test through machine learning. Additionally, it questions the accuracy of the scale used to interpret the results of the perceived stress test and emphasizes the importance of considering differences in the prioritization of test questions. The findings of this study offer new insights into coping strategies and therapeutic approaches in dealing with stress. Source code: https://github.com/toygarr/ppl-r-stressed