 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIPER: Content-Based Table Search via profiling and LLM-Generated Pseudoqueries
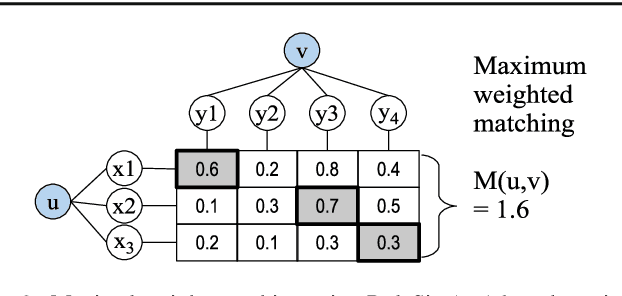
May 18, 2026The rapid growth of tabular datasets in data lakes, data spaces, and open data portals makes effective dataset search essential for reuse and analysis. Existing search systems rely mainly on metadata, which is often incomplete or low quality, especially for tables whose meaning depends on both schema and cell values. Recent advances in Large Language Models (LLMs) enable richer, content-based representations of tables. However, prior LLM-based retrieval methods have focused on Table Question Answering, where the goal is to select a single table to answer a question, rather than retrieve and rank relevant datasets. We propose PIPER, a content-driven retrieval method for tabular datasets that uses table profiles and LLM-generated queries embedded for dense retrieval. Designed for dataset search in poor-metadata settings, PIPER outperforms both classical metadata-based baselines and strong TableQA retrieval methods, demonstrating the value of LLM-based content modeling for tabular dataset search.
Why Neighborhoods Matter: Traversal Context and Provenance in Agentic GraphRAG
May 14, 2026Retrieval-Augmented Generation can improve factuality by grounding answers in external evidence, but Agentic GraphRAG complicates what it means for citations to be faithful. In these systems, an agent explores a knowledge graph before producing an answer and a small set of citations. We frame citation faithfulness as a trajectory-level problem: final citations should not only support the answer, but also account for the graph traversal, structure, and visited-but-uncited entities that may influence it. Through controlled ablation experiments, we compare the effects of isolating, removing, and masking cited and uncited graph entities. Our results show that cited evidence is often necessary, as removing it substantially changes answers and reduces accuracy. However, citations are not sufficient, because accurate answers can also depend on uncited traversal context and surrounding graph structure. These findings suggest that citation evaluation in Agentic GraphRAG should move beyond source support toward provenance over the broader retrieval trajectory.
The Open-Box Fallacy: Why AI Deployment Needs a Calibrated Verification Regime
May 11, 2026AI deployment in sensitive domains such as health care, credit, employment, and criminal justice is often treated as unsafe to authorize until model internals can be explained. This often leads to an excessive reliance on mechanistic interpretability to address a deployment challenge beyond its intended scope. We argue that the gate should instead be calibrated verification: authorization should be domain-scoped, independently checkable, monitored after release, accountable, contestable, and revocable. The reason is twofold. First, model capability is uneven across nearby tasks, so authorization must attach to a specific use rather than to a model in general. Second, societies have long governed opaque expertise through credentials, monitoring, liability, appeal, and revocation rather than mechanism-level explanation. Recent evidence reinforces this distinction between mechanistic understanding and deployment authority: a 53-percentage-point gap between internal representations and output correction shows that understanding may not translate into action, while one scoping review found that only 9.0% of FDA-approved AI/ML device documents contained a prospective post-market surveillance study. We propose Verification Coverage, a six-component reportable standard with a minimum-composition rule, as the metric that should sit beside capability scores in model cards, leaderboards, and regulatory disclosures.
Acceptance Cards:A Four-Diagnostic Standard for Safe Fine-Tuning Defense Claims
May 11, 2026Safe fine-tuning defenses are often endorsed on the basis of a held-out gap reduction, but the same reduction can come from sampling noise, subject artifacts, capability loss, or a mechanism that does not transfer. We introduce Acceptance Cards: an evaluation protocol, a documentation object, an executable audit package, and a claim-specific evidential standard for safe fine-tuning defense claims. The protocol checks statistical reliability, fresh semantic generalization, mechanism alignment, and cross-task transfer before treating a gap reduction as a full-card pass. Re-scored under this installed-gap protocol, SafeLoRA fails the full-card pass on Gemma-2-2B-it: under strict mechanism-class coding it fails all four diagnostics, and under a permissive shrinkage relabel it still fails three of four. This is a narrow installed-gap audit on one model family, not a global judgment of SafeLoRA's effectiveness. In a 46-cell audit, no cell satisfies the strict conjunction. The closest family is a near miss that passes reliability and mechanism checks where the required data are available, but fails the fresh-subject threshold, lacks a strict transfer pass, and carries a measurable deployment-accuracy cost.
CAKE: Cloud Architecture Knowledge Evaluation of Large Language Models
Apr 07, 2026In today's software architecture, large language models (LLMs) serve as software architecture co-pilots. However, no benchmark currently exists to evaluate large language models' actual understanding of cloud-native software architecture. For this reason we present a benchmark called CAKE, which consists of 188 expert-validated questions covering four cognitive levels of Bloom's revised taxonomy -- recall, analyze, design, and implement -- and five cloud-native topics. Evaluation is conducted on 22 model configurations (0.5B--70B parameters) across four LLM families, using three-run majority voting for multiple-choice questions (MCQs) and LLM-as-a-judge scoring for free-responses (FR). Based on this evaluation, four notable findings were identified. First, MCQ accuracy plateaus above 3B parameters, with the best model reaching 99.2\%. Second, free-response scores scale steadily across all cognitive levels. Third, the two formats capture different facets of knowledge, as the MCQ accuracy approaches a ceiling while free-responses continue to differentiate models. Finally, reasoning augmentation (+think) improves free-response quality, while tool augmentation (+tool) degrades performance for small models. These results suggest that the evaluation format fundamentally shapes how we measure architectural knowledge in LLMs.
Architecture Without Architects: How AI Coding Agents Shape Software Architecture
Apr 05, 2026AI coding agents select frameworks, scaffold infrastructure, and wire integrations, often in seconds. These are architectural decisions, yet almost no one reviews them as such. We identify five mechanisms by which agents make implicit architectural choices and propose six prompt-architecture coupling patterns that map natural-language prompt features to the infrastructure they require. The patterns range from contingent couplings (structured output validation) that may weaken as models improve to fundamental ones (tool-call orchestration) that persist regardless of model capability. An illustrative demonstration confirms that prompt wording alone produces structurally different systems for the same task. We term the phenomenon vibe architecting, architecture shaped by prompts rather than deliberate design, and outline review practices, decision records, and tooling to bring these hidden decisions under governance.
Developing Linguistic Patterns to Mitigate Inherent Human Bias in Offensive Language Detection
Dec 04, 2023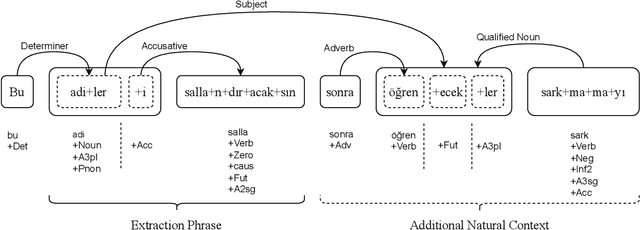



With the proliferation of social media, there has been a sharp increase in offensive content, particularly targeting vulnerable groups, exacerbating social problems such as hatred, racism, and sexism. Detecting offensive language use is crucial to prevent offensive language from being widely shared on social media. However, the accurate detection of irony, implication, and various forms of hate speech on social media remains a challenge. Natural language-based deep learning models require extensive training with large, comprehensive, and labeled datasets. Unfortunately, manually creating such datasets is both costly and error-prone. Additionally, the presence of human-bias in offensive language datasets is a major concern for deep learning models. In this paper, we propose a linguistic data augmentation approach to reduce bias in labeling processes, which aims to mitigate the influence of human bias by leveraging the power of machines to improve the accuracy and fairness of labeling processes. This approach has the potential to improve offensive language classification tasks across multiple languages and reduce the prevalence of offensive content on social media.
Beyond Known Reality: Exploiting Counterfactual Explanations for Medical Research
Jul 28, 2023This study employs counterfactual explanations to explore "what if?" scenarios in medical research, with the aim of expanding our understanding beyond existing boundaries. Specifically, we focus on utilizing MRI features for diagnosing pediatric posterior fossa brain tumors as a case study. The field of artificial intelligence and explainability has witnessed a growing number of studies and increasing scholarly interest. However, the lack of human-friendly interpretations in explaining the outcomes of machine learning algorithms has significantly hindered the acceptance of these methods by clinicians in their clinical practice. To address this, our approach incorporates counterfactual explanations, providing a novel way to examine alternative decision-making scenarios. These explanations offer personalized and context-specific insights, enabling the validation of predictions and clarification of variations under diverse circumstances. Importantly, our approach maintains both statistical and clinical fidelity, allowing for the examination of distinct tumor features through alternative realities. Additionally, we explore the potential use of counterfactuals for data augmentation and evaluate their feasibility as an alternative approach in medical research. The results demonstrate the promising potential of counterfactual explanations to enhance trust and acceptance of AI-driven methods in clinical settings.
Using RDF Summary Graph For Keyword-based Semantic Searches
Jul 12, 2017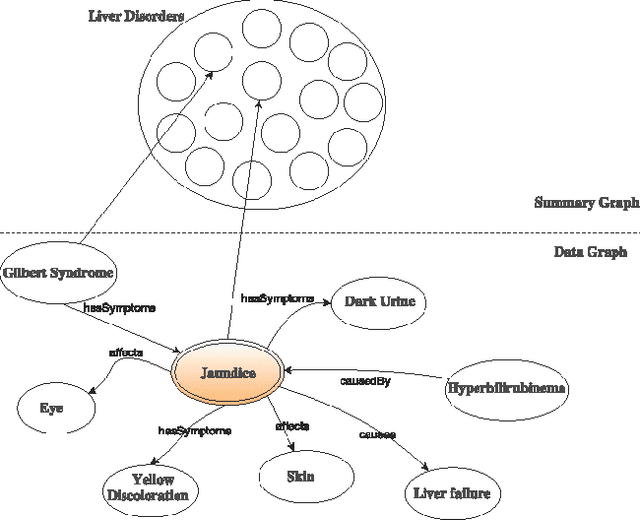
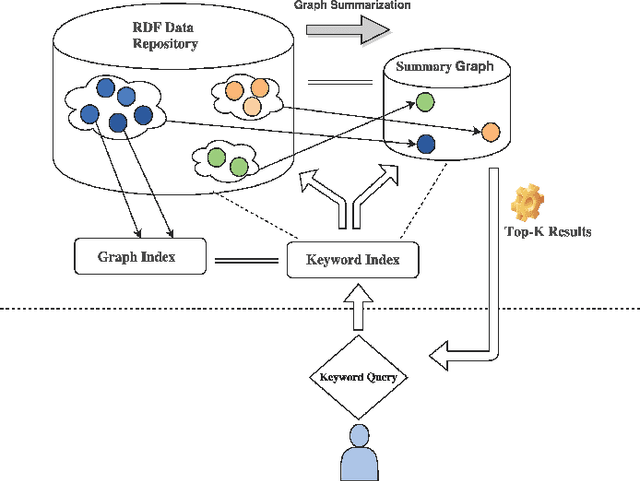
The Semantic Web began to emerge as its standards and technologies developed rapidly in the recent years. The continuing development of Semantic Web technologies has facilitated publishing explicit semantics with data on the Web in RDF data model. This study proposes a semantic search framework to support efficient keyword-based semantic search on RDF data utilizing near neighbor explorations. The framework augments the search results with the resources in close proximity by utilizing the entity type semantics. Along with the search results, the system generates a relevance confidence score measuring the inferred semantic relatedness of returned entities based on the degree of similarity. Furthermore, the evaluations assessing the effectiveness of the framework and the accuracy of the results are presented.
Dynamic Discovery of Type Classes and Relations in Semantic Web Data
May 31, 2017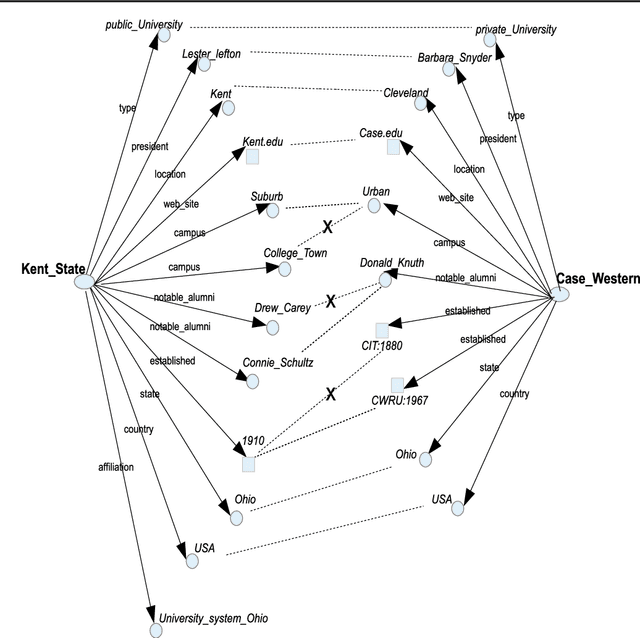


The continuing development of Semantic Web technologies and the increasing user adoption in the recent years have accelerated the progress incorporating explicit semantics with data on the Web. With the rapidly growing RDF (Resource Description Framework) data on the Semantic Web, processing large semantic graph data have become more challenging. Constructing a summary graph structure from the raw RDF can help obtain semantic type relations and reduce the computational complexity for graph processing purposes. In this paper, we addressed the problem of graph summarization in RDF graphs, and we proposed an approach for building summary graph structures automatically from RDF graph data. Moreover, we introduced a measure to help discover optimum class dissimilarity thresholds and an effective method to discover the type classes automatically. In future work, we plan to investigate further improvement options on the scalability of the proposed method.