 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterval-based Prediction Uncertainty Bound Computation in Learning with Missing Values
Mar 01, 2018



The problem of machine learning with missing values is common in many areas. A simple approach is to first construct a dataset without missing values simply by discarding instances with missing entries or by imputing a fixed value for each missing entry, and then train a prediction model with the new dataset. A drawback of this naive approach is that the uncertainty in the missing entries is not properly incorporated in the prediction. In order to evaluate prediction uncertainty, the multiple imputation (MI) approach has been studied, but the performance of MI is sensitive to the choice of the probabilistic model of the true values in the missing entries, and the computational cost of MI is high because multiple models must be trained. In this paper, we propose an alternative approach called the Interval-based Prediction Uncertainty Bounding (IPUB) method. The IPUB method represents the uncertainties due to missing entries as intervals, and efficiently computes the lower and upper bounds of the prediction results when all possible training sets constructed by imputing arbitrary values in the intervals are considered. The IPUB method can be applied to a wide class of convex learning algorithms including penalized least-squares regression, support vector machine (SVM), and logistic regression. We demonstrate the advantages of the IPUB method by comparing it with an existing method in numerical experiment with benchmark datasets.
Secure Approximation Guarantee for Cryptographically Private Empirical Risk Minimization
Feb 15, 2016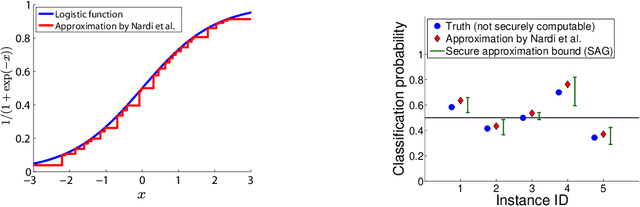



Privacy concern has been increasingly important in many machine learning (ML) problems. We study empirical risk minimization (ERM) problems under secure multi-party computation (MPC) frameworks. Main technical tools for MPC have been developed based on cryptography. One of limitations in current cryptographically private ML is that it is computationally intractable to evaluate non-linear functions such as logarithmic functions or exponential functions. Therefore, for a class of ERM problems such as logistic regression in which non-linear function evaluations are required, one can only obtain approximate solutions. In this paper, we introduce a novel cryptographically private tool called secure approximation guarantee (SAG) method. The key property of SAG method is that, given an arbitrary approximate solution, it can provide a non-probabilistic assumption-free bound on the approximation quality under cryptographically secure computation framework. We demonstrate the benefit of the SAG method by applying it to several problems including a practical privacy-preserving data analysis task on genomic and clinical information.